 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTutor-Student Reinforcement Learning: A Dynamic Curriculum for Robust Deepfake Detection
Mar 25, 2026Standard supervised training for deepfake detection treats all samples with uniform importance, which can be suboptimal for learning robust and generalizable features. In this work, we propose a novel Tutor-Student Reinforcement Learning (TSRL) framework to dynamically optimize the training curriculum. Our method models the training process as a Markov Decision Process where a ``Tutor'' agent learns to guide a ``Student'' (the deepfake detector). The Tutor, implemented as a Proximal Policy Optimization (PPO) agent, observes a rich state representation for each training sample, encapsulating not only its visual features but also its historical learning dynamics, such as EMA loss and forgetting counts. Based on this state, the Tutor takes an action by assigning a continuous weight (0-1) to the sample's loss, thereby dynamically re-weighting the training batch. The Tutor is rewarded based on the Student's immediate performance change, specifically rewarding transitions from incorrect to correct predictions. This strategy encourages the Tutor to learn a curriculum that prioritizes high-value samples, such as hard-but-learnable examples, leading to a more efficient and effective training process. We demonstrate that this adaptive curriculum improves the Student's generalization capabilities against unseen manipulation techniques compared to traditional training methods. Code is available at https://github.com/wannac1/TSRL.
* Accepted to CVPR 2026
MotionLLaMA: A Unified Framework for Motion Synthesis and Comprehension
Nov 26, 2024
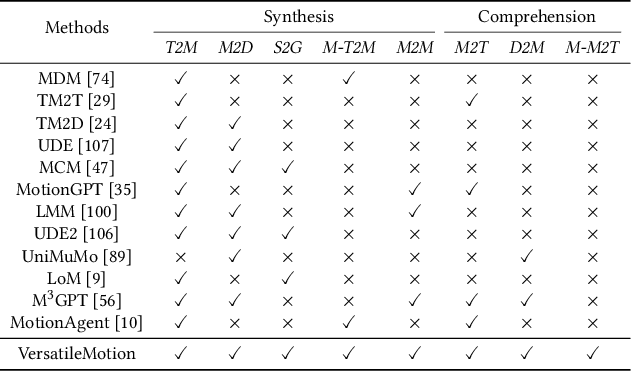
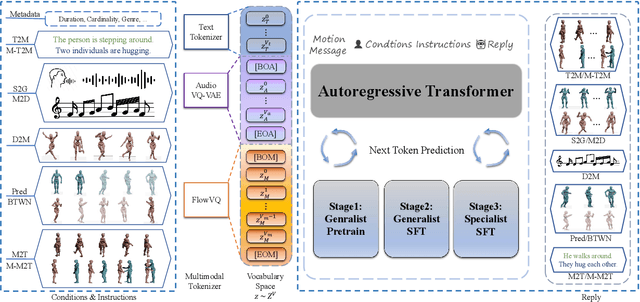
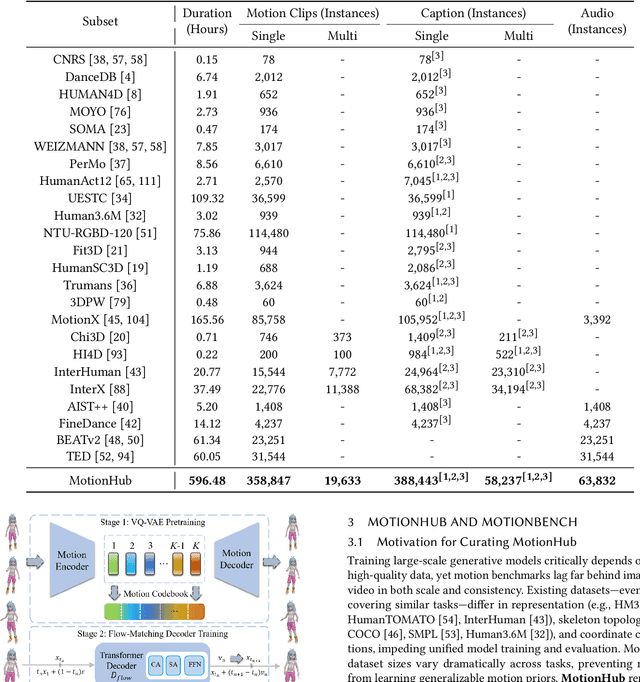
This paper introduces MotionLLaMA, a unified framework for motion synthesis and comprehension, along with a novel full-body motion tokenizer called the HoMi Tokenizer. MotionLLaMA is developed based on three core principles. First, it establishes a powerful unified representation space through the HoMi Tokenizer. Using a single codebook, the HoMi Tokenizer in MotionLLaMA achieves reconstruction accuracy comparable to residual vector quantization tokenizers utilizing six codebooks, outperforming all existing single-codebook tokenizers. Second, MotionLLaMA integrates a large language model to tackle various motion-related tasks. This integration bridges various modalities, facilitating both comprehensive and intricate motion synthesis and comprehension. Third, MotionLLaMA introduces the MotionHub dataset, currently the most extensive multimodal, multitask motion dataset, which enables fine-tuning of large language models. Extensive experimental results demonstrate that MotionLLaMA not only covers the widest range of motion-related tasks but also achieves state-of-the-art (SOTA) performance in motion completion, interaction dual-person text-to-motion, and all comprehension tasks while reaching performance comparable to SOTA in the remaining tasks. The code and MotionHub dataset are publicly available.
