 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Mar 10, 2025Text-to-Image (T2I) models are capable of generating high-quality artistic creations and visual content. However, existing research and evaluation standards predominantly focus on image realism and shallow text-image alignment, lacking a comprehensive assessment of complex semantic understanding and world knowledge integration in text to image generation. To address this challenge, we propose $\textbf{WISE}$, the first benchmark specifically designed for $\textbf{W}$orld Knowledge-$\textbf{I}$nformed $\textbf{S}$emantic $\textbf{E}$valuation. WISE moves beyond simple word-pixel mapping by challenging models with 1000 meticulously crafted prompts across 25 sub-domains in cultural common sense, spatio-temporal reasoning, and natural science. To overcome the limitations of traditional CLIP metric, we introduce $\textbf{WiScore}$, a novel quantitative metric for assessing knowledge-image alignment. Through comprehensive testing of 20 models (10 dedicated T2I models and 10 unified multimodal models) using 1,000 structured prompts spanning 25 subdomains, our findings reveal significant limitations in their ability to effectively integrate and apply world knowledge during image generation, highlighting critical pathways for enhancing knowledge incorporation and application in next-generation T2I models. Code and data are available at https://github.com/PKU-YuanGroup/WISE.
Discrepancy-Aware Attention Network for Enhanced Audio-Visual Zero-Shot Learning
Dec 16, 2024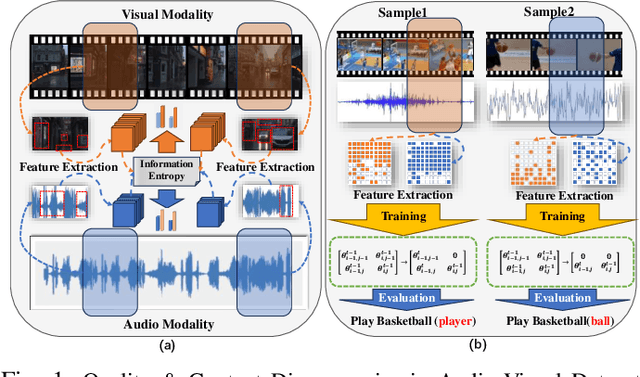
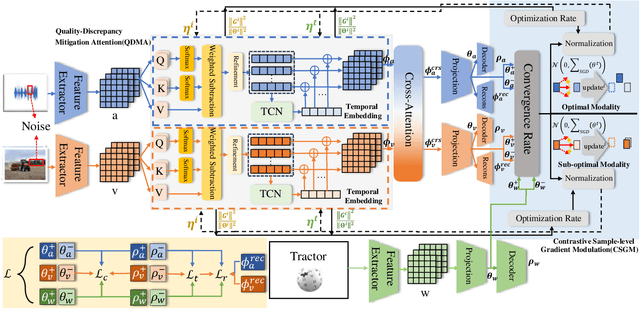
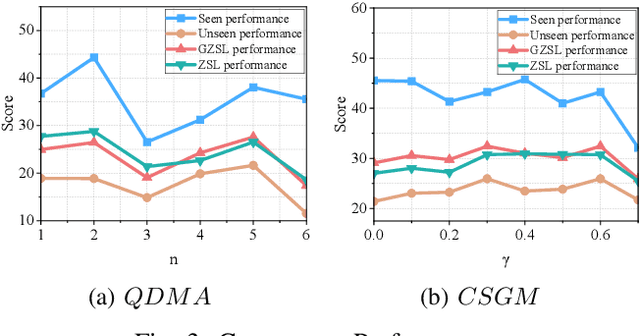
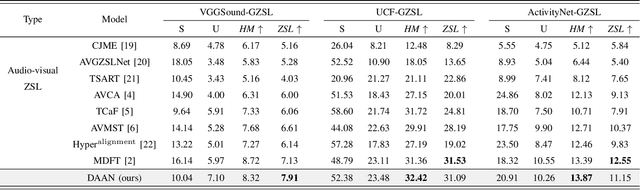
Audio-visual Zero-Shot Learning (ZSL) has attracted significant attention for its ability to identify unseen classes and perform well in video classification tasks. However, modal imbalance in (G)ZSL leads to over-reliance on the optimal modality, reducing discriminative capabilities for unseen classes. Some studies have attempted to address this issue by modifying parameter gradients, but two challenges still remain: (a) Quality discrepancies, where modalities offer differing quantities and qualities of information for the same concept. (b) Content discrepancies, where sample contributions within a modality vary significantly. To address these challenges, we propose a Discrepancy-Aware Attention Network (DAAN) for Enhanced Audio-Visual ZSL. Our approach introduces a Quality-Discrepancy Mitigation Attention (QDMA) unit to minimize redundant information in the high-quality modality and a Contrastive Sample-level Gradient Modulation (CSGM) block to adjust gradient magnitudes and balance content discrepancies. We quantify modality contributions by integrating optimization and convergence rate for more precise gradient modulation in CSGM. Experiments demonstrates DAAN achieves state-of-the-art performance on benchmark datasets, with ablation studies validating the effectiveness of individual modules.