 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLink-Aware Energy-Frugal Continual Learning for Fault Detection in IoT Networks
Dec 15, 2025The use of lightweight machine learning (ML) models in internet of things (IoT) networks enables resource constrained IoT devices to perform on-device inference for several critical applications. However, the inference accuracy deteriorates due to the non-stationarity in the IoT environment and limited initial training data. To counteract this, the deployed models can be updated occasionally with new observed data samples. However, this approach consumes additional energy, which is undesirable for energy constrained IoT devices. This letter introduces an event-driven communication framework that strategically integrates continual learning (CL) in IoT networks for energy-efficient fault detection. Our framework enables the IoT device and the edge server (ES) to collaboratively update the lightweight ML model by adapting to the wireless link conditions for communication and the available energy budget. Evaluation on real-world datasets show that the proposed approach can outperform both periodic sampling and non-adaptive CL in terms of inference recall; our proposed approach achieves up to a 42.8% improvement, even under tight energy and bandwidth constraint.
Multi-User Beamforming with Deep Reinforcement Learning in Sensing-Aided Communication
May 09, 2025Mobile users are prone to experience beam failure due to beam drifting in millimeter wave (mmWave) communications. Sensing can help alleviate beam drifting with timely beam changes and low overhead since it does not need user feedback. This work studies the problem of optimizing sensing-aided communication by dynamically managing beams allocated to mobile users. A multi-beam scheme is introduced, which allocates multiple beams to the users that need an update on the angle of departure (AoD) estimates and a single beam to the users that have satisfied AoD estimation precision. A deep reinforcement learning (DRL) assisted method is developed to optimize the beam allocation policy, relying only upon the sensing echoes. For comparison, a heuristic AoD-based method using approximated Cram\'er-Rao lower bound (CRLB) for allocation is also presented. Both methods require neither user feedback nor prior state evolution information. Results show that the DRL-assisted method achieves a considerable gain in throughput than the conventional beam sweeping method and the AoD-based method, and it is robust to different user speeds.
One-Bit Sigma-Delta DFRC Waveform Design: Using Quantization Noise for Radar Probing
Jan 27, 2025

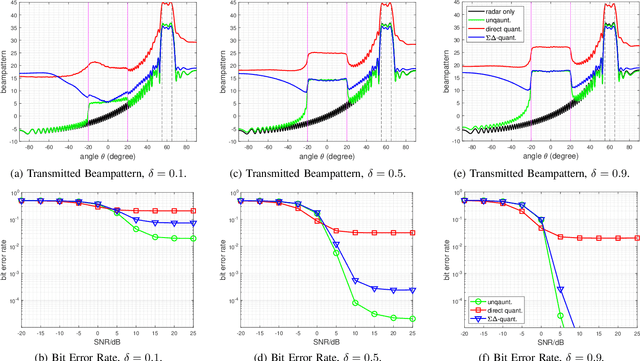

Dual-functional radar-communication (DFRC) signal design has received much attention lately. We consider the scenario of one-bit massive multi-input multi-output (MIMO) wherein one-bit DACs are employed for the sake of saving hardware costs. Specifically, a spatial Sigma-Delta $(\Sigma\Delta)$ modulation scheme is proposed for one-bit MIMO-DFRC waveform design. Unlike the existing approaches which require large-scale binary optimization, the proposed scheme performs $\Sigma\Delta$ modulation on a continuous-valued DFRC signal. The subsequent waveform design is formulated as a constrained least square problem, which can be efficiently solved. Moreover, we leverage quantization noise for radar probing purposes, rather than treating it as unwanted noise. Numerical results demonstrate that the proposed scheme performs well in both radar probing and downlink precoding.
TIMA: Text-Image Mutual Awareness for Balancing Zero-Shot Adversarial Robustness and Generalization Ability
May 27, 2024



This work addresses the challenge of achieving zero-shot adversarial robustness while preserving zero-shot generalization in large-scale foundation models, with a focus on the popular Contrastive Language-Image Pre-training (CLIP). Although foundation models were reported to have exceptional zero-shot generalization, they are highly vulnerable to adversarial perturbations. Existing methods achieve a comparable good tradeoff between zero-shot adversarial robustness and generalization under small adversarial perturbations. However, they fail to achieve a good tradeoff under large adversarial perturbations. To this end, we propose a novel Text-Image Mutual Awareness (TIMA) method that strikes a balance between zero-shot adversarial robustness and generalization. More precisely, we propose an Image-Aware Text (IAT) tuning mechanism that increases the inter-class distance of text embeddings by incorporating the Minimum Hyperspherical Energy (MHE). Simultaneously, fixed pre-trained image embeddings are used as cross-modal auxiliary supervision to maintain the similarity between the MHE-tuned and original text embeddings by the knowledge distillation, preserving semantic information between different classes. Besides, we introduce a Text-Aware Image (TAI) tuning mechanism, which increases inter-class distance between image embeddings during the training stage by Text-distance based Adaptive Margin (TAM). Similarly, a knowledge distillation is utilized to retain the similarity between fine-tuned and pre-trained image embeddings. Extensive experimental results demonstrate the effectiveness of our approach, showing impressive zero-shot performance against a wide range of adversarial perturbations while preserving the zero-shot generalization capabilities of the original CLIP model.
Transmitting Data Through Reconfigurable Intelligent Surface: A Spatial Sigma-Delta Modulation Approach
Oct 25, 2023



