 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Burden Data Augmentation for Dysarthric ASR via Zero-Shot Voice Cloning
Jun 18, 2026Automatic speech recognition remains unreliable for dysarthric speech due to data scarcity and high inter-speaker variability. While synthetic data can address these gaps, traditional methods often require extensive speaker-specific data, reintroducing the collection bottleneck. We investigate zero-shot voice cloning as a low-burden augmentation strategy, using Higgs Audio V2 to clone speakers in the TORGO dataset. We fine-tune (FT) Whisper-medium on cloned, real, and hybrid data and evaluate on held-out real speech. Compared to the zero-shot (31.62%), Clone FT achieved a competitive 26.00% WER, nearly matching the 24.44% and 25.12% seen with Real and Hybrid FT, respectively. Notably, Clone and Hybrid FT outperform Real FT for moderate-severe speakers. Clone FT achieves the best results (11.45% relative) in cross-corpus evaluation on the SAP-1102. These results suggest that zero-shot cloning provides scalable training data that circumvents the costly data collection bottleneck.
Robust Cross-Etiology and Speaker-Independent Dysarthric Speech Recognition
Jan 25, 2025



In this paper, we present a speaker-independent dysarthric speech recognition system, with a focus on evaluating the recently released Speech Accessibility Project (SAP-1005) dataset, which includes speech data from individuals with Parkinson's disease (PD). Despite the growing body of research in dysarthric speech recognition, many existing systems are speaker-dependent and adaptive, limiting their generalizability across different speakers and etiologies. Our primary objective is to develop a robust speaker-independent model capable of accurately recognizing dysarthric speech, irrespective of the speaker. Additionally, as a secondary objective, we aim to test the cross-etiology performance of our model by evaluating it on the TORGO dataset, which contains speech samples from individuals with cerebral palsy (CP) and amyotrophic lateral sclerosis (ALS). By leveraging the Whisper model, our speaker-independent system achieved a CER of 6.99% and a WER of 10.71% on the SAP-1005 dataset. Further, in cross-etiology settings, we achieved a CER of 25.08% and a WER of 39.56% on the TORGO dataset. These results highlight the potential of our approach to generalize across unseen speakers and different etiologies of dysarthria.
PhasePerturbation: Speech Data Augmentation via Phase Perturbation for Automatic Speech Recognition
Dec 13, 2023Most of the current speech data augmentation methods operate on either the raw waveform or the amplitude spectrum of speech. In this paper, we propose a novel speech data augmentation method called PhasePerturbation that operates dynamically on the phase spectrum of speech. Instead of statically rotating a phase by a constant degree, PhasePerturbation utilizes three dynamic phase spectrum operations, i.e., a randomization operation, a frequency masking operation, and a temporal masking operation, to enhance the diversity of speech data. We conduct experiments on wav2vec2.0 pre-trained ASR models by fine-tuning them with the PhasePerturbation augmented TIMIT corpus. The experimental results demonstrate 10.9\% relative reduction in the word error rate (WER) compared with the baseline model fine-tuned without any augmentation operation. Furthermore, the proposed method achieves additional improvements (12.9\% and 15.9\%) in WER by complementing the Vocal Tract Length Perturbation (VTLP) and the SpecAug, which are both amplitude spectrum-based augmentation methods. The results highlight the capability of PhasePerturbation to improve the current amplitude spectrum-based augmentation methods.
A Novel Self-training Approach for Low-resource Speech Recognition
Aug 10, 2023In this paper, we propose a self-training approach for automatic speech recognition (ASR) for low-resource settings. While self-training approaches have been extensively developed and evaluated for high-resource languages such as English, their applications to low-resource languages like Punjabi have been limited, despite the language being spoken by millions globally. The scarcity of annotated data has hindered the development of accurate ASR systems, especially for low-resource languages (e.g., Punjabi and M\=aori languages). To address this issue, we propose an effective self-training approach that generates highly accurate pseudo-labels for unlabeled low-resource speech. Our experimental analysis demonstrates that our approach significantly improves word error rate, achieving a relative improvement of 14.94% compared to a baseline model across four real speech datasets. Further, our proposed approach reports the best results on the Common Voice Punjabi dataset.
