 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSARM2: Multi-Task Stage Aware Reward Modeling for Self Improving Robotic Manipulation
Jun 09, 2026Fine-tuning vision-language-action (VLA) policies for long-horizon manipulation still relies heavily on behavior cloning, which requires costly high-quality demonstrations and keeps policies near the demonstration distribution. Reward models can reduce this dependence by reweighting demonstrations and providing dense supervision for on-robot reinforcement learning (RL), but they must be dense, accurate, and general. Existing methods fall short: task-specific stage-aware models are accurate but require per-task annotations, while general vision-language-model (VLM) reward models are broadly applicable but too coarse for fine-grained long-horizon progress. We introduce RM, a multi-task stage-aware reward model that combines an action-primitive-based stage estimator with a multi-gate Mixture-of-Experts (MMoE) value head to produce dense per-step rewards across manipulation tasks. Building on RM, we further propose SPIRAL (Self-Policy Improvement via Reward-Aligned Learning), an on-policy reward-guided framework that improves VLA policies from cheap autonomous rollouts. On a 10-task benchmark, RM reduces value-estimation MSE by 80% over the strongest baselines; when used in SPIRAL, it improves task success from around 50% to near-perfect performance on Folding Shorts (58% to 100%) and Cleaning Whiteboard (50% to 90%), showing that high-quality dense rewards are key to a stable robot data flywheel. Project website: https://qianzhong-chen.github.io/sarm2.github.io/.
Breaking Lock-In: Preserving Steerability under Low-Data VLA Post-Training
Apr 25, 2026Have you ever post-trained a generalist vision-language-action (VLA) policy on a small demonstration dataset, only to find that it stops responding to new instructions and is limited to behaviors observed during post-training? We identify this phenomenon as lock-in: after low-data, supervised fine-tuning (SFT), the policy becomes overly specialized to the post-training data and fails to generalize to novel instructions, manifesting as concept lock-in (fixation on training objects/attributes) and spatial lock-in (fixation on training spatial targets). Many existing remedies introduce additional supervision signals, such as those derived from foundation models or auxiliary objectives, or rely on augmented datasets to recover generalization. In this paper, we show that the policy's internal pre-trained knowledge is sufficient: DeLock mitigates lock-in by preserving visual grounding during post-training and applying test-time contrastive prompt guidance to steer the policy's denoising dynamics according to novel instructions. Across eight simulation and real-world evaluations, DeLock consistently outperforms strong baselines and matches or exceeds the performance of a state-of-the-art generalist policy post-trained with substantially more curated demonstrations.
MoE-DP: An MoE-Enhanced Diffusion Policy for Robust Long-Horizon Robotic Manipulation with Skill Decomposition and Failure Recovery
Nov 07, 2025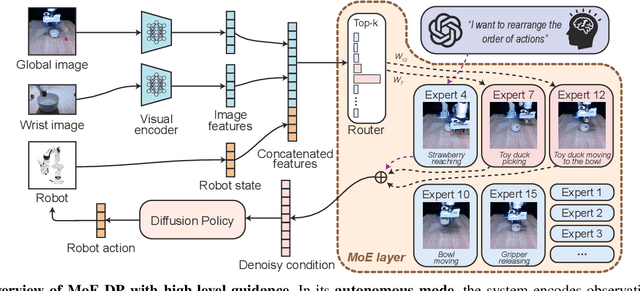
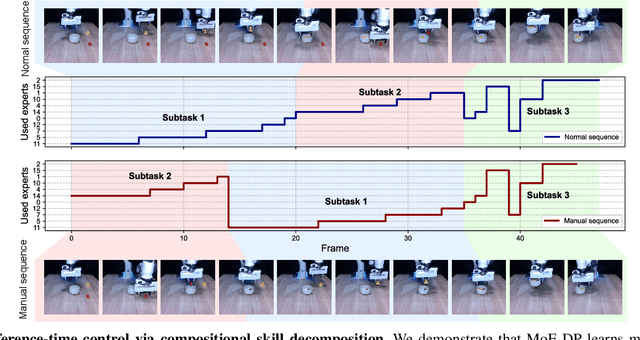
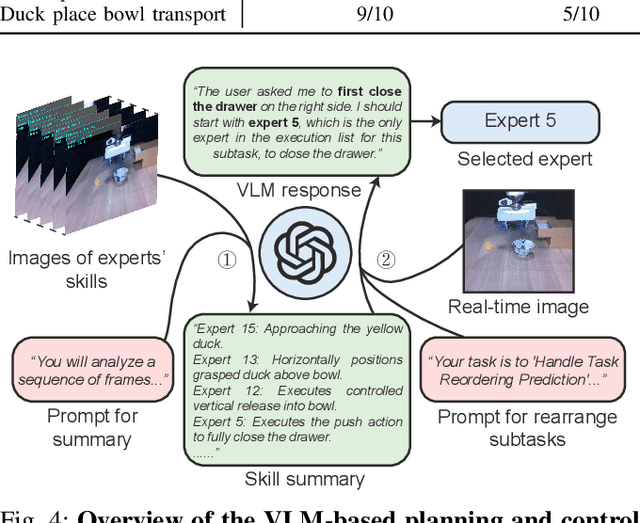
Diffusion policies have emerged as a powerful framework for robotic visuomotor control, yet they often lack the robustness to recover from subtask failures in long-horizon, multi-stage tasks and their learned representations of observations are often difficult to interpret. In this work, we propose the Mixture of Experts-Enhanced Diffusion Policy (MoE-DP), where the core idea is to insert a Mixture of Experts (MoE) layer between the visual encoder and the diffusion model. This layer decomposes the policy's knowledge into a set of specialized experts, which are dynamically activated to handle different phases of a task. We demonstrate through extensive experiments that MoE-DP exhibits a strong capability to recover from disturbances, significantly outperforming standard baselines in robustness. On a suite of 6 long-horizon simulation tasks, this leads to a 36% average relative improvement in success rate under disturbed conditions. This enhanced robustness is further validated in the real world, where MoE-DP also shows significant performance gains. We further show that MoE-DP learns an interpretable skill decomposition, where distinct experts correspond to semantic task primitives (e.g., approaching, grasping). This learned structure can be leveraged for inference-time control, allowing for the rearrangement of subtasks without any re-training.Our video and code are available at the https://moe-dp-website.github.io/MoE-DP-Website/.