Stacking Brick by Brick: Aligned Feature Isolation for Incremental Face Forgery Detection
Nov 19, 2024



The rapid advancement of face forgery techniques has introduced a growing variety of forgeries. Incremental Face Forgery Detection (IFFD), involving gradually adding new forgery data to fine-tune the previously trained model, has been introduced as a promising strategy to deal with evolving forgery methods. However, a naively trained IFFD model is prone to catastrophic forgetting when new forgeries are integrated, as treating all forgeries as a single ''Fake" class in the Real/Fake classification can cause different forgery types overriding one another, thereby resulting in the forgetting of unique characteristics from earlier tasks and limiting the model's effectiveness in learning forgery specificity and generality. In this paper, we propose to stack the latent feature distributions of previous and new tasks brick by brick, $\textit{i.e.}$, achieving $\textbf{aligned feature isolation}$. In this manner, we aim to preserve learned forgery information and accumulate new knowledge by minimizing distribution overriding, thereby mitigating catastrophic forgetting. To achieve this, we first introduce Sparse Uniform Replay (SUR) to obtain the representative subsets that could be treated as the uniformly sparse versions of the previous global distributions. We then propose a Latent-space Incremental Detector (LID) that leverages SUR data to isolate and align distributions. For evaluation, we construct a more advanced and comprehensive benchmark tailored for IFFD. The leading experimental results validate the superiority of our method.
Can We Leave Deepfake Data Behind in Training Deepfake Detector?
Aug 30, 2024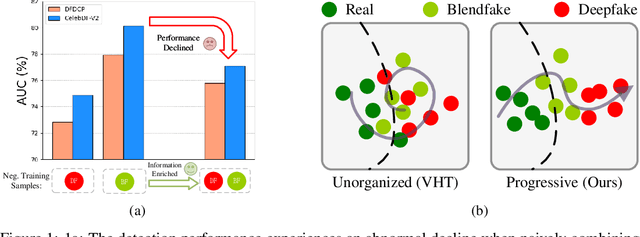
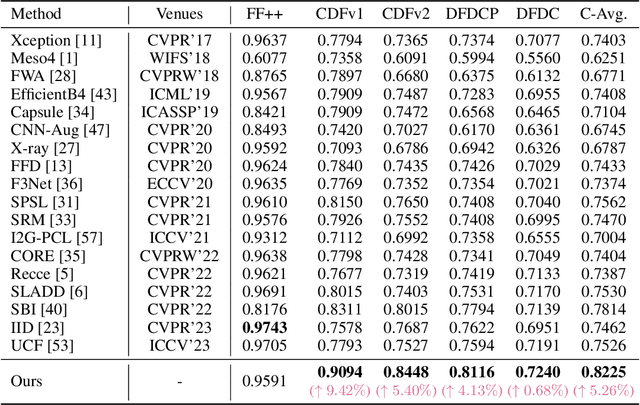
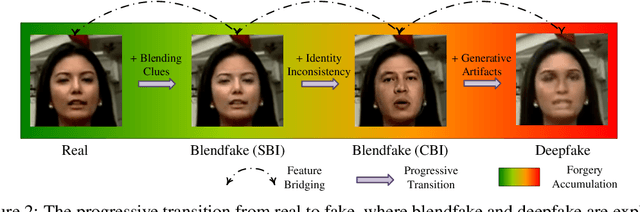
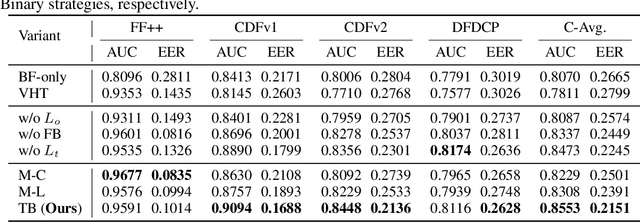
The generalization ability of deepfake detectors is vital for their applications in real-world scenarios. One effective solution to enhance this ability is to train the models with manually-blended data, which we termed "blendfake", encouraging models to learn generic forgery artifacts like blending boundary. Interestingly, current SoTA methods utilize blendfake without incorporating any deepfake data in their training process. This is likely because previous empirical observations suggest that vanilla hybrid training (VHT), which combines deepfake and blendfake data, results in inferior performance to methods using only blendfake data (so-called "1+1<2"). Therefore, a critical question arises: Can we leave deepfake behind and rely solely on blendfake data to train an effective deepfake detector? Intuitively, as deepfakes also contain additional informative forgery clues (e.g., deep generative artifacts), excluding all deepfake data in training deepfake detectors seems counter-intuitive. In this paper, we rethink the role of blendfake in detecting deepfakes and formulate the process from "real to blendfake to deepfake" to be a progressive transition. Specifically, blendfake and deepfake can be explicitly delineated as the oriented pivot anchors between "real-to-fake" transitions. The accumulation of forgery information should be oriented and progressively increasing during this transition process. To this end, we propose an Oriented Progressive Regularizor (OPR) to establish the constraints that compel the distribution of anchors to be discretely arranged. Furthermore, we introduce feature bridging to facilitate the smooth transition between adjacent anchors. Extensive experiments confirm that our design allows leveraging forgery information from both blendfake and deepfake effectively and comprehensively.
