 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiM-Gestor: Co-Speech Gesture Generation with Adaptive Layer Normalization Mamba-2
Nov 23, 2024
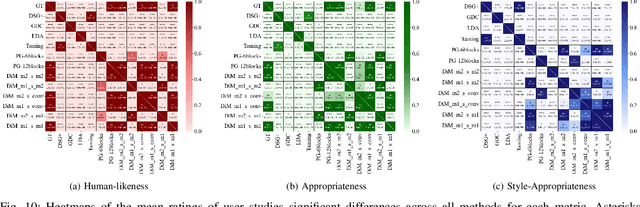
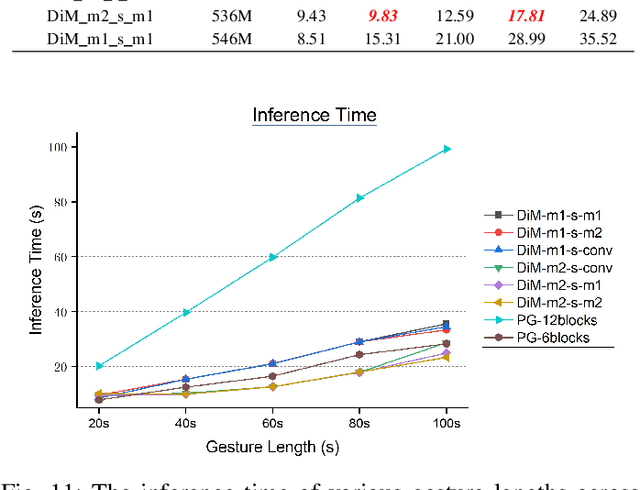
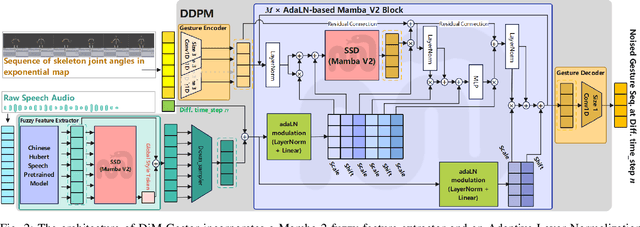
Speech-driven gesture generation using transformer-based generative models represents a rapidly advancing area within virtual human creation. However, existing models face significant challenges due to their quadratic time and space complexities, limiting scalability and efficiency. To address these limitations, we introduce DiM-Gestor, an innovative end-to-end generative model leveraging the Mamba-2 architecture. DiM-Gestor features a dual-component framework: (1) a fuzzy feature extractor and (2) a speech-to-gesture mapping module, both built on the Mamba-2. The fuzzy feature extractor, integrated with a Chinese Pre-trained Model and Mamba-2, autonomously extracts implicit, continuous speech features. These features are synthesized into a unified latent representation and then processed by the speech-to-gesture mapping module. This module employs an Adaptive Layer Normalization (AdaLN)-enhanced Mamba-2 mechanism to uniformly apply transformations across all sequence tokens. This enables precise modeling of the nuanced interplay between speech features and gesture dynamics. We utilize a diffusion model to train and infer diverse gesture outputs. Extensive subjective and objective evaluations conducted on the newly released Chinese Co-Speech Gestures dataset corroborate the efficacy of our proposed model. Compared with Transformer-based architecture, the assessments reveal that our approach delivers competitive results and significantly reduces memory usage, approximately 2.4 times, and enhances inference speeds by 2 to 4 times. Additionally, we released the CCG dataset, a Chinese Co-Speech Gestures dataset, comprising 15.97 hours (six styles across five scenarios) of 3D full-body skeleton gesture motion performed by professional Chinese TV broadcasters.