Transmitting data using the phases on reconfigurable intelligent surfaces (RIS) is a promising solution for future energy-efficient communication systems. Recent work showed that a virtual phased massive multiuser multiple-input-multiple-out (MIMO) transmitter can be formed using only one active antenna and a large passive RIS. In this paper, we are interested in using such a system to perform MIMO downlink precoding. In this context, we may not be able to apply conventional MIMO precoding schemes, such as the simple zero-forcing (ZF) scheme, and we typically need to design the phase signals by solving optimization problems with constant modulus constraints or with discrete phase constraints, which pose challenges with high computational complexities. In this work, we propose an alternative approach based on Sigma-Delta ($\Sigma\Delta$) modulation, which is classically famous for its noise-shaping ability. Specifically, first-order $\Sigma\Delta$ modulation is applied in the spatial domain to handle phase quantization in generating constant envelope signals. Under some mild assumptions, the proposed phased $\Sigma\Delta$ modulator allows us to use the ZF scheme to synthesize the RIS reflection phases with negligible complexity. The proposed approach is empirically shown to achieve comparable bit error rate performance to the unquantized ZF scheme.
Robust Network Pruning With Sparse Entropic Wasserstein Regression
Oct 07, 2023

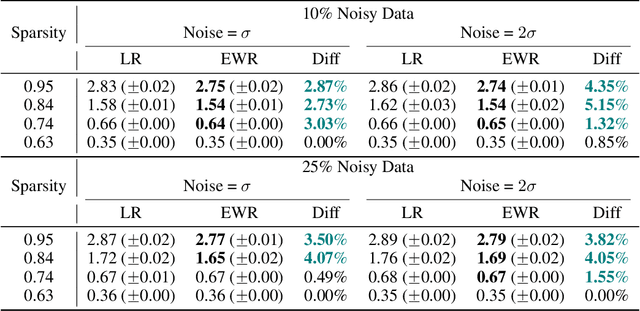

This study unveils a cutting-edge technique for neural network pruning that judiciously addresses noisy gradients during the computation of the empirical Fisher Information Matrix (FIM). We introduce an entropic Wasserstein regression (EWR) formulation, capitalizing on the geometric attributes of the optimal transport (OT) problem. This is analytically showcased to excel in noise mitigation by adopting neighborhood interpolation across data points. The unique strength of the Wasserstein distance is its intrinsic ability to strike a balance between noise reduction and covariance information preservation. Extensive experiments performed on various networks show comparable performance of the proposed method with state-of-the-art (SoTA) network pruning algorithms. Our proposed method outperforms the SoTA when the network size or the target sparsity is large, the gain is even larger with the existence of noisy gradients, possibly from noisy data, analog memory, or adversarial attacks. Notably, our proposed method achieves a gain of 6% improvement in accuracy and 8% improvement in testing loss for MobileNetV1 with less than one-fourth of the network parameters remaining.
Realistic Speech-to-Face Generation with Speech-Conditioned Latent Diffusion Model with Face Prior
