 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieving to Recover: Towards Incomplete Audio-Visual Question Answering via Semantic-consistent Purification
Apr 14, 2026Recent Audio-Visual Question Answering (AVQA) methods have advanced significantly. However, most AVQA methods lack effective mechanisms for handling missing modalities, suffering from severe performance degradation in real-world scenarios with data interruptions. Furthermore, prevailing methods for handling missing modalities predominantly rely on generative imputation to synthesize missing features. While partially effective, these methods tend to capture inter-modal commonalities but struggle to acquire unique, modality-specific knowledge within the missing data, leading to hallucinations and compromised reasoning accuracy. To tackle these challenges, we propose R$^{2}$ScP, a novel framework that shifts the paradigm of missing modality handling from traditional generative imputation to retrieval-based recovery. Specifically, we leverage cross-modal retrieval via unified semantic embeddings to acquire missing domain-specific knowledge. To maximize semantic restoration, we introduce a context-aware adaptive purification mechanism that eliminates latent semantic noise within the retrieved data. Additionally, we employ a two-stage training strategy to explicitly model the semantic relationships between knowledge from different sources. Extensive experiments demonstrate that R$^{2}$ScP significantly improves AVQA and enhances robustness in modal-incomplete scenarios.
UAV-Track VLA: Embodied Aerial Tracking via Vision-Language-Action Models
Apr 02, 2026Embodied visual tracking is crucial for Unmanned Aerial Vehicles (UAVs) executing complex real-world tasks. In dynamic urban scenarios with complex semantic requirements, Vision-Language-Action (VLA) models show great promise due to their cross-modal fusion and continuous action generation capabilities. To benchmark multimodal tracking in such environments, we construct a dedicated evaluation benchmark and a large-scale dataset encompassing over 890K frames, 176 tasks, and 85 diverse objects. Furthermore, to address temporal feature redundancy and the lack of spatial geometric priors in existing VLA models, we propose an improved VLA tracking model, UAV-Track VLA. Built upon the $π_{0.5}$ architecture, our model introduces a temporal compression net to efficiently capture inter-frame dynamics. Additionally, a parallel dual-branch decoder comprising a spatial-aware auxiliary grounding head and a flow matching action expert is designed to decouple cross-modal features and generate fine-grained continuous actions. Systematic experiments in the CARLA simulator validate the superior end-to-end performance of our method. Notably, in challenging long-distance pedestrian tracking tasks, UAV-Track VLA achieves a 61.76\% success rate and 269.65 average tracking frames, significantly outperforming existing baselines. Furthermore, it demonstrates robust zero-shot generalization in unseen environments and reduces single-step inference latency by 33.4\% (to 0.0571s) compared to the original $π_{0.5}$, enabling highly efficient, real-time UAV control. Data samples and demonstration videos are available at: https://github.com/Hub-Tian/UAV-Track\_VLA.
Two-Stage Heterogeneous Graph Neural Network for RIS-Aided Physical-Layer Security
Mar 15, 2026This paper investigates physical-layer security (PLS) enabled by graph neural networks (GNNs). We propose a two-stage heterogeneous GNN (HGNN) to maximize the secrecy energy efficiency (SEE) of a reconfigurable intelligent surface (RIS)-assisted multi-input-single-output (MISO) system that serves multiple legitimate users (LUs) and eavesdroppers (Eves). The first stage formulates the system as a bipartite graph involving three types of nodes-RIS reflecting elements, LUs, and Eves-with the goal of generating the RIS phase shift matrix. The second stage models the system as a fully connected graph with two types of nodes (LUs and Eves), aiming to produce beamforming and artificial noise (AN) vectors. Both stages adopt an HGNN integrated with a multi-head attention mechanism, and the second stage incorporates two output methods: beam-direct and model-based approaches. The two-stage HGNN is trained in an unsupervised manner and designed to scale with the number of RIS reflecting elements, LUs, and Eves. Numerical results demonstrate that the proposed two-stage HGNN outperforms state-of-the-art GNNs in RIS-aided PLS scenarios. Compared with convex optimization algorithms, it reduces the average running time by three orders of magnitude with a performance loss of less than $4\%$. Additionally, the scalability of the two-stage HGNN is validated through extensive simulations.
