 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisenBooth: Disentangled Parameter-Efficient Tuning for Subject-Driven Text-to-Image Generation
May 05, 2023Given a small set of images of a specific subject, subject-driven text-to-image generation aims to generate customized images of the subject according to new text descriptions, which has attracted increasing attention in the community recently. Current subject-driven text-to-image generation methods are mainly based on finetuning a pretrained large-scale text-to-image generation model. However, these finetuning methods map the images of the subject into an embedding highly entangled with subject-identity-unrelated information, which may result in the inconsistency between the generated images and the text descriptions and the changes in the subject identity. To tackle the problem, we propose DisenBooth, a disentangled parameter-efficient tuning framework for subject-driven text-to-image generation. DisenBooth enables generating new images that simultaneously preserve the subject identity and conform to the text descriptions, by disentangling the embedding into an identity-related and an identity-unrelated part. Specifically, DisenBooth is based on the pretrained diffusion models and conducts finetuning in the diffusion denoising process, where a shared identity embedding and an image-specific identity-unrelated embedding are utilized jointly for denoising each image. To make the two embeddings disentangled, two auxiliary objectives are proposed. Additionally, to improve the finetuning efficiency, a parameter-efficient finetuning strategy is adopted. Extensive experiments show that our DisenBooth can faithfully learn well-disentangled identity-related and identity-unrelated embeddings. With the shared identity embedding, DisenBooth demonstrates superior subject-driven text-to-image generation ability. Additionally, DisenBooth provides a more flexible and controllable framework with different combinations of the disentangled embeddings.
Weakly Supervised Dense Event Captioning in Videos
Dec 10, 2018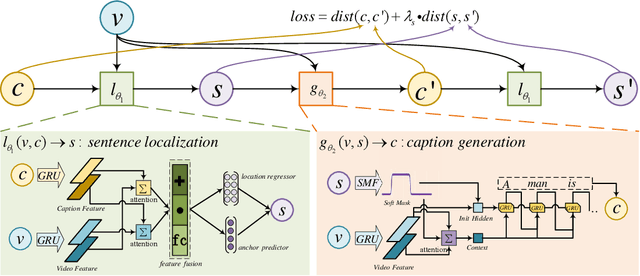
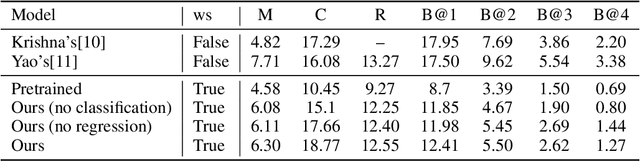
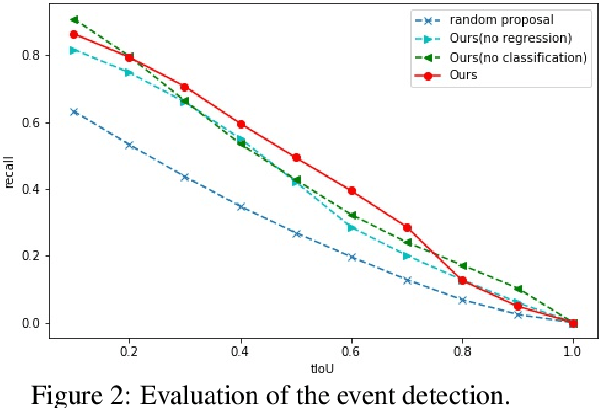

Dense event captioning aims to detect and describe all events of interest contained in a video. Despite the advanced development in this area, existing methods tackle this task by making use of dense temporal annotations, which is dramatically source-consuming. This paper formulates a new problem: weakly supervised dense event captioning, which does not require temporal segment annotations for model training. Our solution is based on the one-to-one correspondence assumption, each caption describes one temporal segment, and each temporal segment has one caption, which holds in current benchmark datasets and most real-world cases. We decompose the problem into a pair of dual problems: event captioning and sentence localization and present a cycle system to train our model. Extensive experimental results are provided to demonstrate the ability of our model on both dense event captioning and sentence localization in videos.
Learning-to-Ask: Knowledge Acquisition via 20 Questions
Jun 22, 2018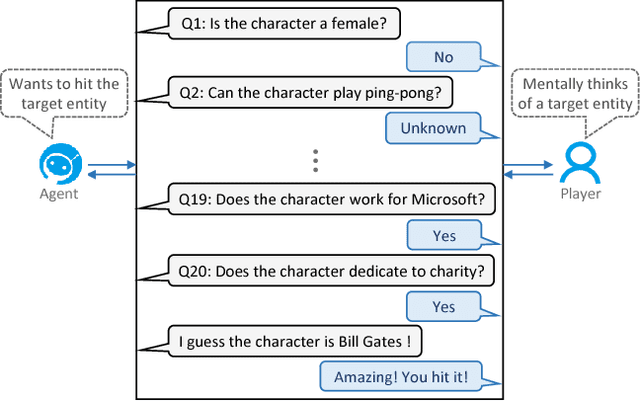

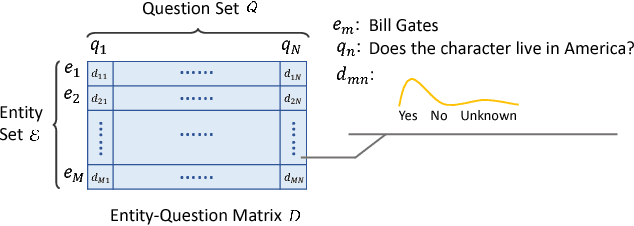
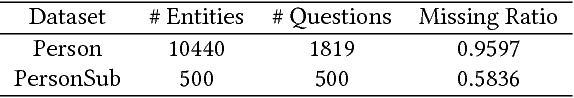
Almost all the knowledge empowered applications rely upon accurate knowledge, which has to be either collected manually with high cost, or extracted automatically with unignorable errors. In this paper, we study 20 Questions, an online interactive game where each question-response pair corresponds to a fact of the target entity, to acquire highly accurate knowledge effectively with nearly zero labor cost. Knowledge acquisition via 20 Questions predominantly presents two challenges to the intelligent agent playing games with human players. The first one is to seek enough information and identify the target entity with as few questions as possible, while the second one is to leverage the remaining questioning opportunities to acquire valuable knowledge effectively, both of which count on good questioning strategies. To address these challenges, we propose the Learning-to-Ask (LA) framework, within which the agent learns smart questioning strategies for information seeking and knowledge acquisition by means of deep reinforcement learning and generalized matrix factorization respectively. In addition, a Bayesian approach to represent knowledge is adopted to ensure robustness to noisy user responses. Simulating experiments on real data show that LA is able to equip the agent with effective questioning strategies, which result in high winning rates and rapid knowledge acquisition. Moreover, the questioning strategies for information seeking and knowledge acquisition boost the performance of each other, allowing the agent to start with a relatively small knowledge set and quickly improve its knowledge base in the absence of constant human supervision.