Oct 05, 2023Speech-to-face generation is an intriguing area of research that focuses on generating realistic facial images based on a speaker's audio speech. However, state-of-the-art methods employing GAN-based architectures lack stability and cannot generate realistic face images. To fill this gap, we propose a novel speech-to-face generation framework, which leverages a Speech-Conditioned Latent Diffusion Model, called SCLDM. To the best of our knowledge, this is the first work to harness the exceptional modeling capabilities of diffusion models for speech-to-face generation. Preserving the shared identity information between speech and face is crucial in generating realistic results. Therefore, we employ contrastive pre-training for both the speech encoder and the face encoder. This pre-training strategy facilitates effective alignment between the attributes of speech, such as age and gender, and the corresponding facial characteristics in the face images. Furthermore, we tackle the challenge posed by excessive diversity in the synthesis process caused by the diffusion model. To overcome this challenge, we introduce the concept of residuals by integrating a statistical face prior to the diffusion process. This addition helps to eliminate the shared component across the faces and enhances the subtle variations captured by the speech condition. Extensive quantitative, qualitative, and user study experiments demonstrate that our method can produce more realistic face images while preserving the identity of the speaker better than state-of-the-art methods. Highlighting the notable enhancements, our method demonstrates significant gains in all metrics on the AVSpeech dataset and Voxceleb dataset, particularly noteworthy are the improvements of 32.17 and 32.72 on the cosine distance metric for the two datasets, respectively.
NOMA Versus Massive MIMO in Rayleigh Fading
Dec 31, 2021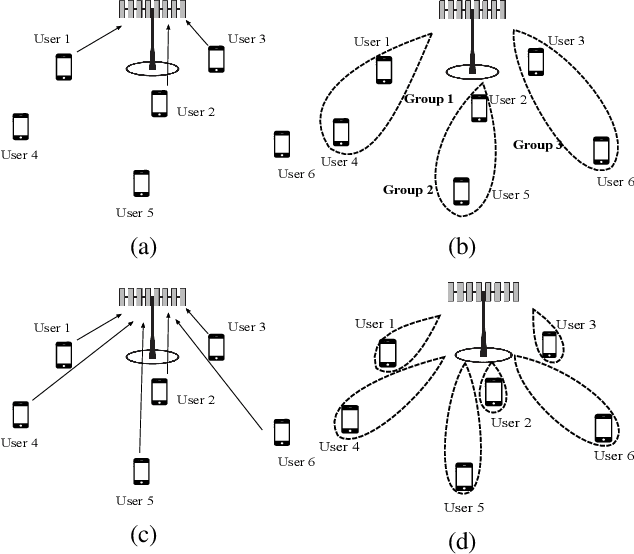
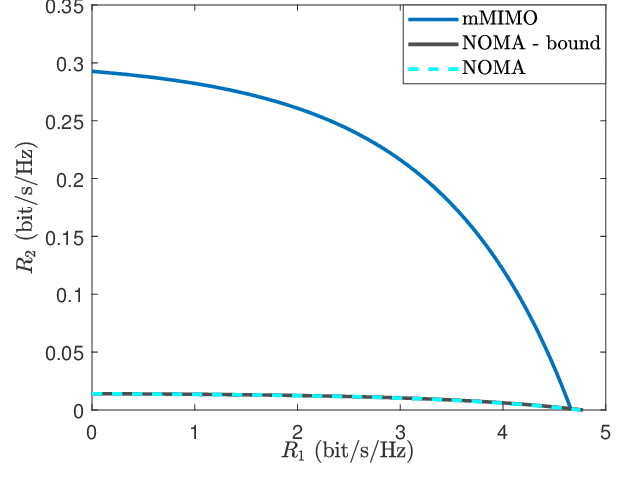
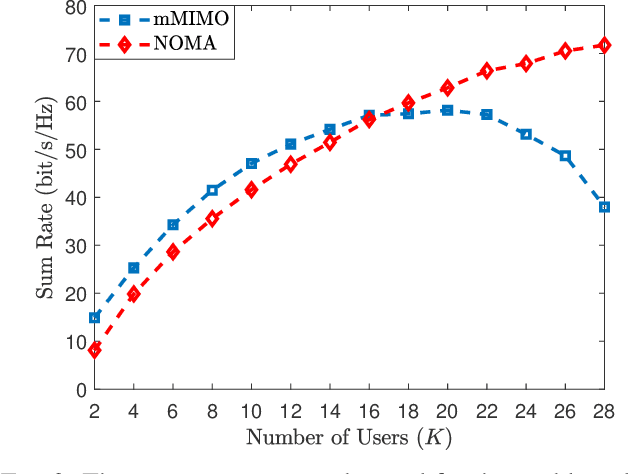
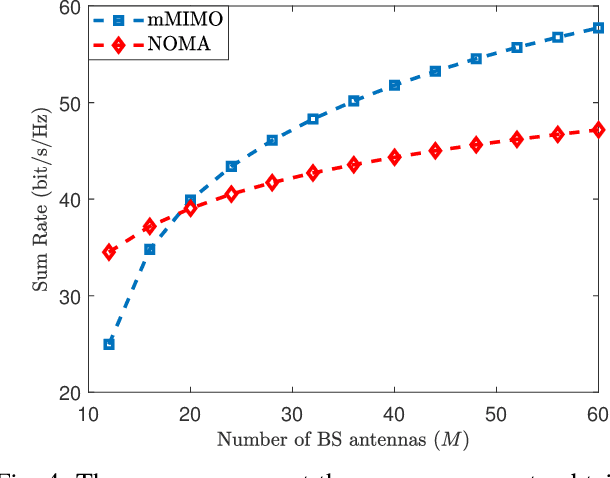
This paper compares the sum rates and rate regions achieved by power-domain NOMA (non-orthogonal multiple access) and standard massive MIMO (multiple-input multiple-output) techniques. We prove analytically that massive MIMO always outperforms NOMA in i.i.d.~Rayleigh fading channels, if a sufficient number of antennas are used at the base stations. The simulation results show that the crossing point occurs already when having 20-30 antennas, which is far less than what is considered for the next generation cellular networks.
Degree-of-Freedom of Modulating Information in the Phases of Reconfigurable Intelligent Surface
Dec 27, 2021



