 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentChem: From Textual CoT to Latent Thinking in Chemical Reasoning
Feb 06, 2026Chemical large language models (LLMs) predominantly rely on explicit Chain-of-Thought (CoT) in natural language to perform complex reasoning. However, chemical reasoning is inherently continuous and structural, and forcing it into discrete linguistic tokens introduces a fundamental representation mismatch that constrains both efficiency and performance. We introduce LatentChem, a latent reasoning interface that decouples chemical computation from textual generation, enabling models to perform multi-step reasoning directly in continuous latent space while emitting language only for final outputs. Remarkably, we observe a consistent emergent behavior: when optimized solely for task success, models spontaneously internalize reasoning, progressively abandoning verbose textual derivations in favor of implicit latent computation. This shift is not merely stylistic but computationally advantageous. Across diverse chemical reasoning benchmarks, LatentChem achieves a 59.88\% non-tie win rate over strong CoT-based baselines on ChemCoTBench, while delivering a 10.84$\times$ average inference speedup. Our results provide empirical evidence that chemical reasoning is more naturally and effectively realized as continuous latent dynamics rather than discretized linguistic trajectories.
Guard Me If You Know Me: Protecting Specific Face-Identity from Deepfakes
May 26, 2025



Securing personal identity against deepfake attacks is increasingly critical in the digital age, especially for celebrities and political figures whose faces are easily accessible and frequently targeted. Most existing deepfake detection methods focus on general-purpose scenarios and often ignore the valuable prior knowledge of known facial identities, e.g., "VIP individuals" whose authentic facial data are already available. In this paper, we propose \textbf{VIPGuard}, a unified multimodal framework designed to capture fine-grained and comprehensive facial representations of a given identity, compare them against potentially fake or similar-looking faces, and reason over these comparisons to make accurate and explainable predictions. Specifically, our framework consists of three main stages. First, fine-tune a multimodal large language model (MLLM) to learn detailed and structural facial attributes. Second, we perform identity-level discriminative learning to enable the model to distinguish subtle differences between highly similar faces, including real and fake variations. Finally, we introduce user-specific customization, where we model the unique characteristics of the target face identity and perform semantic reasoning via MLLM to enable personalized and explainable deepfake detection. Our framework shows clear advantages over previous detection works, where traditional detectors mainly rely on low-level visual cues and provide no human-understandable explanations, while other MLLM-based models often lack a detailed understanding of specific face identities. To facilitate the evaluation of our method, we built a comprehensive identity-aware benchmark called \textbf{VIPBench} for personalized deepfake detection, involving the latest 7 face-swapping and 7 entire face synthesis techniques for generation.
Stacking Brick by Brick: Aligned Feature Isolation for Incremental Face Forgery Detection
Nov 19, 2024



The rapid advancement of face forgery techniques has introduced a growing variety of forgeries. Incremental Face Forgery Detection (IFFD), involving gradually adding new forgery data to fine-tune the previously trained model, has been introduced as a promising strategy to deal with evolving forgery methods. However, a naively trained IFFD model is prone to catastrophic forgetting when new forgeries are integrated, as treating all forgeries as a single ''Fake" class in the Real/Fake classification can cause different forgery types overriding one another, thereby resulting in the forgetting of unique characteristics from earlier tasks and limiting the model's effectiveness in learning forgery specificity and generality. In this paper, we propose to stack the latent feature distributions of previous and new tasks brick by brick, $\textit{i.e.}$, achieving $\textbf{aligned feature isolation}$. In this manner, we aim to preserve learned forgery information and accumulate new knowledge by minimizing distribution overriding, thereby mitigating catastrophic forgetting. To achieve this, we first introduce Sparse Uniform Replay (SUR) to obtain the representative subsets that could be treated as the uniformly sparse versions of the previous global distributions. We then propose a Latent-space Incremental Detector (LID) that leverages SUR data to isolate and align distributions. For evaluation, we construct a more advanced and comprehensive benchmark tailored for IFFD. The leading experimental results validate the superiority of our method.
LLaVA-o1: Let Vision Language Models Reason Step-by-Step
Nov 15, 2024



Large language models have demonstrated substantial advancements in reasoning capabilities, particularly through inference-time scaling, as illustrated by models such as OpenAI's o1. However, current Vision-Language Models (VLMs) often struggle to perform systematic and structured reasoning, especially when handling complex visual question-answering tasks. In this work, we introduce LLaVA-o1, a novel VLM designed to conduct autonomous multistage reasoning. Unlike chain-of-thought prompting, LLaVA-o1 independently engages in sequential stages of summarization, visual interpretation, logical reasoning, and conclusion generation. This structured approach enables LLaVA-o1 to achieve marked improvements in precision on reasoning-intensive tasks. To accomplish this, we compile the LLaVA-o1-100k dataset, integrating samples from various visual question answering sources and providing structured reasoning annotations. Besides, we propose an inference-time stage-level beam search method, which enables effective inference-time scaling. Remarkably, with only 100k training samples and a simple yet effective inference time scaling method, LLaVA-o1 not only outperforms its base model by 8.9% on a wide range of multimodal reasoning benchmarks, but also surpasses the performance of larger and even closed-source models, such as Gemini-1.5-pro, GPT-4o-mini, and Llama-3.2-90B-Vision-Instruct.