Improved Meta Learning for Low Resource Speech Recognition
May 11, 2022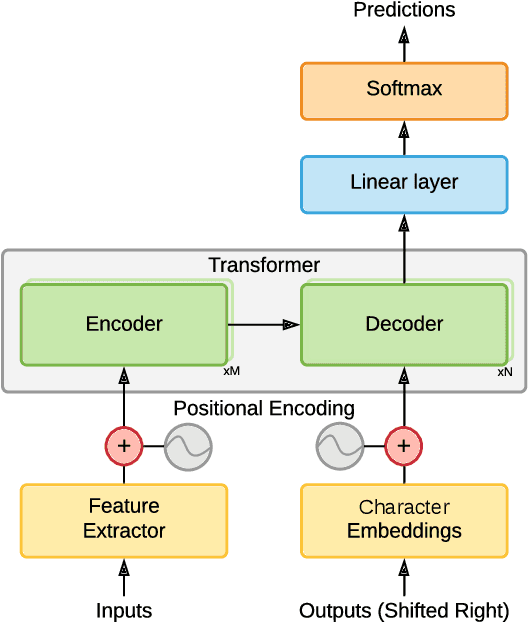
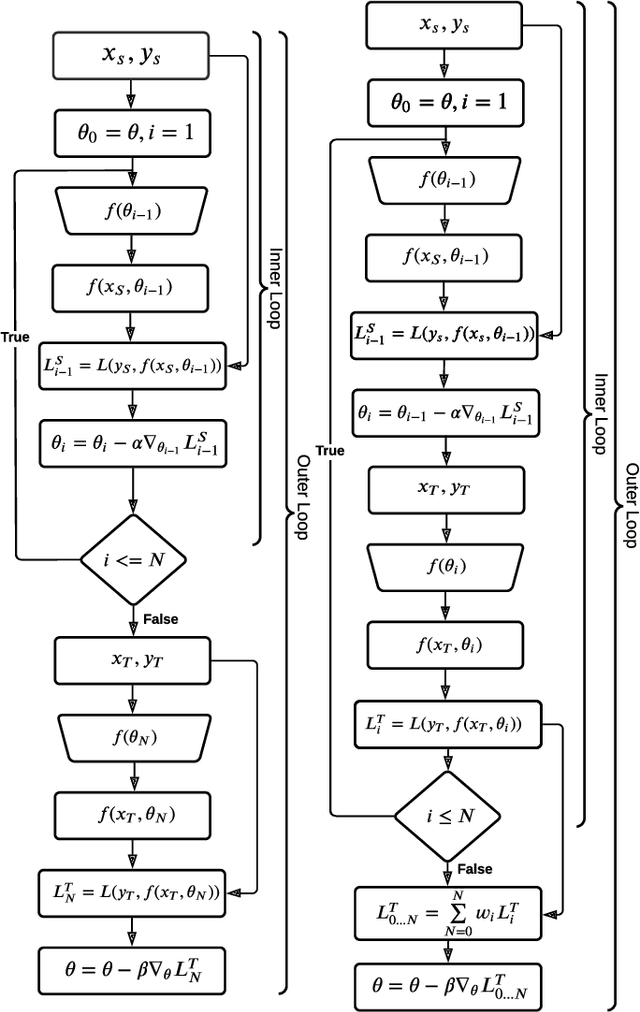

We propose a new meta learning based framework for low resource speech recognition that improves the previous model agnostic meta learning (MAML) approach. The MAML is a simple yet powerful meta learning approach. However, the MAML presents some core deficiencies such as training instabilities and slower convergence speed. To address these issues, we adopt multi-step loss (MSL). The MSL aims to calculate losses at every step of the inner loop of MAML and then combines them with a weighted importance vector. The importance vector ensures that the loss at the last step has more importance than the previous steps. Our empirical evaluation shows that MSL significantly improves the stability of the training procedure and it thus also improves the accuracy of the overall system. Our proposed system outperforms MAML based low resource ASR system on various languages in terms of character error rates and stable training behavior.
