 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Burden Data Augmentation for Dysarthric ASR via Zero-Shot Voice Cloning
Jun 18, 2026Automatic speech recognition remains unreliable for dysarthric speech due to data scarcity and high inter-speaker variability. While synthetic data can address these gaps, traditional methods often require extensive speaker-specific data, reintroducing the collection bottleneck. We investigate zero-shot voice cloning as a low-burden augmentation strategy, using Higgs Audio V2 to clone speakers in the TORGO dataset. We fine-tune (FT) Whisper-medium on cloned, real, and hybrid data and evaluate on held-out real speech. Compared to the zero-shot (31.62%), Clone FT achieved a competitive 26.00% WER, nearly matching the 24.44% and 25.12% seen with Real and Hybrid FT, respectively. Notably, Clone and Hybrid FT outperform Real FT for moderate-severe speakers. Clone FT achieves the best results (11.45% relative) in cross-corpus evaluation on the SAP-1102. These results suggest that zero-shot cloning provides scalable training data that circumvents the costly data collection bottleneck.
Robust Cross-Etiology and Speaker-Independent Dysarthric Speech Recognition
Jan 25, 2025



In this paper, we present a speaker-independent dysarthric speech recognition system, with a focus on evaluating the recently released Speech Accessibility Project (SAP-1005) dataset, which includes speech data from individuals with Parkinson's disease (PD). Despite the growing body of research in dysarthric speech recognition, many existing systems are speaker-dependent and adaptive, limiting their generalizability across different speakers and etiologies. Our primary objective is to develop a robust speaker-independent model capable of accurately recognizing dysarthric speech, irrespective of the speaker. Additionally, as a secondary objective, we aim to test the cross-etiology performance of our model by evaluating it on the TORGO dataset, which contains speech samples from individuals with cerebral palsy (CP) and amyotrophic lateral sclerosis (ALS). By leveraging the Whisper model, our speaker-independent system achieved a CER of 6.99% and a WER of 10.71% on the SAP-1005 dataset. Further, in cross-etiology settings, we achieved a CER of 25.08% and a WER of 39.56% on the TORGO dataset. These results highlight the potential of our approach to generalize across unseen speakers and different etiologies of dysarthria.
Bag of Tricks for Multimodal AutoML with Image, Text, and Tabular Data
Dec 19, 2024



This paper studies the best practices for automatic machine learning (AutoML). While previous AutoML efforts have predominantly focused on unimodal data, the multimodal aspect remains under-explored. Our study delves into classification and regression problems involving flexible combinations of image, text, and tabular data. We curate a benchmark comprising 22 multimodal datasets from diverse real-world applications, encompassing all 4 combinations of the 3 modalities. Across this benchmark, we scrutinize design choices related to multimodal fusion strategies, multimodal data augmentation, converting tabular data into text, cross-modal alignment, and handling missing modalities. Through extensive experimentation and analysis, we distill a collection of effective strategies and consolidate them into a unified pipeline, achieving robust performance on diverse datasets.
AutoGluon-Multimodal (AutoMM): Supercharging Multimodal AutoML with Foundation Models
Apr 30, 2024



AutoGluon-Multimodal (AutoMM) is introduced as an open-source AutoML library designed specifically for multimodal learning. Distinguished by its exceptional ease of use, AutoMM enables fine-tuning of foundation models with just three lines of code. Supporting various modalities including image, text, and tabular data, both independently and in combination, the library offers a comprehensive suite of functionalities spanning classification, regression, object detection, semantic matching, and image segmentation. Experiments across diverse datasets and tasks showcases AutoMM's superior performance in basic classification and regression tasks compared to existing AutoML tools, while also demonstrating competitive results in advanced tasks, aligning with specialized toolboxes designed for such purposes.
Convolution Meets LoRA: Parameter Efficient Finetuning for Segment Anything Model
Jan 31, 2024