This paper investigates the information theoretical limit of a reconfigurable intelligent surface (RIS) aided communication scenario in which the RIS and the transmitter either jointly or independently send information to the receiver. The RIS is an emerging technology that uses a large number of passive reflective elements with adjustable phases to intelligently reflect the transmit signal to the intended receiver. While most previous studies of the RIS focus on its ability to beamform and to boost the received signal-to-noise ratio (SNR), this paper shows that if the information data stream is also available at the RIS and can be modulated through the adjustable phases at the RIS, significant improvement in the {degree-of-freedom} (DoF) of the overall channel is possible. For example, for an RIS system in which the signals are reflected from a transmitter with $M$ antennas to a receiver with $K$ antennas through an RIS with $N$ reflective elements, assuming no direct path between the transmitter and the receiver, joint transmission of the transmitter and the RIS can achieve a DoF of $\min(M+\frac{N}{2}-\frac{1}{2},N,K)$ as compared to the DoF of $\min(M,K)$ for the conventional multiple-input multiple-output (MIMO) channel. This result is obtained by establishing a connection between the RIS system and the MIMO channel with phase noises and by using results for characterizing the information dimension under projection. The result is further extended to the case with a direct path between the transmitter and the receiver, and also to the multiple access scenario, in which the transmitter and the RIS send independent information. Finally, this paper proposes a symbol-level precoding approach for modulating data through the phases of the RIS, and provides numerical simulation results to verify the theoretical DoF results.
Towards Class-Specific Unit
Nov 22, 2020
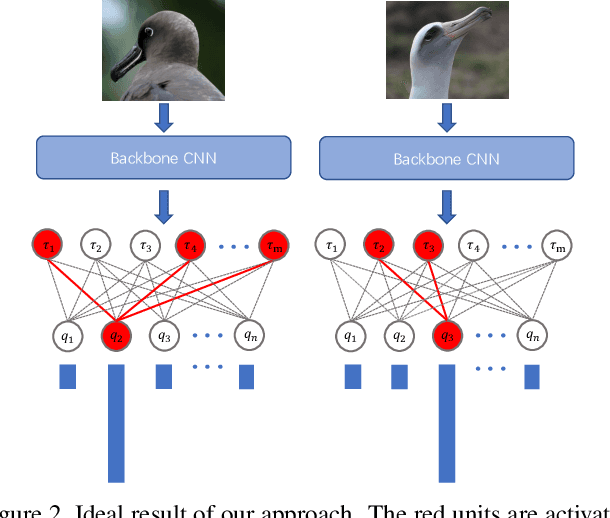

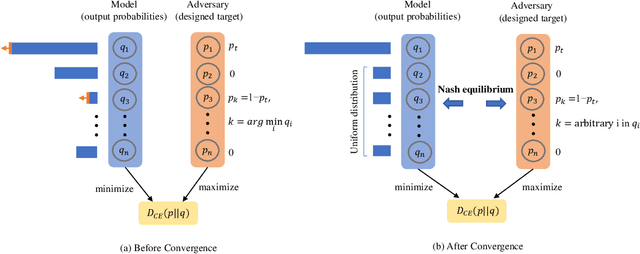
Class selectivity is an attribute of a unit in deep neural networks, which characterizes the discriminative ability of units to a specific class. Intuitively, decisions made by several highly selective units are more interpretable since it is easier to be traced back to the origin while that made by complex combinations of lowly selective units are more difficult to interpret. In this work, we develop a novel way to directly train highly selective units, through which we are able to examine the performance of a network that only rely on highly selective units. Specifically, we train the network such that all the units in the penultimate layer only response to one specific class, which we named as class-specific unit. By innovatively formulating the problem using mutual information, we find that in such a case, the output of the model has a special form that all the probabilities over non-target classes are uniformly distributed. We then propose a minimax loss based on a game theoretic framework to achieve the goal. Nash equilibria are proved to exist and the outcome is consistent with our regularization objective. Experimental results show that the model trained with the proposed objective outperforms models trained with baseline objective among all the tasks we test. Our results shed light on the role of class-specific units by indicating that they can be directly used for decisions without relying on low selective units.