 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiM-Gestor: Co-Speech Gesture Generation with Adaptive Layer Normalization Mamba-2
Paper and Code

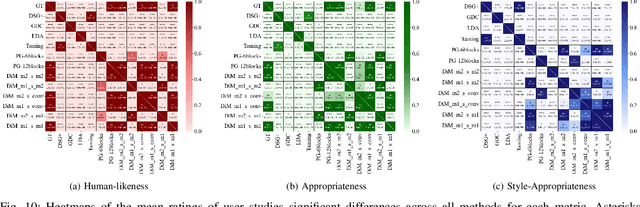
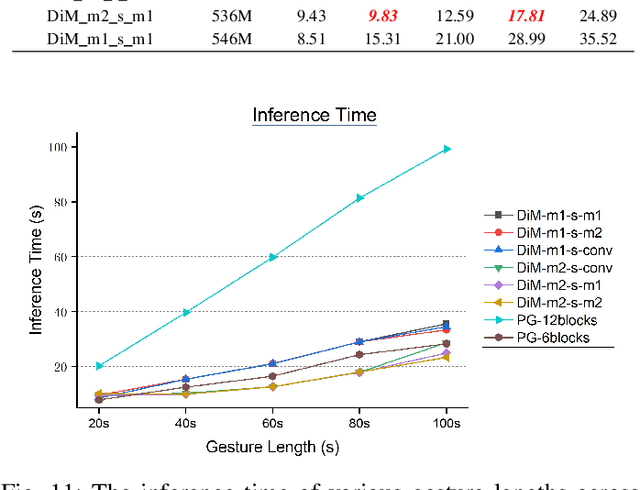
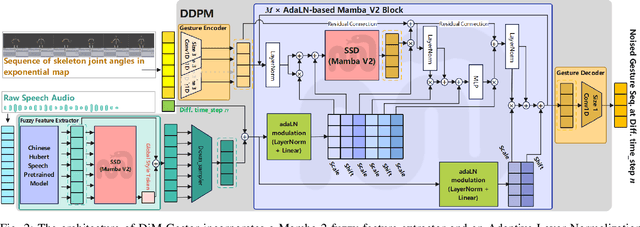
Speech-driven gesture generation using transformer-based generative models represents a rapidly advancing area within virtual human creation. However, existing models face significant challenges due to their quadratic time and space complexities, limiting scalability and efficiency. To address these limitations, we introduce DiM-Gestor, an innovative end-to-end generative model leveraging the Mamba-2 architecture. DiM-Gestor features a dual-component framework: (1) a fuzzy feature extractor and (2) a speech-to-gesture mapping module, both built on the Mamba-2. The fuzzy feature extractor, integrated with a Chinese Pre-trained Model and Mamba-2, autonomously extracts implicit, continuous speech features. These features are synthesized into a unified latent representation and then processed by the speech-to-gesture mapping module. This module employs an Adaptive Layer Normalization (AdaLN)-enhanced Mamba-2 mechanism to uniformly apply transformations across all sequence tokens. This enables precise modeling of the nuanced interplay between speech features and gesture dynamics. We utilize a diffusion model to train and infer diverse gesture outputs. Extensive subjective and objective evaluations conducted on the newly released Chinese Co-Speech Gestures dataset corroborate the efficacy of our proposed model. Compared with Transformer-based architecture, the assessments reveal that our approach delivers competitive results and significantly reduces memory usage, approximately 2.4 times, and enhances inference speeds by 2 to 4 times. Additionally, we released the CCG dataset, a Chinese Co-Speech Gestures dataset, comprising 15.97 hours (six styles across five scenarios) of 3D full-body skeleton gesture motion performed by professional Chinese TV broadcasters.