TaxDiff: Taxonomic-Guided Diffusion Model for Protein Sequence Generation
Feb 27, 2024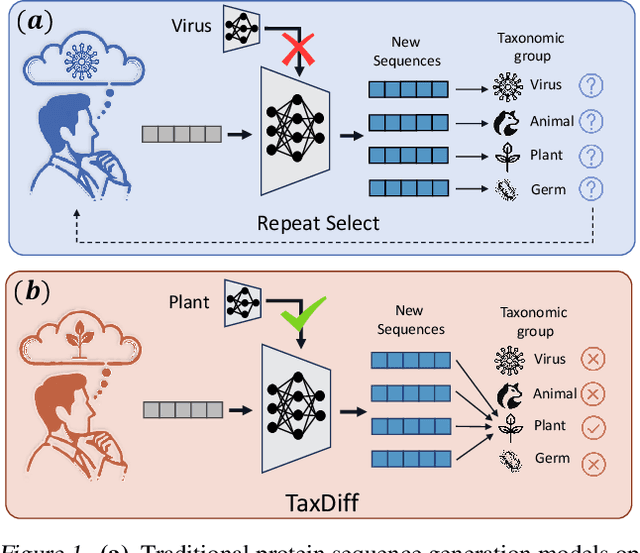
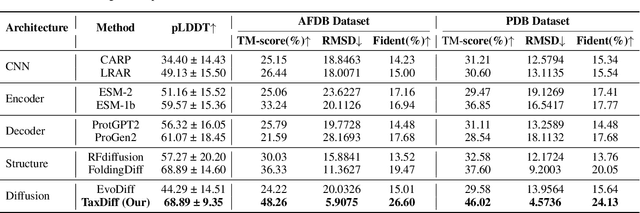
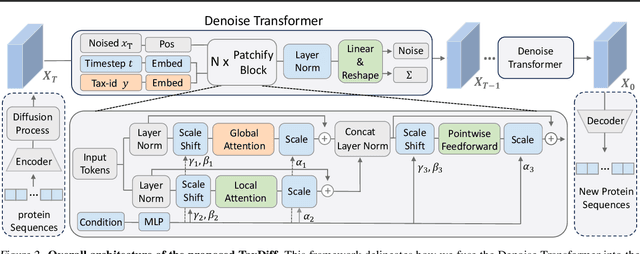

Designing protein sequences with specific biological functions and structural stability is crucial in biology and chemistry. Generative models already demonstrated their capabilities for reliable protein design. However, previous models are limited to the unconditional generation of protein sequences and lack the controllable generation ability that is vital to biological tasks. In this work, we propose TaxDiff, a taxonomic-guided diffusion model for controllable protein sequence generation that combines biological species information with the generative capabilities of diffusion models to generate structurally stable proteins within the sequence space. Specifically, taxonomic control information is inserted into each layer of the transformer block to achieve fine-grained control. The combination of global and local attention ensures the sequence consistency and structural foldability of taxonomic-specific proteins. Extensive experiments demonstrate that TaxDiff can consistently achieve better performance on multiple protein sequence generation benchmarks in both taxonomic-guided controllable generation and unconditional generation. Remarkably, the sequences generated by TaxDiff even surpass those produced by direct-structure-generation models in terms of confidence based on predicted structures and require only a quarter of the time of models based on the diffusion model. The code for generating proteins and training new versions of TaxDiff is available at:https://github.com/Linzy19/TaxDiff.