* Published in IEEE ICASSP 2022
Towards the Objective Speech Assessment of Smoking Status based on Voice Features: A Review of the Literature
Jun 15, 2021
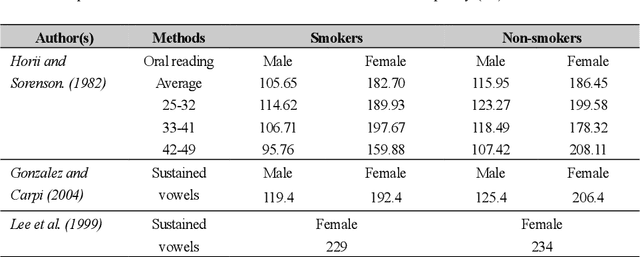
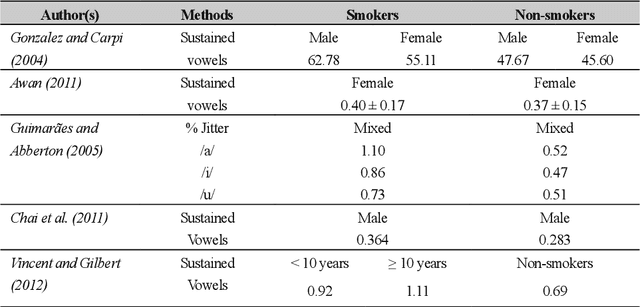
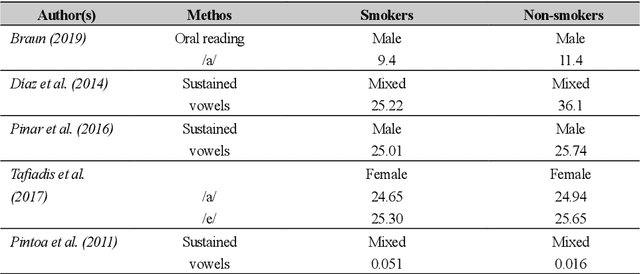
In smoking cessation clinical research and practice, objective validation of self-reported smoking status is crucial for ensuring the reliability of the primary outcome, that is, smoking abstinence. Speech signals convey important information about a speaker, such as age, gender, body size, emotional state, and health state. We investigated (1) if smoking could measurably alter voice features, (2) if smoking cessation could lead to changes in voice, and therefore (3) if the voice-based smoking status assessment has the potential to be used as an objective smoking cessation validation method.
DEEPF0: End-To-End Fundamental Frequency Estimation for Music and Speech Signals
Feb 11, 2021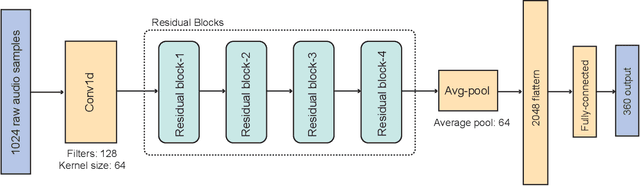
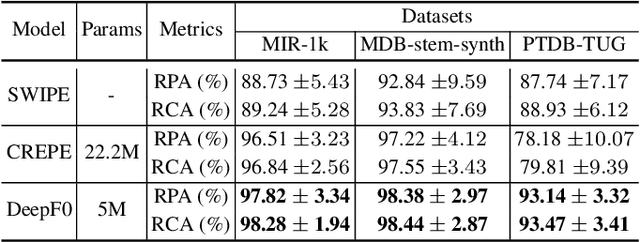
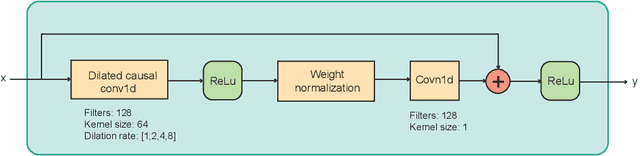
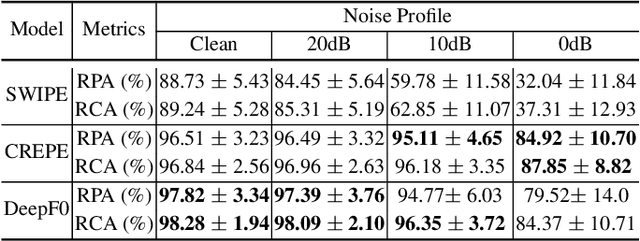
We propose a novel pitch estimation technique called DeepF0, which leverages the available annotated data to directly learns from the raw audio in a data-driven manner. F0 estimation is important in various speech processing and music information retrieval applications. Existing deep learning models for pitch estimations have relatively limited learning capabilities due to their shallow receptive field. The proposed model addresses this issue by extending the receptive field of a network by introducing the dilated convolutional blocks into the network. The dilation factor increases the network receptive field exponentially without increasing the parameters of the model exponentially. To make the training process more efficient and faster, DeepF0 is augmented with residual blocks with residual connections. Our empirical evaluation demonstrates that the proposed model outperforms the baselines in terms of raw pitch accuracy and raw chroma accuracy even using 77.4% fewer network parameters. We also show that our model can capture reasonably well pitch estimation even under the various levels of accompaniment noise.