 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReusing Computation in Text-to-Image Diffusion for Efficient Generation of Image Sets
Aug 28, 2025Text-to-image diffusion models enable high-quality image generation but are computationally expensive. While prior work optimizes per-inference efficiency, we explore an orthogonal approach: reducing redundancy across correlated prompts. Our method leverages the coarse-to-fine nature of diffusion models, where early denoising steps capture shared structures among similar prompts. We propose a training-free approach that clusters prompts based on semantic similarity and shares computation in early diffusion steps. Experiments show that for models trained conditioned on image embeddings, our approach significantly reduces compute cost while improving image quality. By leveraging UnClip's text-to-image prior, we enhance diffusion step allocation for greater efficiency. Our method seamlessly integrates with existing pipelines, scales with prompt sets, and reduces the environmental and financial burden of large-scale text-to-image generation. Project page: https://ddecatur.github.io/hierarchical-diffusion/
iSeg: Interactive 3D Segmentation via Interactive Attention
Apr 04, 2024We present iSeg, a new interactive technique for segmenting 3D shapes. Previous works have focused mainly on leveraging pre-trained 2D foundation models for 3D segmentation based on text. However, text may be insufficient for accurately describing fine-grained spatial segmentations. Moreover, achieving a consistent 3D segmentation using a 2D model is challenging since occluded areas of the same semantic region may not be visible together from any 2D view. Thus, we design a segmentation method conditioned on fine user clicks, which operates entirely in 3D. Our system accepts user clicks directly on the shape's surface, indicating the inclusion or exclusion of regions from the desired shape partition. To accommodate various click settings, we propose a novel interactive attention module capable of processing different numbers and types of clicks, enabling the training of a single unified interactive segmentation model. We apply iSeg to a myriad of shapes from different domains, demonstrating its versatility and faithfulness to the user's specifications. Our project page is at https://threedle.github.io/iSeg/.
3D Paintbrush: Local Stylization of 3D Shapes with Cascaded Score Distillation