AIR-VLA: Vision-Language-Action Systems for Aerial Manipulation
Jan 29, 2026While Vision-Language-Action (VLA) models have achieved remarkable success in ground-based embodied intelligence, their application to Aerial Manipulation Systems (AMS) remains a largely unexplored frontier. The inherent characteristics of AMS, including floating-base dynamics, strong coupling between the UAV and the manipulator, and the multi-step, long-horizon nature of operational tasks, pose severe challenges to existing VLA paradigms designed for static or 2D mobile bases. To bridge this gap, we propose AIR-VLA, the first VLA benchmark specifically tailored for aerial manipulation. We construct a physics-based simulation environment and release a high-quality multimodal dataset comprising 3000 manually teleoperated demonstrations, covering base manipulation, object & spatial understanding, semantic reasoning, and long-horizon planning. Leveraging this platform, we systematically evaluate mainstream VLA models and state-of-the-art VLM models. Our experiments not only validate the feasibility of transferring VLA paradigms to aerial systems but also, through multi-dimensional metrics tailored to aerial tasks, reveal the capabilities and boundaries of current models regarding UAV mobility, manipulator control, and high-level planning. AIR-VLA establishes a standardized testbed and data foundation for future research in general-purpose aerial robotics. The resource of AIR-VLA will be available at https://anonymous.4open.science/r/AIR-VLA-dataset-B5CC/.
UI-AGILE: Advancing GUI Agents with Effective Reinforcement Learning and Precise Inference-Time Grounding
Jul 30, 2025The emergence of Multimodal Large Language Models (MLLMs) has driven significant advances in Graphical User Interface (GUI) agent capabilities. Nevertheless, existing GUI agent training and inference techniques still suffer from a dilemma for reasoning designs, ineffective reward, and visual noise. To address these issues, we introduce UI-AGILE, a comprehensive framework enhancing GUI agents at both the training and inference stages. For training, we propose a suite of improvements to the Supervised Fine-Tuning (SFT) process: 1) a Continuous Reward function to incentivize high-precision grounding; 2) a "Simple Thinking" reward to balance planning with speed and grounding accuracy; and 3) a Cropping-based Resampling strategy to mitigate the sparse reward problem and improve learning on complex tasks. For inference, we present Decomposed Grounding with Selection, a novel method that dramatically improves grounding accuracy on high-resolution displays by breaking the image into smaller, manageable parts. Experiments show that UI-AGILE achieves the state-of-the-art performance on two benchmarks ScreenSpot-Pro and ScreenSpot-v2. For instance, using both our proposed training and inference enhancement methods brings 23% grounding accuracy improvement over the best baseline on ScreenSpot-Pro.
SWIPTNet: A Unified Deep Learning Framework for SWIPT based on GNN and Transfer Learning
Feb 06, 2025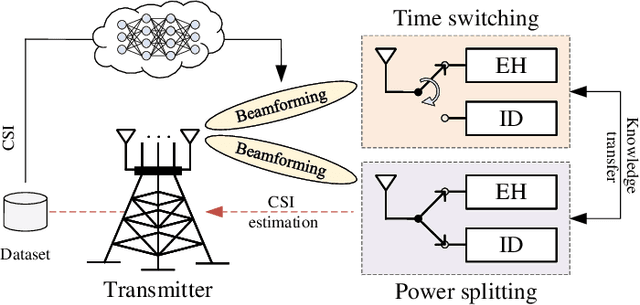
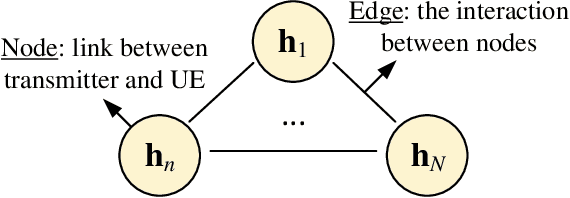
