 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisenStudio: Customized Multi-subject Text-to-Video Generation with Disentangled Spatial Control
May 21, 2024



Generating customized content in videos has received increasing attention recently. However, existing works primarily focus on customized text-to-video generation for single subject, suffering from subject-missing and attribute-binding problems when the video is expected to contain multiple subjects. Furthermore, existing models struggle to assign the desired actions to the corresponding subjects (action-binding problem), failing to achieve satisfactory multi-subject generation performance. To tackle the problems, in this paper, we propose DisenStudio, a novel framework that can generate text-guided videos for customized multiple subjects, given few images for each subject. Specifically, DisenStudio enhances a pretrained diffusion-based text-to-video model with our proposed spatial-disentangled cross-attention mechanism to associate each subject with the desired action. Then the model is customized for the multiple subjects with the proposed motion-preserved disentangled finetuning, which involves three tuning strategies: multi-subject co-occurrence tuning, masked single-subject tuning, and multi-subject motion-preserved tuning. The first two strategies guarantee the subject occurrence and preserve their visual attributes, and the third strategy helps the model maintain the temporal motion-generation ability when finetuning on static images. We conduct extensive experiments to demonstrate our proposed DisenStudio significantly outperforms existing methods in various metrics. Additionally, we show that DisenStudio can be used as a powerful tool for various controllable generation applications.
LLM4VG: Large Language Models Evaluation for Video Grounding
Dec 28, 2023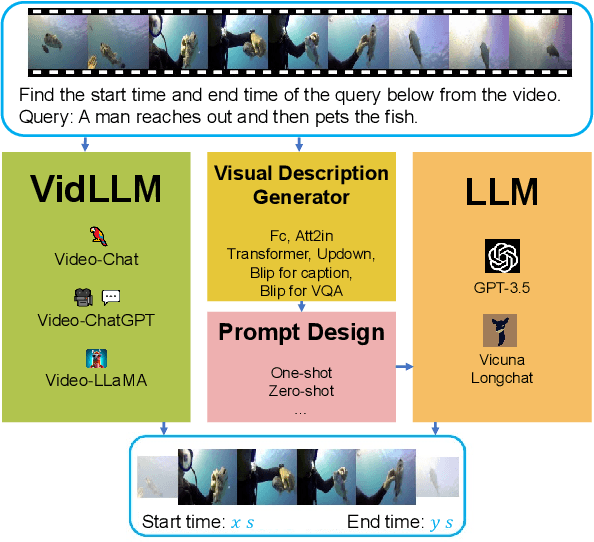
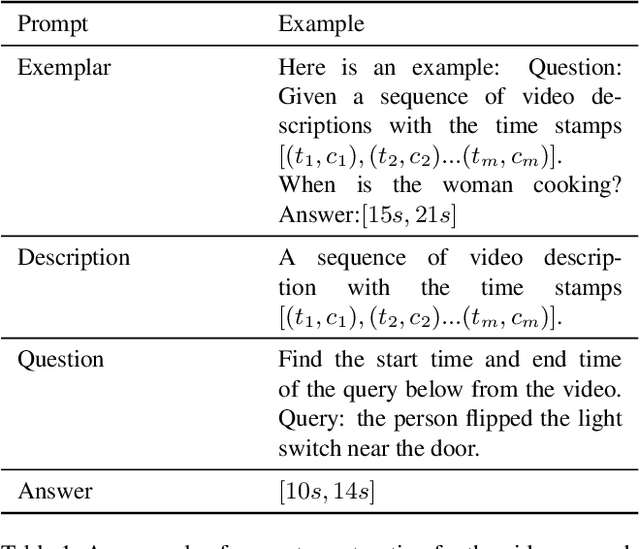

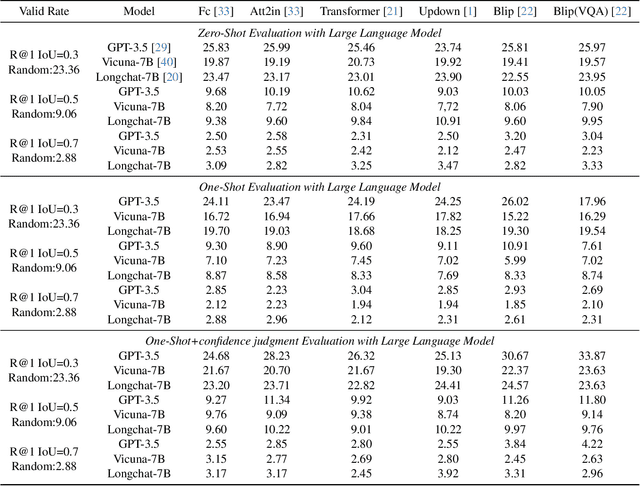
Recently, researchers have attempted to investigate the capability of LLMs in handling videos and proposed several video LLM models. However, the ability of LLMs to handle video grounding (VG), which is an important time-related video task requiring the model to precisely locate the start and end timestamps of temporal moments in videos that match the given textual queries, still remains unclear and unexplored in literature. To fill the gap, in this paper, we propose the LLM4VG benchmark, which systematically evaluates the performance of different LLMs on video grounding tasks. Based on our proposed LLM4VG, we design extensive experiments to examine two groups of video LLM models on video grounding: (i) the video LLMs trained on the text-video pairs (denoted as VidLLM), and (ii) the LLMs combined with pretrained visual description models such as the video/image captioning model. We propose prompt methods to integrate the instruction of VG and description from different kinds of generators, including caption-based generators for direct visual description and VQA-based generators for information enhancement. We also provide comprehensive comparisons of various VidLLMs and explore the influence of different choices of visual models, LLMs, prompt designs, etc, as well. Our experimental evaluations lead to two conclusions: (i) the existing VidLLMs are still far away from achieving satisfactory video grounding performance, and more time-related video tasks should be included to further fine-tune these models, and (ii) the combination of LLMs and visual models shows preliminary abilities for video grounding with considerable potential for improvement by resorting to more reliable models and further guidance of prompt instructions.
