 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Streaming Human Motion Generation with Per-Joint Latent Decomposition
Mar 10, 2026Text-to-motion generation has advanced rapidly, yet two challenges persist. First, existing motion autoencoders compress each frame into a single monolithic latent vector, entangling trajectory and per-joint rotations in an unstructured representation that downstream generators struggle to model faithfully. Second, text-to-motion, pose-conditioned generation, and long-horizon sequential synthesis typically require separate models or task-specific mechanisms, with autoregressive approaches suffering from severe error accumulation over extended rollouts. We present PRISM, addressing each challenge with a dedicated contribution. (1) A joint-factorized motion latent space: each body joint occupies its own token, forming a structured 2D grid (time joints) compressed by a causal VAE with forward-kinematics supervision. This simple change to the latent space -- without modifying the generator -- substantially improves generation quality, revealing that latent space design has been an underestimated bottleneck. (2) Noise-free condition injection: each latent token carries its own timestep embedding, allowing conditioning frames to be injected as clean tokens (timestep0) while the remaining tokens are denoised. This unifies text-to-motion and pose-conditioned generation in a single model, and directly enables autoregressive segment chaining for streaming synthesis. Self-forcing training further suppresses drift in long rollouts. With these two components, we train a single motion generation foundation model that seamlessly handles text-to-motion, pose-conditioned generation, autoregressive sequential generation, and narrative motion composition, achieving state-of-the-art on HumanML3D, MotionHub, BABEL, and a 50-scenario user study.
EPIC: Efficient Prompt Interaction for Text-Image Classification
Jul 10, 2025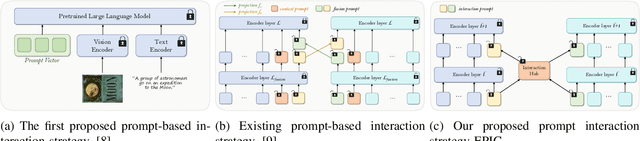
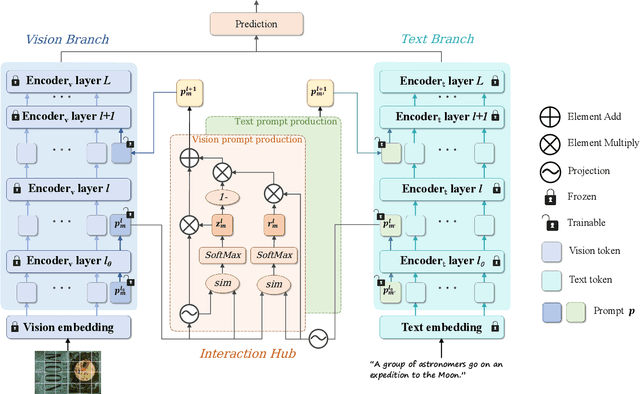
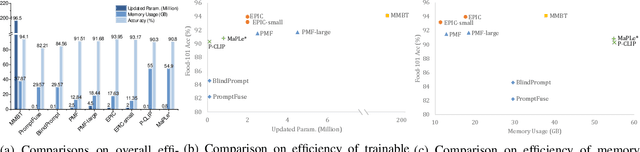

In recent years, large-scale pre-trained multimodal models (LMMs) generally emerge to integrate the vision and language modalities, achieving considerable success in multimodal tasks, such as text-image classification. The growing size of LMMs, however, results in a significant computational cost for fine-tuning these models for downstream tasks. Hence, prompt-based interaction strategy is studied to align modalities more efficiently. In this context, we propose a novel efficient prompt-based multimodal interaction strategy, namely Efficient Prompt Interaction for text-image Classification (EPIC). Specifically, we utilize temporal prompts on intermediate layers, and integrate different modalities with similarity-based prompt interaction, to leverage sufficient information exchange between modalities. Utilizing this approach, our method achieves reduced computational resource consumption and fewer trainable parameters (about 1\% of the foundation model) compared to other fine-tuning strategies. Furthermore, it demonstrates superior performance on the UPMC-Food101 and SNLI-VE datasets, while achieving comparable performance on the MM-IMDB dataset.
