 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn EMO Joint Pruning with Multiple Sub-networks: Fast and Effect
Mar 28, 2023The network pruning algorithm based on evolutionary multi-objective (EMO) can balance the pruning rate and performance of the network. However, its population-based nature often suffers from the complex pruning optimization space and the highly resource-consuming pruning structure verification process, which limits its application. To this end, this paper proposes an EMO joint pruning with multiple sub-networks (EMO-PMS) to reduce space complexity and resource consumption. First, a divide-and-conquer EMO network pruning framework is proposed, which decomposes the complex EMO pruning task on the whole network into easier sub-tasks on multiple sub-networks. On the one hand, this decomposition reduces the pruning optimization space and decreases the optimization difficulty; on the other hand, the smaller network structure converges faster, so the computational resource consumption of the proposed algorithm is lower. Secondly, a sub-network training method based on cross-network constraints is designed so that the sub-network can process the features generated by the previous one through feature constraints. This method allows sub-networks optimized independently to collaborate better and improves the overall performance of the pruned network. Finally, a multiple sub-networks joint pruning method based on EMO is proposed. For one thing, it can accurately measure the feature processing capability of the sub-networks with the pre-trained feature selector. For another, it can combine multi-objective pruning results on multiple sub-networks through global performance impairment ranking to design a joint pruning scheme. The proposed algorithm is validated on three datasets with different challenging. Compared with fifteen advanced pruning algorithms, the experiment results exhibit the effectiveness and efficiency of the proposed algorithm.
Sparsely Grouped Multi-task Generative Adversarial Networks for Facial Attribute Manipulation
Oct 19, 2018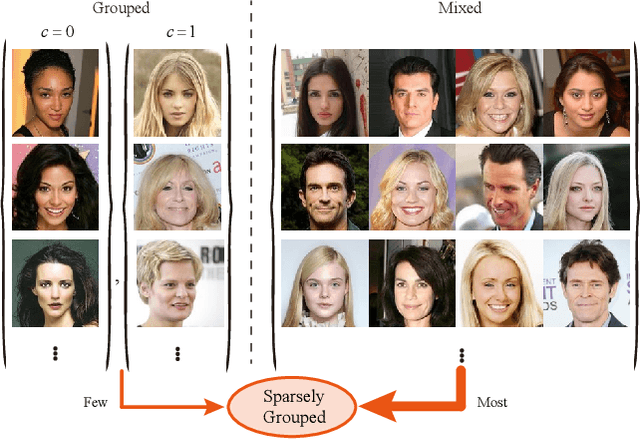
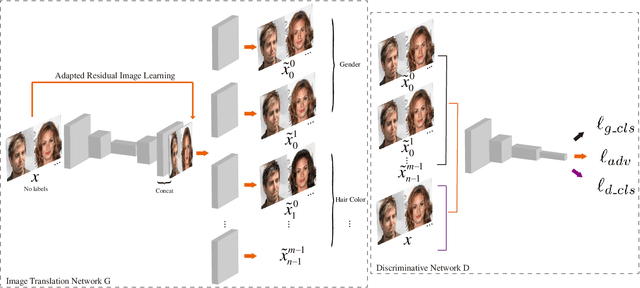
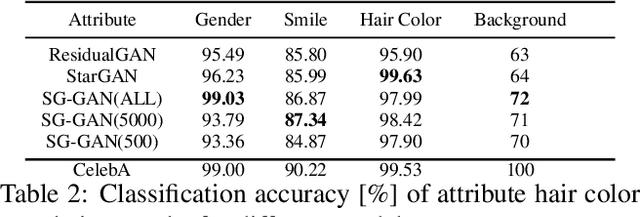
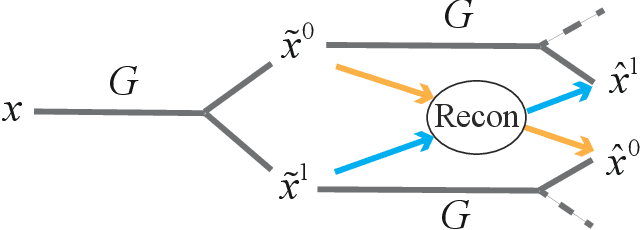
Recently, Image-to-Image Translation (IIT) has achieved great progress in image style transfer and semantic context manipulation for images. However, existing approaches require exhaustively labelling training data, which is labor demanding, difficult to scale up, and hard to adapt to a new domain. To overcome such a key limitation, we propose Sparsely Grouped Generative Adversarial Networks (SG-GAN) as a novel approach that can translate images in sparsely grouped datasets where only a few train samples are labelled. Using a one-input multi-output architecture, SG-GAN is well-suited for tackling multi-task learning and sparsely grouped learning tasks. The new model is able to translate images among multiple groups using only a single trained model. To experimentally validate the advantages of the new model, we apply the proposed method to tackle a series of attribute manipulation tasks for facial images as a case study. Experimental results show that SG-GAN can achieve comparable results with state-of-the-art methods on adequately labelled datasets while attaining a superior image translation quality on sparsely grouped datasets.
Learning to Sketch Human Facial Portraits using Personal Styles by Case-Based Reasoning
Sep 13, 2016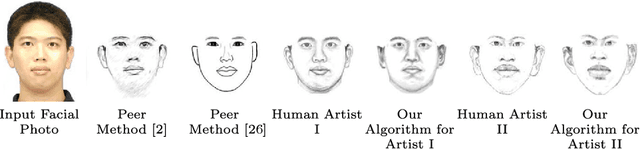
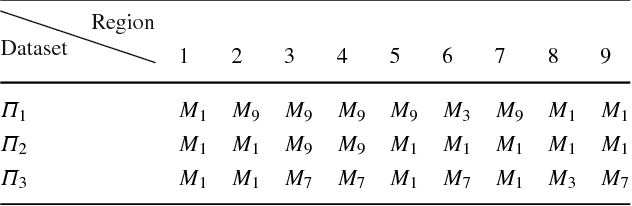

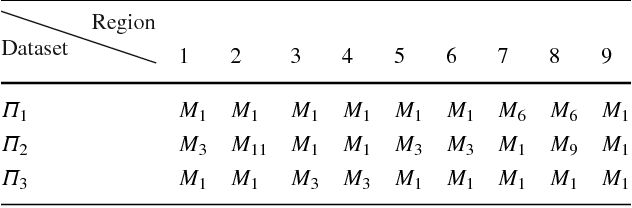
This paper employs case-based reasoning (CBR) to capture the personal styles of individual artists and generate the human facial portraits from photos accordingly. For each human artist to be mimicked, a series of cases are firstly built-up from her/his exemplars of source facial photo and hand-drawn sketch, and then its stylization for facial photo is transformed as a style-transferring process of iterative refinement by looking-for and applying best-fit cases in a sense of style optimization. Two models, fitness evaluation model and parameter estimation model, are learned for case retrieval and adaptation respectively from these cases. The fitness evaluation model is to decide which case is best-fitted to the sketching of current interest, and the parameter estimation model is to automate case adaptation. The resultant sketch is synthesized progressively with an iterative loop of retrieval and adaptation of candidate cases until the desired aesthetic style is achieved. To explore the effectiveness and advantages of the novel approach, we experimentally compare the sketch portraits generated by the proposed method with that of a state-of-the-art example-based facial sketch generation algorithm as well as a couple commercial software packages. The comparisons reveal that our CBR based synthesis method for facial portraits is superior both in capturing and reproducing artists' personal illustration styles to the peer methods.