ED$^4$: Explicit Data-level Debiasing for Deepfake Detection
Aug 13, 2024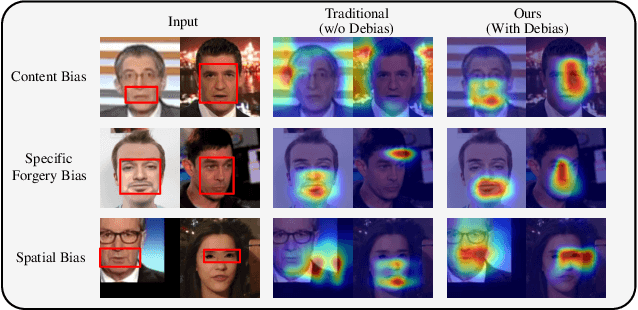
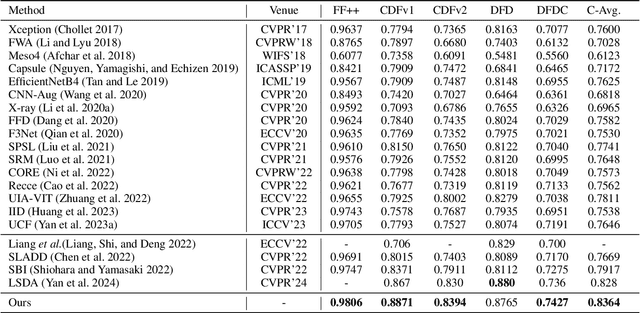
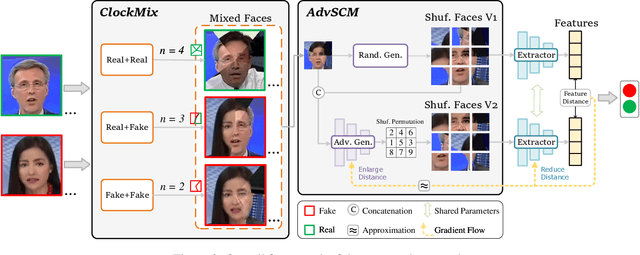

Learning intrinsic bias from limited data has been considered the main reason for the failure of deepfake detection with generalizability. Apart from the discovered content and specific-forgery bias, we reveal a novel spatial bias, where detectors inertly anticipate observing structural forgery clues appearing at the image center, also can lead to the poor generalization of existing methods. We present ED$^4$, a simple and effective strategy, to address aforementioned biases explicitly at the data level in a unified framework rather than implicit disentanglement via network design. In particular, we develop ClockMix to produce facial structure preserved mixtures with arbitrary samples, which allows the detector to learn from an exponentially extended data distribution with much more diverse identities, backgrounds, local manipulation traces, and the co-occurrence of multiple forgery artifacts. We further propose the Adversarial Spatial Consistency Module (AdvSCM) to prevent extracting features with spatial bias, which adversarially generates spatial-inconsistent images and constrains their extracted feature to be consistent. As a model-agnostic debiasing strategy, ED$^4$ is plug-and-play: it can be integrated with various deepfake detectors to obtain significant benefits. We conduct extensive experiments to demonstrate its effectiveness and superiority over existing deepfake detection approaches.