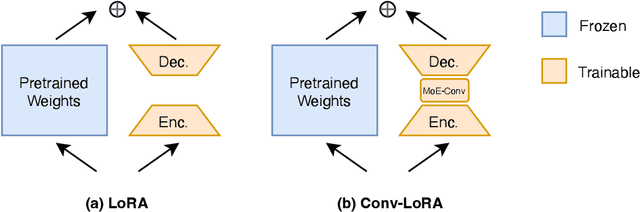

The Segment Anything Model (SAM) stands as a foundational framework for image segmentation. While it exhibits remarkable zero-shot generalization in typical scenarios, its advantage diminishes when applied to specialized domains like medical imagery and remote sensing. To address this limitation, this paper introduces Conv-LoRA, a simple yet effective parameter-efficient fine-tuning approach. By integrating ultra-lightweight convolutional parameters into Low-Rank Adaptation (LoRA), Conv-LoRA can inject image-related inductive biases into the plain ViT encoder, further reinforcing SAM's local prior assumption. Notably, Conv-LoRA not only preserves SAM's extensive segmentation knowledge but also revives its capacity of learning high-level image semantics, which is constrained by SAM's foreground-background segmentation pretraining. Comprehensive experimentation across diverse benchmarks spanning multiple domains underscores Conv-LoRA's superiority in adapting SAM to real-world semantic segmentation tasks.
UniBoost: Unsupervised Unimodal Pre-training for Boosting Zero-shot Vision-Language Tasks
Jun 07, 2023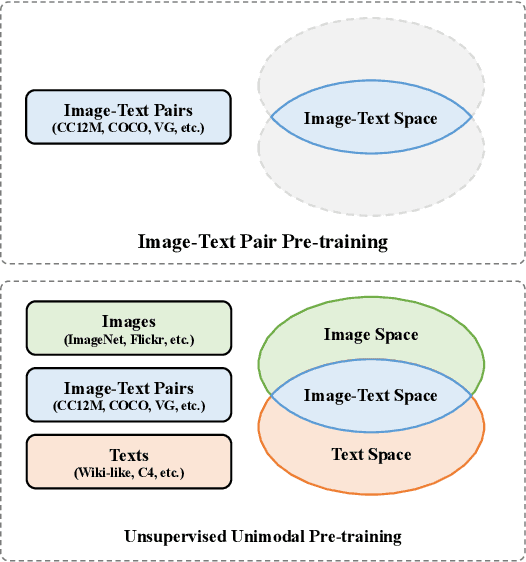
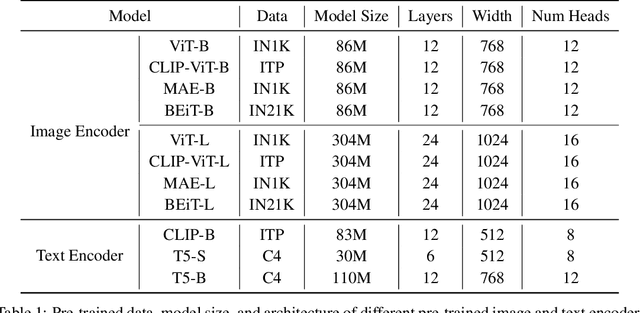
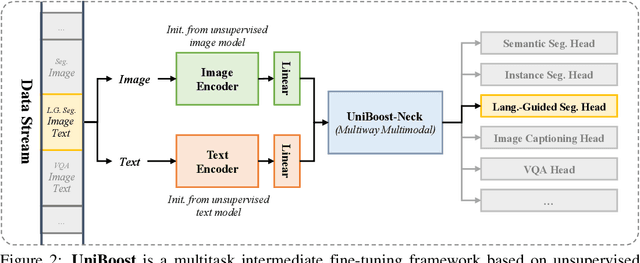
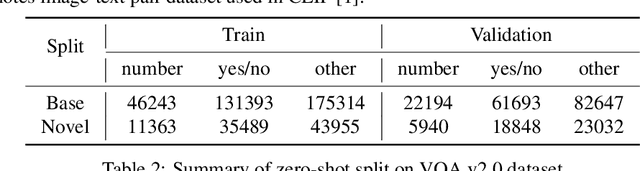
Large-scale joint training of multimodal models, e.g., CLIP, have demonstrated great performance in many vision-language tasks. However, image-text pairs for pre-training are restricted to the intersection of images and texts, limiting their ability to cover a large distribution of real-world data, where noise can also be introduced as misaligned pairs during pre-processing. Conversely, unimodal models trained on text or image data alone through unsupervised techniques can achieve broader coverage of diverse real-world data and are not constrained by the requirement of simultaneous presence of image and text. In this paper, we demonstrate that using large-scale unsupervised unimodal models as pre-training can enhance the zero-shot performance of image-text pair models. Our thorough studies validate that models pre-trained as such can learn rich representations of both modalities, improving their ability to understand how images and text relate to each other. Our experiments show that unimodal pre-training outperforms state-of-the-art CLIP-based models by 6.5% (52.3% $\rightarrow$ 58.8%) on PASCAL-5$^i$ and 6.2% (27.2% $\rightarrow$ 33.4%) on COCO-20$^i$ semantic segmentation under zero-shot setting respectively. By learning representations of both modalities, unimodal pre-training offers broader coverage, reduced misalignment errors, and the ability to capture more complex features and patterns in the real-world data resulting in better performance especially for zero-shot vision-language tasks.
Tailoring Instructions to Student's Learning Levels Boosts Knowledge Distillation
May 16, 2023



It has been commonly observed that a teacher model with superior performance does not necessarily result in a stronger student, highlighting a discrepancy between current teacher training practices and effective knowledge transfer. In order to enhance the guidance of the teacher training process, we introduce the concept of distillation influence to determine the impact of distillation from each training sample on the student's generalization ability. In this paper, we propose Learning Good Teacher Matters (LGTM), an efficient training technique for incorporating distillation influence into the teacher's learning process. By prioritizing samples that are likely to enhance the student's generalization ability, our LGTM outperforms 10 common knowledge distillation baselines on 6 text classification tasks in the GLUE benchmark.
Towards Arbitrary Text-driven Image Manipulation via Space Alignment
Jan 25, 2023The recent GAN inversion methods have been able to successfully invert the real image input to the corresponding editable latent code in StyleGAN. By combining with the language-vision model (CLIP), some text-driven image manipulation methods are proposed. However, these methods require extra costs to perform optimization for a certain image or a new attribute editing mode. To achieve a more efficient editing method, we propose a new Text-driven image Manipulation framework via Space Alignment (TMSA). The Space Alignment module aims to align the same semantic regions in CLIP and StyleGAN spaces. Then, the text input can be directly accessed into the StyleGAN space and be used to find the semantic shift according to the text description. The framework can support arbitrary image editing mode without additional cost. Our work provides the user with an interface to control the attributes of a given image according to text input and get the result in real time. Ex tensive experiments demonstrate our superior performance over prior works.