 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Noise pursuit for Augmenting Text-to-Video Generation
Nov 02, 2023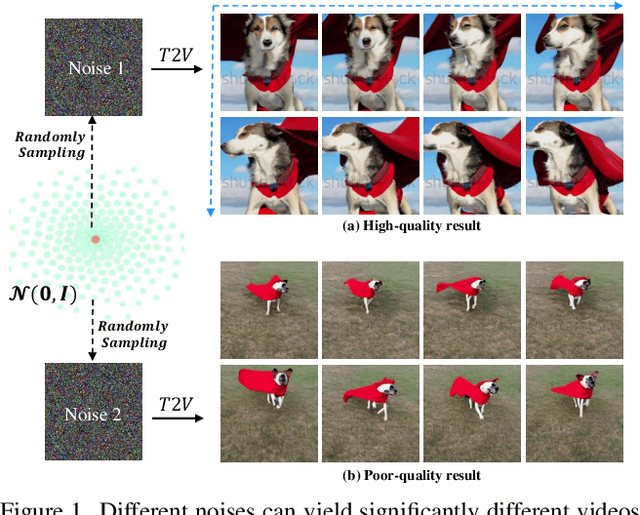



Despite the remarkable progress in text-to-video generation, existing diffusion-based models often exhibit instability in terms of noise during inference. Specifically, when different noises are fed for the given text, these models produce videos that differ significantly in terms of both frame quality and temporal consistency. With this observation, we posit that there exists an optimal noise matched to each textual input; however, the widely adopted strategies of random noise sampling often fail to capture it. In this paper, we argue that the optimal noise can be approached through inverting the groundtruth video using the established noise-video mapping derived from the diffusion model. Nevertheless, the groundtruth video for the text prompt is not available during inference. To address this challenge, we propose to approximate the optimal noise via a search and inversion pipeline. Given a text prompt, we initially search for a video from a predefined candidate pool that closely relates to the text prompt. Subsequently, we invert the searched video into the noise space, which serves as an improved noise prompt for the textual input. In addition to addressing noise, we also observe that the text prompt with richer details often leads to higher-quality videos. Motivated by this, we further design a semantic-preserving rewriter to enrich the text prompt, where a reference-guided rewriting is devised for reasonable details compensation, and a denoising with a hybrid semantics strategy is proposed to preserve the semantic consistency. Extensive experiments on the WebVid-10M benchmark show that our proposed method can improve the text-to-video models with a clear margin, while introducing no optimization burden.