2nd Place Solution to Google Landmark Retrieval 2021
Oct 08, 2021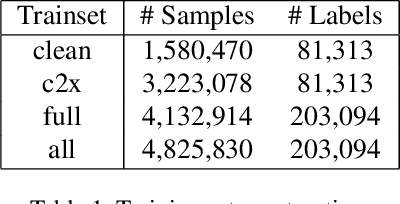
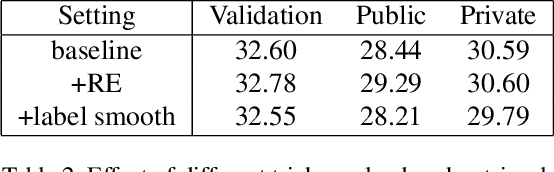
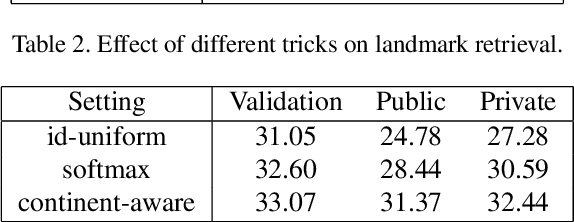
This paper presents the 2nd place solution to the Google Landmark Retrieval 2021 Competition on Kaggle. The solution is based on a baseline with training tricks from person re-identification, a continent-aware sampling strategy is presented to select training images according to their country tags and a Landmark-Country aware reranking is proposed for the retrieval task. With these contributions, we achieve 0.52995 mAP@100 on private leaderboard. Code available at https://github.com/WesleyZhang1991/Google_Landmark_Retrieval_2021_2nd_Place_Solution
A 3D Non-stationary MmWave Channel Model for Vacuum Tube Ultra-High-Speed Train Channels
Feb 09, 2021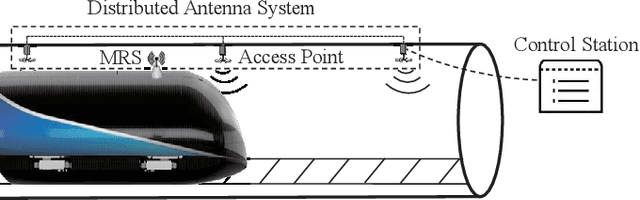
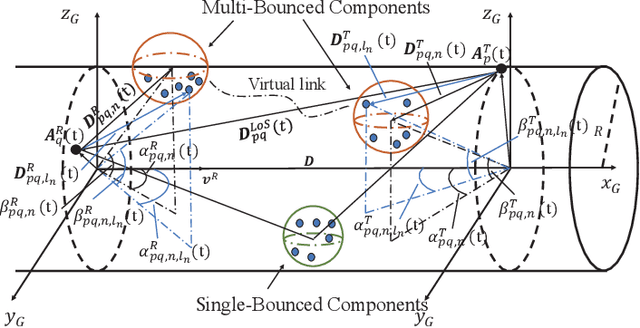
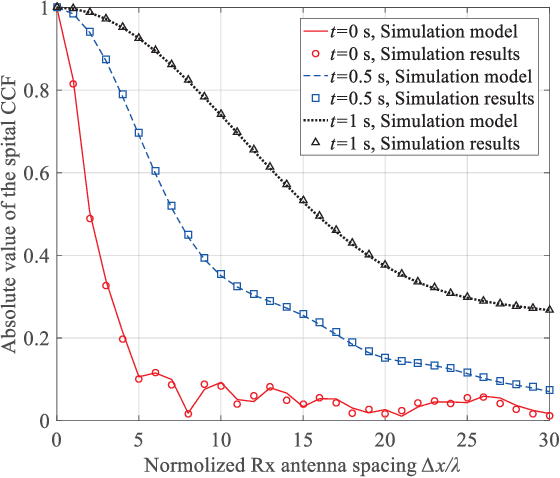
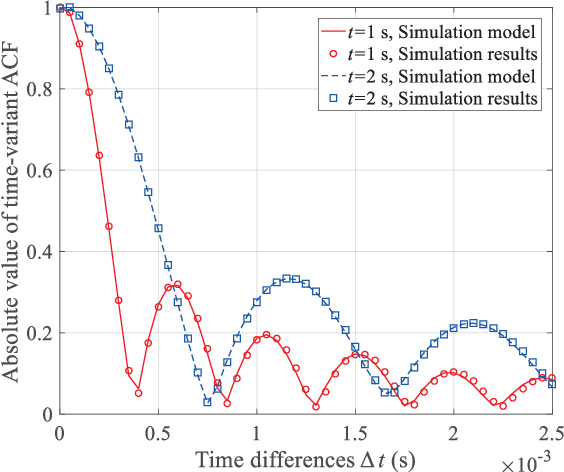
As a potential development direction of future transportation, the vacuum tube ultra-high-speed train (UHST) wireless communication systems have newly different channel characteristics from existing high-speed train (HST) scenarios. In this paper, a three-dimensional non-stationary millimeter wave (mmWave) geometry-based stochastic model (GBSM) is proposed to investigate the channel characteristics of UHST channels in vacuum tube scenarios, taking into account the waveguide effect and the impact of tube wall roughness on channel. Then, based on the proposed model, some important time-variant channel statistical properties are studied and compared with those in existing HST and tunnel channels. The results obtained show that the multipath effect in vacuum tube scenarios will be more obvious than tunnel scenarios but less than existing HST scenarios, which will provide some insights for future research on vacuum tube UHST wireless communications.