 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU2UData: A Large-scale Cooperative Perception Dataset for Swarm UAVs Autonomous Flight
Aug 05, 2024
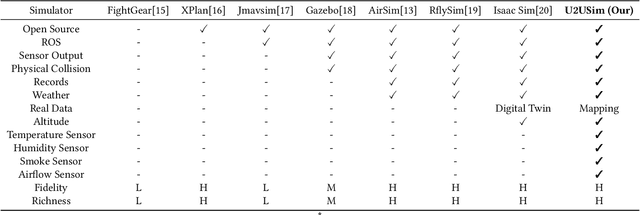

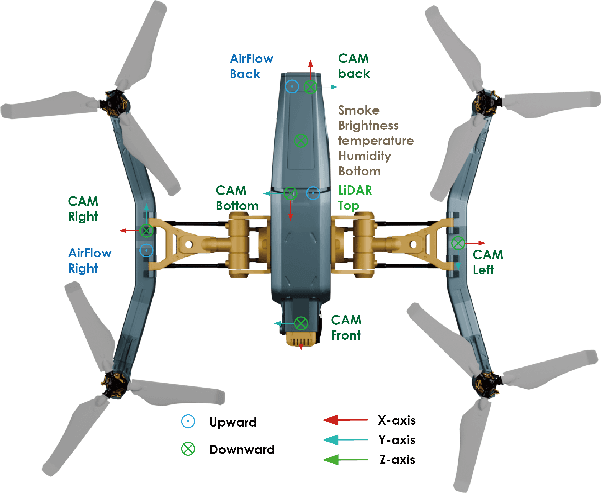
Modern perception systems for autonomous flight are sensitive to occlusion and have limited long-range capability, which is a key bottleneck in improving low-altitude economic task performance. Recent research has shown that the UAV-to-UAV (U2U) cooperative perception system has great potential to revolutionize the autonomous flight industry. However, the lack of a large-scale dataset is hindering progress in this area. This paper presents U2UData, the first large-scale cooperative perception dataset for swarm UAVs autonomous flight. The dataset was collected by three UAVs flying autonomously in the U2USim, covering a 9 km$^2$ flight area. It comprises 315K LiDAR frames, 945K RGB and depth frames, and 2.41M annotated 3D bounding boxes for 3 classes. It also includes brightness, temperature, humidity, smoke, and airflow values covering all flight routes. U2USim is the first real-world mapping swarm UAVs simulation environment. It takes Yunnan Province as the prototype and includes 4 terrains, 7 weather conditions, and 8 sensor types. U2UData introduces two perception tasks: cooperative 3D object detection and cooperative 3D object tracking. This paper provides comprehensive benchmarks of recent cooperative perception algorithms on these tasks.
EnchantDance: Unveiling the Potential of Music-Driven Dance Movement
Dec 26, 2023The task of music-driven dance generation involves creating coherent dance movements that correspond to the given music. While existing methods can produce physically plausible dances, they often struggle to generalize to out-of-set data. The challenge arises from three aspects: 1) the high diversity of dance movements and significant differences in the distribution of music modalities, which make it difficult to generate music-aligned dance movements. 2) the lack of a large-scale music-dance dataset, which hinders the generation of generalized dance movements from music. 3) The protracted nature of dance movements poses a challenge to the maintenance of a consistent dance style. In this work, we introduce the EnchantDance framework, a state-of-the-art method for dance generation. Due to the redundancy of the original dance sequence along the time axis, EnchantDance first constructs a strong dance latent space and then trains a dance diffusion model on the dance latent space. To address the data gap, we construct a large-scale music-dance dataset, ChoreoSpectrum3D Dataset, which includes four dance genres and has a total duration of 70.32 hours, making it the largest reported music-dance dataset to date. To enhance consistency between music genre and dance style, we pre-train a music genre prediction network using transfer learning and incorporate music genre as extra conditional information in the training of the dance diffusion model. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance on dance quality, diversity, and consistency.
VideoDreamer: Customized Multi-Subject Text-to-Video Generation with Disen-Mix Finetuning
Nov 02, 2023Customized text-to-video generation aims to generate text-guided videos with customized user-given subjects, which has gained increasing attention recently. However, existing works are primarily limited to generating videos for a single subject, leaving the more challenging problem of customized multi-subject text-to-video generation largely unexplored. In this paper, we fill this gap and propose a novel VideoDreamer framework. VideoDreamer can generate temporally consistent text-guided videos that faithfully preserve the visual features of the given multiple subjects. Specifically, VideoDreamer leverages the pretrained Stable Diffusion with latent-code motion dynamics and temporal cross-frame attention as the base video generator. The video generator is further customized for the given multiple subjects by the proposed Disen-Mix Finetuning and Human-in-the-Loop Re-finetuning strategy, which can tackle the attribute binding problem of multi-subject generation. We also introduce MultiStudioBench, a benchmark for evaluating customized multi-subject text-to-video generation models. Extensive experiments demonstrate the remarkable ability of VideoDreamer to generate videos with new content such as new events and backgrounds, tailored to the customized multiple subjects. Our project page is available at https://videodreamer23.github.io/.