MotionLLaMA: A Unified Framework for Motion Synthesis and Comprehension
Nov 26, 2024
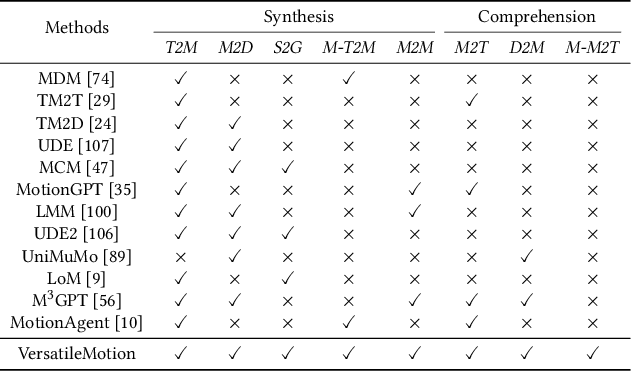
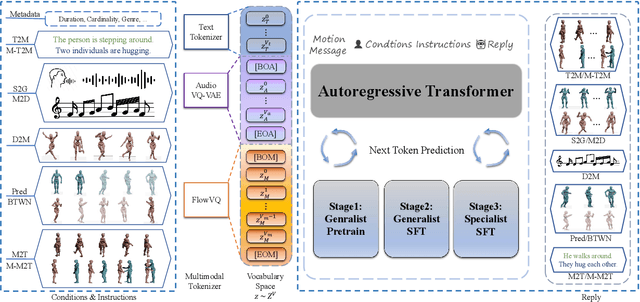
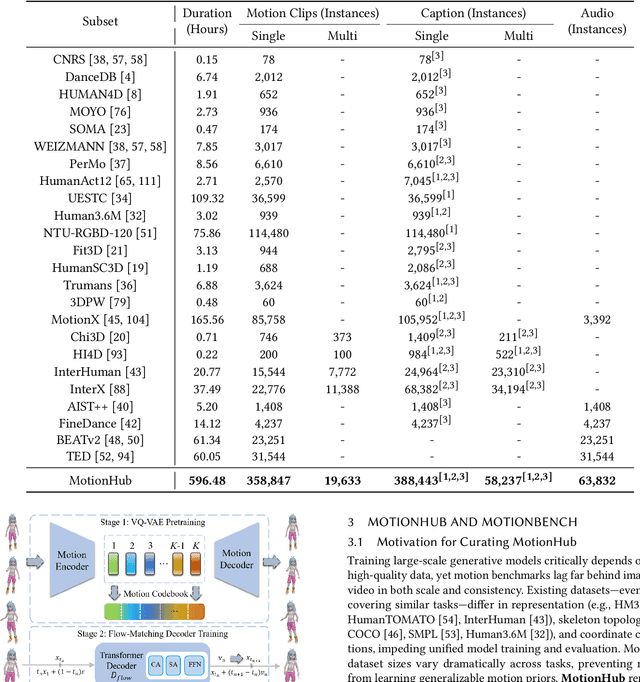
This paper introduces MotionLLaMA, a unified framework for motion synthesis and comprehension, along with a novel full-body motion tokenizer called the HoMi Tokenizer. MotionLLaMA is developed based on three core principles. First, it establishes a powerful unified representation space through the HoMi Tokenizer. Using a single codebook, the HoMi Tokenizer in MotionLLaMA achieves reconstruction accuracy comparable to residual vector quantization tokenizers utilizing six codebooks, outperforming all existing single-codebook tokenizers. Second, MotionLLaMA integrates a large language model to tackle various motion-related tasks. This integration bridges various modalities, facilitating both comprehensive and intricate motion synthesis and comprehension. Third, MotionLLaMA introduces the MotionHub dataset, currently the most extensive multimodal, multitask motion dataset, which enables fine-tuning of large language models. Extensive experimental results demonstrate that MotionLLaMA not only covers the widest range of motion-related tasks but also achieves state-of-the-art (SOTA) performance in motion completion, interaction dual-person text-to-motion, and all comprehension tasks while reaching performance comparable to SOTA in the remaining tasks. The code and MotionHub dataset are publicly available.
EnchantDance: Unveiling the Potential of Music-Driven Dance Movement
Dec 26, 2023The task of music-driven dance generation involves creating coherent dance movements that correspond to the given music. While existing methods can produce physically plausible dances, they often struggle to generalize to out-of-set data. The challenge arises from three aspects: 1) the high diversity of dance movements and significant differences in the distribution of music modalities, which make it difficult to generate music-aligned dance movements. 2) the lack of a large-scale music-dance dataset, which hinders the generation of generalized dance movements from music. 3) The protracted nature of dance movements poses a challenge to the maintenance of a consistent dance style. In this work, we introduce the EnchantDance framework, a state-of-the-art method for dance generation. Due to the redundancy of the original dance sequence along the time axis, EnchantDance first constructs a strong dance latent space and then trains a dance diffusion model on the dance latent space. To address the data gap, we construct a large-scale music-dance dataset, ChoreoSpectrum3D Dataset, which includes four dance genres and has a total duration of 70.32 hours, making it the largest reported music-dance dataset to date. To enhance consistency between music genre and dance style, we pre-train a music genre prediction network using transfer learning and incorporate music genre as extra conditional information in the training of the dance diffusion model. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance on dance quality, diversity, and consistency.
MCM: Multi-condition Motion Synthesis Framework for Multi-scenario
Sep 06, 2023



The objective of the multi-condition human motion synthesis task is to incorporate diverse conditional inputs, encompassing various forms like text, music, speech, and more. This endows the task with the capability to adapt across multiple scenarios, ranging from text-to-motion and music-to-dance, among others. While existing research has primarily focused on single conditions, the multi-condition human motion generation remains underexplored. In this paper, we address these challenges by introducing MCM, a novel paradigm for motion synthesis that spans multiple scenarios under diverse conditions. The MCM framework is able to integrate with any DDPM-like diffusion model to accommodate multi-conditional information input while preserving its generative capabilities. Specifically, MCM employs two-branch architecture consisting of a main branch and a control branch. The control branch shares the same structure as the main branch and is initialized with the parameters of the main branch, effectively maintaining the generation ability of the main branch and supporting multi-condition input. We also introduce a Transformer-based diffusion model MWNet (DDPM-like) as our main branch that can capture the spatial complexity and inter-joint correlations in motion sequences through a channel-dimension self-attention module. Quantitative comparisons demonstrate that our approach achieves SoTA results in both text-to-motion and competitive results in music-to-dance tasks, comparable to task-specific methods. Furthermore, the qualitative evaluation shows that MCM not only streamlines the adaptation of methodologies originally designed for text-to-motion tasks to domains like music-to-dance and speech-to-gesture, eliminating the need for extensive network re-configurations but also enables effective multi-condition modal control, realizing "once trained is motion need".