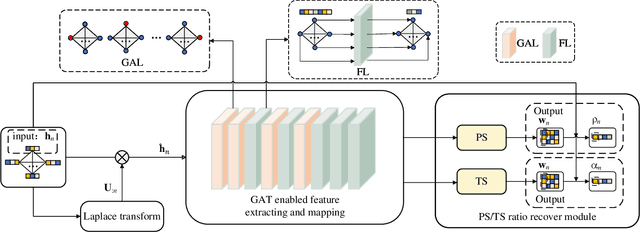
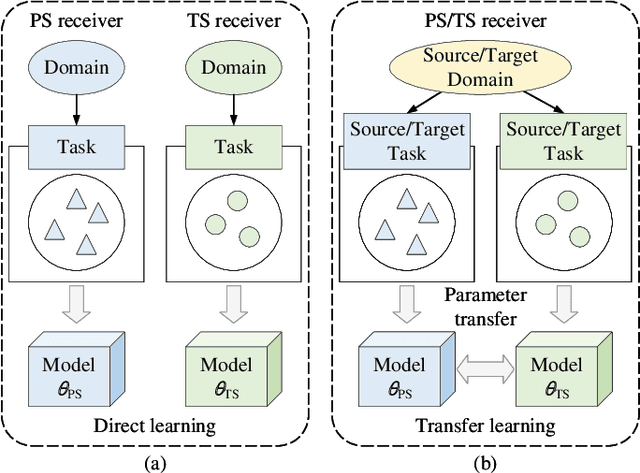
This paper investigates the deep learning based approaches for simultaneous wireless information and power transfer (SWIPT). The quality-of-service (QoS) constrained sum-rate maximization problems are, respectively, formulated for power-splitting (PS) receivers and time-switching (TS) receivers and solved by a unified graph neural network (GNN) based model termed SWIPT net (SWIPTNet). To improve the performance of SWIPTNet, we first propose a single-type output method to reduce the learning complexity and facilitate the satisfaction of QoS constraints, and then, utilize the Laplace transform to enhance input features with the structural information. Besides, we adopt the multi-head attention and layer connection to enhance feature extracting. Furthermore, we present the implementation of transfer learning to the SWIPTNet between PS and TS receivers. Ablation studies show the effectiveness of key components in the SWIPTNet. Numerical results also demonstrate the capability of SWIPTNet in achieving near-optimal performance with millisecond-level inference speed which is much faster than the traditional optimization algorithms. We also show the effectiveness of transfer learning via fast convergence and expressive capability improvement.
LLM4VG: Large Language Models Evaluation for Video Grounding
Dec 28, 2023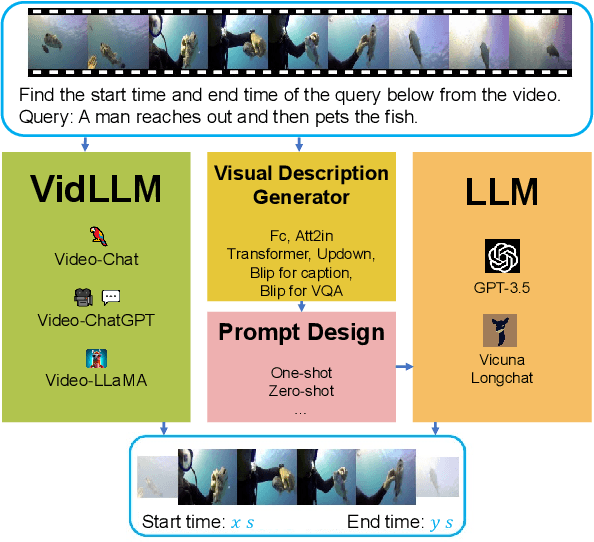
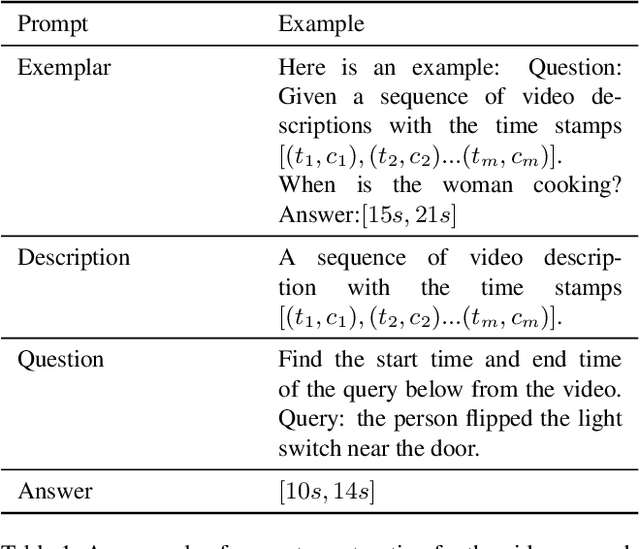

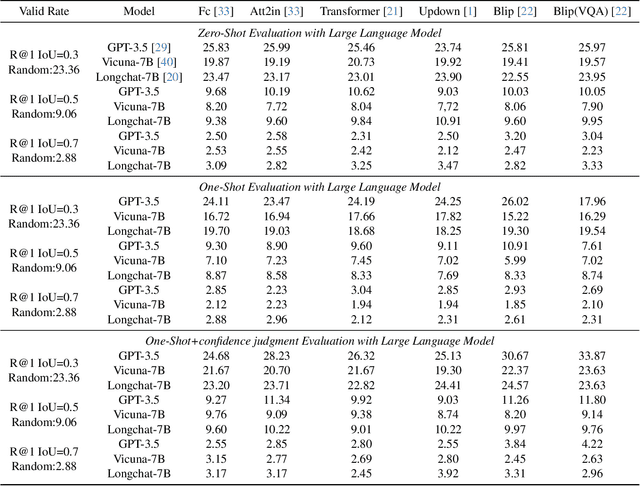
Recently, researchers have attempted to investigate the capability of LLMs in handling videos and proposed several video LLM models. However, the ability of LLMs to handle video grounding (VG), which is an important time-related video task requiring the model to precisely locate the start and end timestamps of temporal moments in videos that match the given textual queries, still remains unclear and unexplored in literature. To fill the gap, in this paper, we propose the LLM4VG benchmark, which systematically evaluates the performance of different LLMs on video grounding tasks. Based on our proposed LLM4VG, we design extensive experiments to examine two groups of video LLM models on video grounding: (i) the video LLMs trained on the text-video pairs (denoted as VidLLM), and (ii) the LLMs combined with pretrained visual description models such as the video/image captioning model. We propose prompt methods to integrate the instruction of VG and description from different kinds of generators, including caption-based generators for direct visual description and VQA-based generators for information enhancement. We also provide comprehensive comparisons of various VidLLMs and explore the influence of different choices of visual models, LLMs, prompt designs, etc, as well. Our experimental evaluations lead to two conclusions: (i) the existing VidLLMs are still far away from achieving satisfactory video grounding performance, and more time-related video tasks should be included to further fine-tune these models, and (ii) the combination of LLMs and visual models shows preliminary abilities for video grounding with considerable potential for improvement by resorting to more reliable models and further guidance of prompt instructions.