MENTOR: Mixture-of-Experts Network with Task-Oriented Perturbation for Visual Reinforcement Learning
Oct 19, 2024
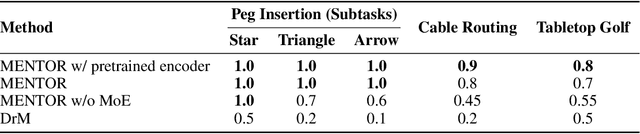
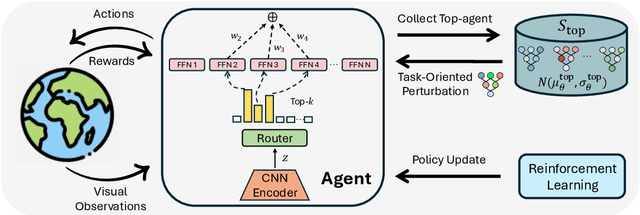
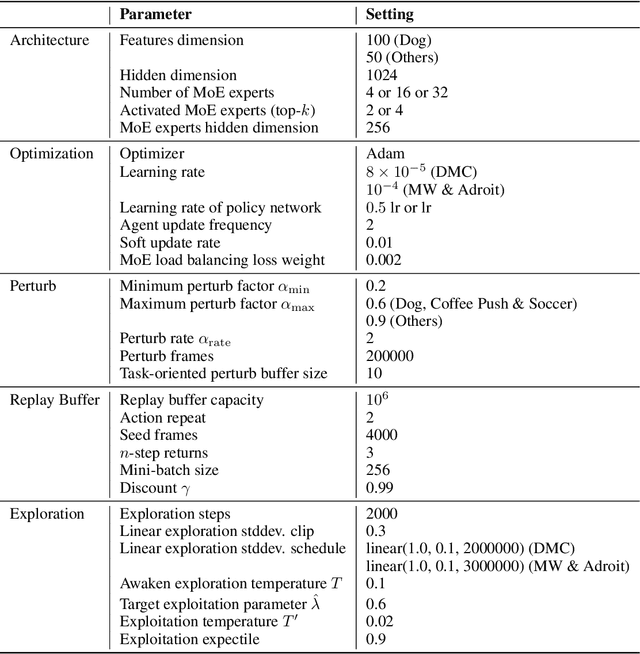
Visual deep reinforcement learning (RL) enables robots to acquire skills from visual input for unstructured tasks. However, current algorithms suffer from low sample efficiency, limiting their practical applicability. In this work, we present MENTOR, a method that improves both the architecture and optimization of RL agents. Specifically, MENTOR replaces the standard multi-layer perceptron (MLP) with a mixture-of-experts (MoE) backbone, enhancing the agent's ability to handle complex tasks by leveraging modular expert learning to avoid gradient conflicts. Furthermore, MENTOR introduces a task-oriented perturbation mechanism, which heuristically samples perturbation candidates containing task-relevant information, leading to more targeted and effective optimization. MENTOR outperforms state-of-the-art methods across three simulation domains -- DeepMind Control Suite, Meta-World, and Adroit. Additionally, MENTOR achieves an average of 83% success rate on three challenging real-world robotic manipulation tasks including peg insertion, cable routing, and tabletop golf, which significantly surpasses the success rate of 32% from the current strongest model-free visual RL algorithm. These results underscore the importance of sample efficiency in advancing visual RL for real-world robotics. Experimental videos are available at https://suninghuang19.github.io/mentor_page.
DittoGym: Learning to Control Soft Shape-Shifting Robots
Jan 29, 2024



Robot co-design, where the morphology of a robot is optimized jointly with a learned policy to solve a specific task, is an emerging area of research. It holds particular promise for soft robots, which are amenable to novel manufacturing techniques that can realize learned morphologies and actuators. Inspired by nature and recent novel robot designs, we propose to go a step further and explore the novel reconfigurable robots, defined as robots that can change their morphology within their lifetime. We formalize control of reconfigurable soft robots as a high-dimensional reinforcement learning (RL) problem. We unify morphology change, locomotion, and environment interaction in the same action space, and introduce an appropriate, coarse-to-fine curriculum that enables us to discover policies that accomplish fine-grained control of the resulting robots. We also introduce DittoGym, a comprehensive RL benchmark for reconfigurable soft robots that require fine-grained morphology changes to accomplish the tasks. Finally, we evaluate our proposed coarse-to-fine algorithm on DittoGym and demonstrate robots that learn to change their morphology several times within a sequence, uniquely enabled by our RL algorithm. More results are available at https://dittogym.github.io.