Speech-driven Personalized Gesture Synthetics: Harnessing Automatic Fuzzy Feature Inference
Mar 16, 2024
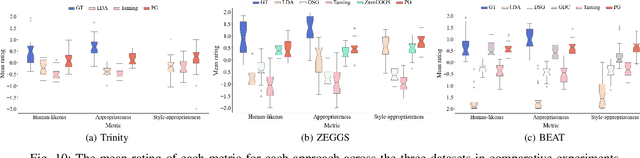
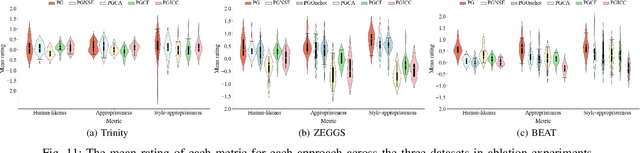
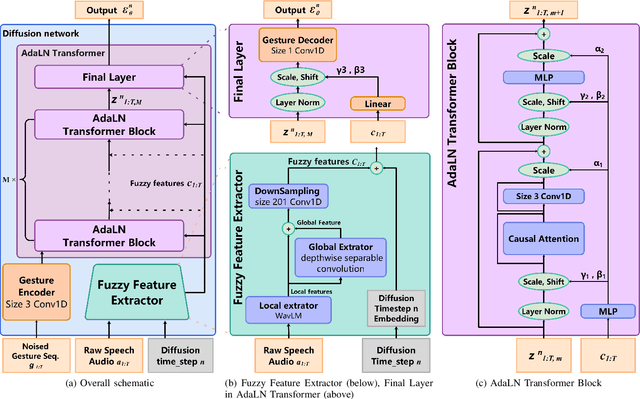
Speech-driven gesture generation is an emerging field within virtual human creation. However, a significant challenge lies in accurately determining and processing the multitude of input features (such as acoustic, semantic, emotional, personality, and even subtle unknown features). Traditional approaches, reliant on various explicit feature inputs and complex multimodal processing, constrain the expressiveness of resulting gestures and limit their applicability. To address these challenges, we present Persona-Gestor, a novel end-to-end generative model designed to generate highly personalized 3D full-body gestures solely relying on raw speech audio. The model combines a fuzzy feature extractor and a non-autoregressive Adaptive Layer Normalization (AdaLN) transformer diffusion architecture. The fuzzy feature extractor harnesses a fuzzy inference strategy that automatically infers implicit, continuous fuzzy features. These fuzzy features, represented as a unified latent feature, are fed into the AdaLN transformer. The AdaLN transformer introduces a conditional mechanism that applies a uniform function across all tokens, thereby effectively modeling the correlation between the fuzzy features and the gesture sequence. This module ensures a high level of gesture-speech synchronization while preserving naturalness. Finally, we employ the diffusion model to train and infer various gestures. Extensive subjective and objective evaluations on the Trinity, ZEGGS, and BEAT datasets confirm our model's superior performance to the current state-of-the-art approaches. Persona-Gestor improves the system's usability and generalization capabilities, setting a new benchmark in speech-driven gesture synthesis and broadening the horizon for virtual human technology. Supplementary videos and code can be accessed at https://zf223669.github.io/Diffmotion-v2-website/
Optimal Noise pursuit for Augmenting Text-to-Video Generation
Nov 02, 2023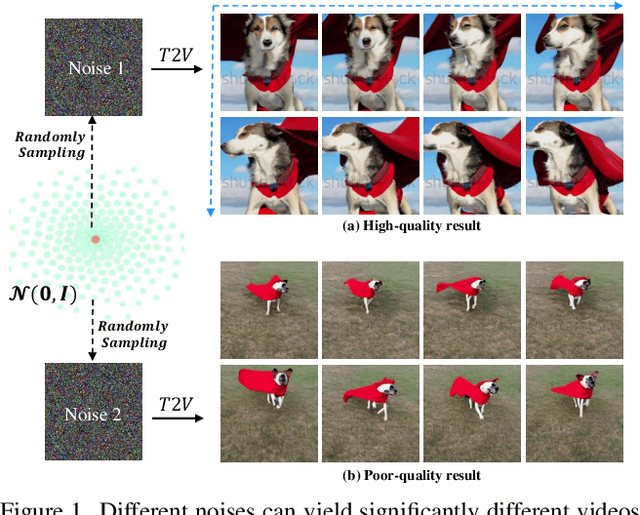



Despite the remarkable progress in text-to-video generation, existing diffusion-based models often exhibit instability in terms of noise during inference. Specifically, when different noises are fed for the given text, these models produce videos that differ significantly in terms of both frame quality and temporal consistency. With this observation, we posit that there exists an optimal noise matched to each textual input; however, the widely adopted strategies of random noise sampling often fail to capture it. In this paper, we argue that the optimal noise can be approached through inverting the groundtruth video using the established noise-video mapping derived from the diffusion model. Nevertheless, the groundtruth video for the text prompt is not available during inference. To address this challenge, we propose to approximate the optimal noise via a search and inversion pipeline. Given a text prompt, we initially search for a video from a predefined candidate pool that closely relates to the text prompt. Subsequently, we invert the searched video into the noise space, which serves as an improved noise prompt for the textual input. In addition to addressing noise, we also observe that the text prompt with richer details often leads to higher-quality videos. Motivated by this, we further design a semantic-preserving rewriter to enrich the text prompt, where a reference-guided rewriting is devised for reasonable details compensation, and a denoising with a hybrid semantics strategy is proposed to preserve the semantic consistency. Extensive experiments on the WebVid-10M benchmark show that our proposed method can improve the text-to-video models with a clear margin, while introducing no optimization burden.
