 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Leave Deepfake Data Behind in Training Deepfake Detector?
Paper and Code
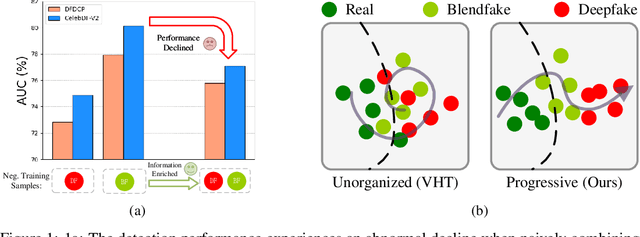
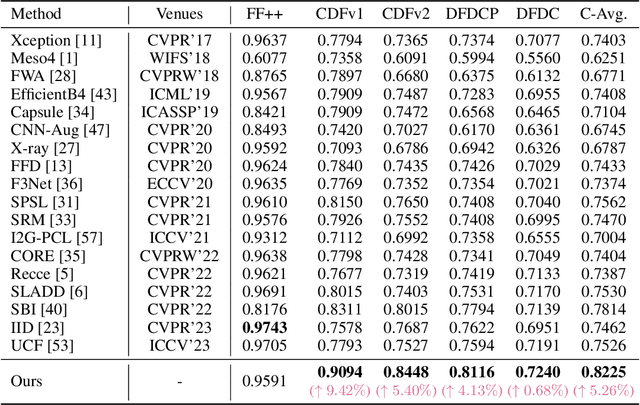
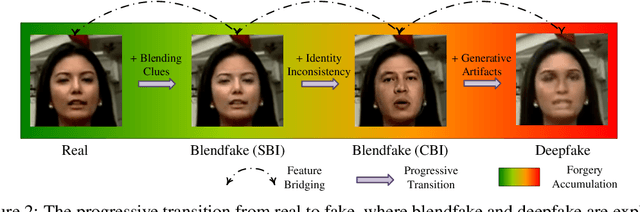
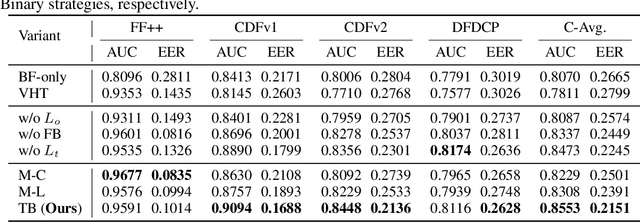
The generalization ability of deepfake detectors is vital for their applications in real-world scenarios. One effective solution to enhance this ability is to train the models with manually-blended data, which we termed "blendfake", encouraging models to learn generic forgery artifacts like blending boundary. Interestingly, current SoTA methods utilize blendfake without incorporating any deepfake data in their training process. This is likely because previous empirical observations suggest that vanilla hybrid training (VHT), which combines deepfake and blendfake data, results in inferior performance to methods using only blendfake data (so-called "1+1<2"). Therefore, a critical question arises: Can we leave deepfake behind and rely solely on blendfake data to train an effective deepfake detector? Intuitively, as deepfakes also contain additional informative forgery clues (e.g., deep generative artifacts), excluding all deepfake data in training deepfake detectors seems counter-intuitive. In this paper, we rethink the role of blendfake in detecting deepfakes and formulate the process from "real to blendfake to deepfake" to be a progressive transition. Specifically, blendfake and deepfake can be explicitly delineated as the oriented pivot anchors between "real-to-fake" transitions. The accumulation of forgery information should be oriented and progressively increasing during this transition process. To this end, we propose an Oriented Progressive Regularizor (OPR) to establish the constraints that compel the distribution of anchors to be discretely arranged. Furthermore, we introduce feature bridging to facilitate the smooth transition between adjacent anchors. Extensive experiments confirm that our design allows leveraging forgery information from both blendfake and deepfake effectively and comprehensively.