Grounding-Prompter: Prompting LLM with Multimodal Information for Temporal Sentence Grounding in Long Videos
Dec 28, 2023Temporal Sentence Grounding (TSG), which aims to localize moments from videos based on the given natural language queries, has attracted widespread attention. Existing works are mainly designed for short videos, failing to handle TSG in long videos, which poses two challenges: i) complicated contexts in long videos require temporal reasoning over longer moment sequences, and ii) multiple modalities including textual speech with rich information require special designs for content understanding in long videos. To tackle these challenges, in this work we propose a Grounding-Prompter method, which is capable of conducting TSG in long videos through prompting LLM with multimodal information. In detail, we first transform the TSG task and its multimodal inputs including speech and visual, into compressed task textualization. Furthermore, to enhance temporal reasoning under complicated contexts, a Boundary-Perceptive Prompting strategy is proposed, which contains three folds: i) we design a novel Multiscale Denoising Chain-of-Thought (CoT) to combine global and local semantics with noise filtering step by step, ii) we set up validity principles capable of constraining LLM to generate reasonable predictions following specific formats, and iii) we introduce one-shot In-Context-Learning (ICL) to boost reasoning through imitation, enhancing LLM in TSG task understanding. Experiments demonstrate the state-of-the-art performance of our Grounding-Prompter method, revealing the benefits of prompting LLM with multimodal information for TSG in long videos.
VTimeLLM: Empower LLM to Grasp Video Moments
Nov 30, 2023Large language models (LLMs) have shown remarkable text understanding capabilities, which have been extended as Video LLMs to handle video data for comprehending visual details. However, existing Video LLMs can only provide a coarse description of the entire video, failing to capture the precise start and end time boundary of specific events. In this paper, we solve this issue via proposing VTimeLLM, a novel Video LLM designed for fine-grained video moment understanding and reasoning with respect to time boundary. Specifically, our VTimeLLM adopts a boundary-aware three-stage training strategy, which respectively utilizes image-text pairs for feature alignment, multiple-event videos to increase temporal-boundary awareness, and high-quality video-instruction tuning to further improve temporal understanding ability as well as align with human intents. Extensive experiments demonstrate that in fine-grained time-related comprehension tasks for videos such as Temporal Video Grounding and Dense Video Captioning, VTimeLLM significantly outperforms existing Video LLMs. Besides, benefits from the fine-grained temporal understanding of the videos further enable VTimeLLM to beat existing Video LLMs in video dialogue benchmark, showing its superior cross-modal understanding and reasoning abilities.