VideoDreamer: Customized Multi-Subject Text-to-Video Generation with Disen-Mix Finetuning
Nov 02, 2023Customized text-to-video generation aims to generate text-guided videos with customized user-given subjects, which has gained increasing attention recently. However, existing works are primarily limited to generating videos for a single subject, leaving the more challenging problem of customized multi-subject text-to-video generation largely unexplored. In this paper, we fill this gap and propose a novel VideoDreamer framework. VideoDreamer can generate temporally consistent text-guided videos that faithfully preserve the visual features of the given multiple subjects. Specifically, VideoDreamer leverages the pretrained Stable Diffusion with latent-code motion dynamics and temporal cross-frame attention as the base video generator. The video generator is further customized for the given multiple subjects by the proposed Disen-Mix Finetuning and Human-in-the-Loop Re-finetuning strategy, which can tackle the attribute binding problem of multi-subject generation. We also introduce MultiStudioBench, a benchmark for evaluating customized multi-subject text-to-video generation models. Extensive experiments demonstrate the remarkable ability of VideoDreamer to generate videos with new content such as new events and backgrounds, tailored to the customized multiple subjects. Our project page is available at https://videodreamer23.github.io/.
DisenBooth: Disentangled Parameter-Efficient Tuning for Subject-Driven Text-to-Image Generation
May 05, 2023Given a small set of images of a specific subject, subject-driven text-to-image generation aims to generate customized images of the subject according to new text descriptions, which has attracted increasing attention in the community recently. Current subject-driven text-to-image generation methods are mainly based on finetuning a pretrained large-scale text-to-image generation model. However, these finetuning methods map the images of the subject into an embedding highly entangled with subject-identity-unrelated information, which may result in the inconsistency between the generated images and the text descriptions and the changes in the subject identity. To tackle the problem, we propose DisenBooth, a disentangled parameter-efficient tuning framework for subject-driven text-to-image generation. DisenBooth enables generating new images that simultaneously preserve the subject identity and conform to the text descriptions, by disentangling the embedding into an identity-related and an identity-unrelated part. Specifically, DisenBooth is based on the pretrained diffusion models and conducts finetuning in the diffusion denoising process, where a shared identity embedding and an image-specific identity-unrelated embedding are utilized jointly for denoising each image. To make the two embeddings disentangled, two auxiliary objectives are proposed. Additionally, to improve the finetuning efficiency, a parameter-efficient finetuning strategy is adopted. Extensive experiments show that our DisenBooth can faithfully learn well-disentangled identity-related and identity-unrelated embeddings. With the shared identity embedding, DisenBooth demonstrates superior subject-driven text-to-image generation ability. Additionally, DisenBooth provides a more flexible and controllable framework with different combinations of the disentangled embeddings.