MCM: Multi-condition Motion Synthesis Framework for Multi-scenario
Sep 06, 2023



The objective of the multi-condition human motion synthesis task is to incorporate diverse conditional inputs, encompassing various forms like text, music, speech, and more. This endows the task with the capability to adapt across multiple scenarios, ranging from text-to-motion and music-to-dance, among others. While existing research has primarily focused on single conditions, the multi-condition human motion generation remains underexplored. In this paper, we address these challenges by introducing MCM, a novel paradigm for motion synthesis that spans multiple scenarios under diverse conditions. The MCM framework is able to integrate with any DDPM-like diffusion model to accommodate multi-conditional information input while preserving its generative capabilities. Specifically, MCM employs two-branch architecture consisting of a main branch and a control branch. The control branch shares the same structure as the main branch and is initialized with the parameters of the main branch, effectively maintaining the generation ability of the main branch and supporting multi-condition input. We also introduce a Transformer-based diffusion model MWNet (DDPM-like) as our main branch that can capture the spatial complexity and inter-joint correlations in motion sequences through a channel-dimension self-attention module. Quantitative comparisons demonstrate that our approach achieves SoTA results in both text-to-motion and competitive results in music-to-dance tasks, comparable to task-specific methods. Furthermore, the qualitative evaluation shows that MCM not only streamlines the adaptation of methodologies originally designed for text-to-motion tasks to domains like music-to-dance and speech-to-gesture, eliminating the need for extensive network re-configurations but also enables effective multi-condition modal control, realizing "once trained is motion need".
Learning to Sketch Human Facial Portraits using Personal Styles by Case-Based Reasoning
Sep 13, 2016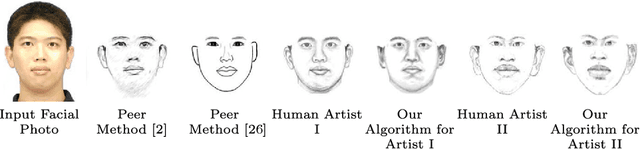
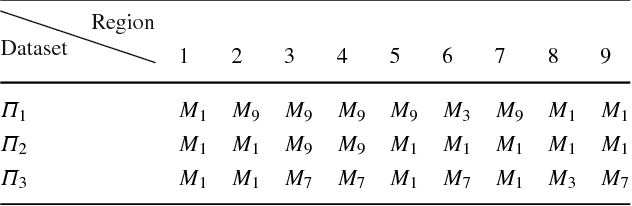

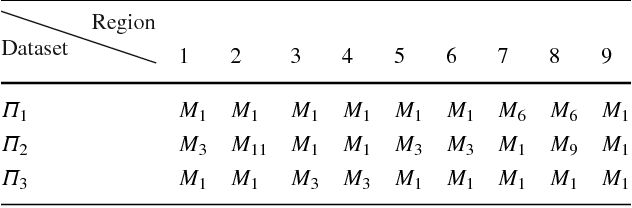
This paper employs case-based reasoning (CBR) to capture the personal styles of individual artists and generate the human facial portraits from photos accordingly. For each human artist to be mimicked, a series of cases are firstly built-up from her/his exemplars of source facial photo and hand-drawn sketch, and then its stylization for facial photo is transformed as a style-transferring process of iterative refinement by looking-for and applying best-fit cases in a sense of style optimization. Two models, fitness evaluation model and parameter estimation model, are learned for case retrieval and adaptation respectively from these cases. The fitness evaluation model is to decide which case is best-fitted to the sketching of current interest, and the parameter estimation model is to automate case adaptation. The resultant sketch is synthesized progressively with an iterative loop of retrieval and adaptation of candidate cases until the desired aesthetic style is achieved. To explore the effectiveness and advantages of the novel approach, we experimentally compare the sketch portraits generated by the proposed method with that of a state-of-the-art example-based facial sketch generation algorithm as well as a couple commercial software packages. The comparisons reveal that our CBR based synthesis method for facial portraits is superior both in capturing and reproducing artists' personal illustration styles to the peer methods.