DePatch: Towards Robust Adversarial Patch for Evading Person Detectors in the Real World
Aug 13, 2024
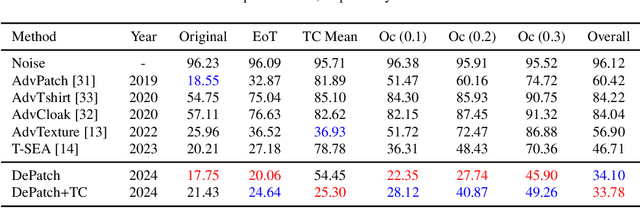
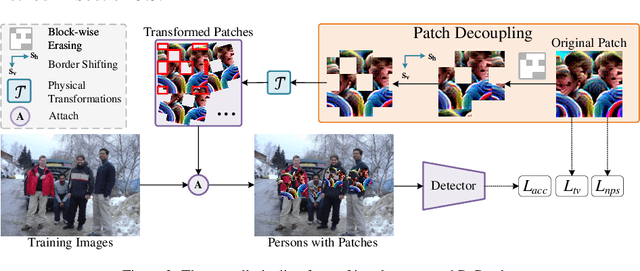
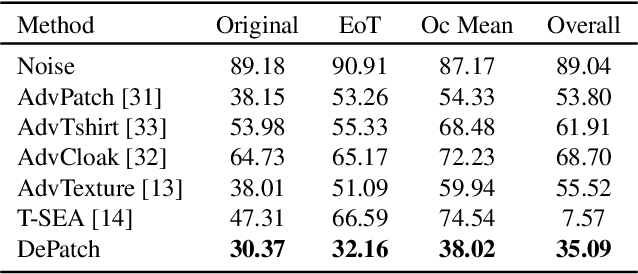
Recent years have seen an increasing interest in physical adversarial attacks, which aim to craft deployable patterns for deceiving deep neural networks, especially for person detectors. However, the adversarial patterns of existing patch-based attacks heavily suffer from the self-coupling issue, where a degradation, caused by physical transformations, in any small patch segment can result in a complete adversarial dysfunction, leading to poor robustness in the complex real world. Upon this observation, we introduce the Decoupled adversarial Patch (DePatch) attack to address the self-coupling issue of adversarial patches. Specifically, we divide the adversarial patch into block-wise segments, and reduce the inter-dependency among these segments through randomly erasing out some segments during the optimization. We further introduce a border shifting operation and a progressive decoupling strategy to improve the overall attack capabilities. Extensive experiments demonstrate the superior performance of our method over other physical adversarial attacks, especially in the real world.
IDRetracor: Towards Visual Forensics Against Malicious Face Swapping
Aug 13, 2024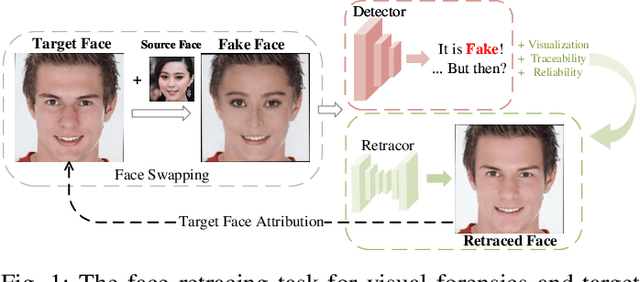
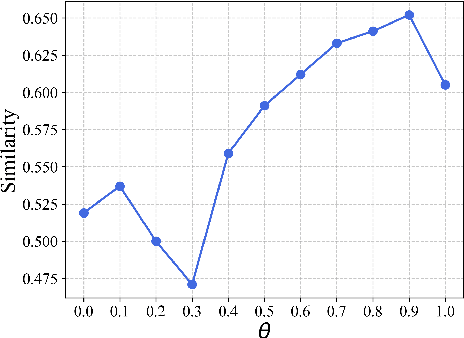


The face swapping technique based on deepfake methods poses significant social risks to personal identity security. While numerous deepfake detection methods have been proposed as countermeasures against malicious face swapping, they can only output binary labels (Fake/Real) for distinguishing fake content without reliable and traceable evidence. To achieve visual forensics and target face attribution, we propose a novel task named face retracing, which considers retracing the original target face from the given fake one via inverse mapping. Toward this goal, we propose an IDRetracor that can retrace arbitrary original target identities from fake faces generated by multiple face swapping methods. Specifically, we first adopt a mapping resolver to perceive the possible solution space of the original target face for the inverse mappings. Then, we propose mapping-aware convolutions to retrace the original target face from the fake one. Such convolutions contain multiple kernels that can be combined under the control of the mapping resolver to tackle different face swapping mappings dynamically. Extensive experiments demonstrate that the IDRetracor exhibits promising retracing performance from both quantitative and qualitative perspectives.