Nov 16, 2023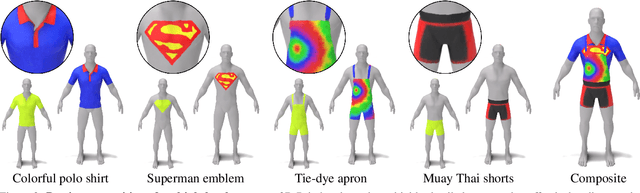
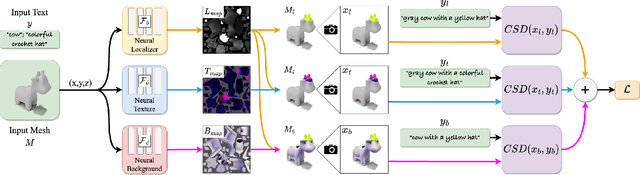
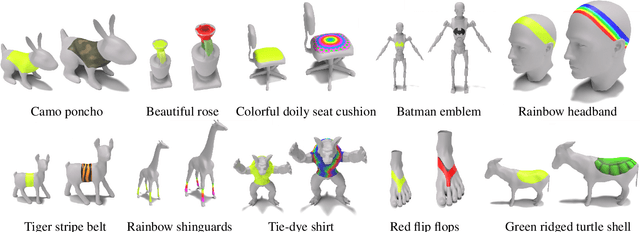
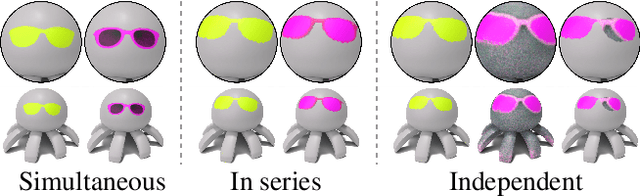
In this work we develop 3D Paintbrush, a technique for automatically texturing local semantic regions on meshes via text descriptions. Our method is designed to operate directly on meshes, producing texture maps which seamlessly integrate into standard graphics pipelines. We opt to simultaneously produce a localization map (to specify the edit region) and a texture map which conforms to it. This synergistic approach improves the quality of both the localization and the stylization. To enhance the details and resolution of the textured area, we leverage multiple stages of a cascaded diffusion model to supervise our local editing technique with generative priors learned from images at different resolutions. Our technique, referred to as Cascaded Score Distillation (CSD), simultaneously distills scores at multiple resolutions in a cascaded fashion, enabling control over both the granularity and global understanding of the supervision. We demonstrate the effectiveness of 3D Paintbrush to locally texture a variety of shapes within different semantic regions. Project page: https://threedle.github.io/3d-paintbrush
3D Highlighter: Localizing Regions on 3D Shapes via Text Descriptions
Dec 21, 2022
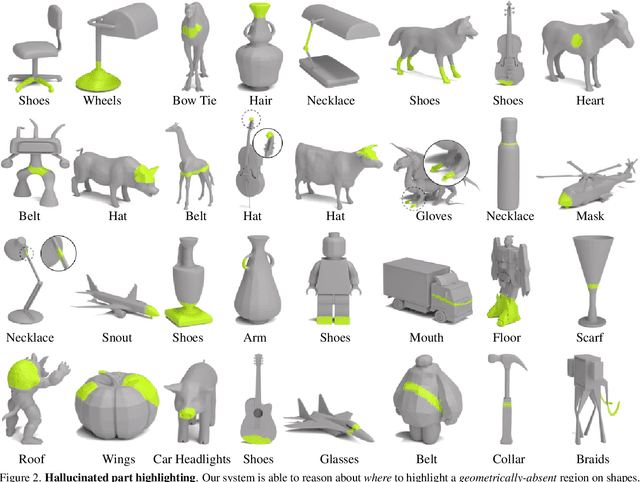
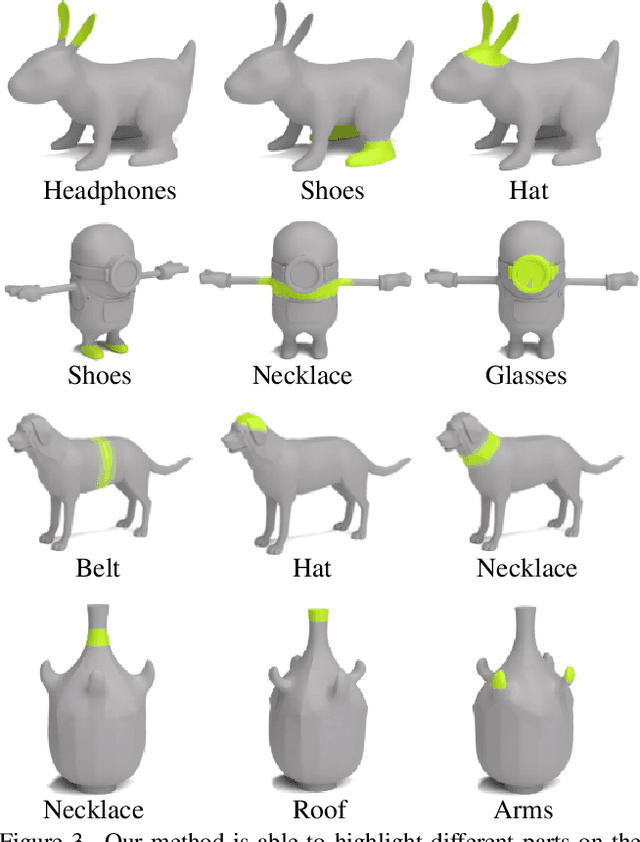

We present 3D Highlighter, a technique for localizing semantic regions on a mesh using text as input. A key feature of our system is the ability to interpret "out-of-domain" localizations. Our system demonstrates the ability to reason about where to place non-obviously related concepts on an input 3D shape, such as adding clothing to a bare 3D animal model. Our method contextualizes the text description using a neural field and colors the corresponding region of the shape using a probability-weighted blend. Our neural optimization is guided by a pre-trained CLIP encoder, which bypasses the need for any 3D datasets or 3D annotations. Thus, 3D Highlighter is highly flexible, general, and capable of producing localizations on a myriad of input shapes. Our code is publicly available at https://github.com/threedle/3DHighlighter.
VizExtract: Automatic Relation Extraction from Data Visualizations
Dec 07, 2021

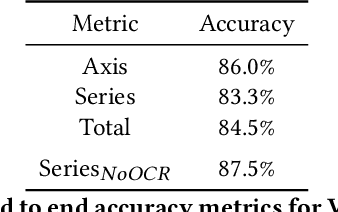
Visual graphics, such as plots, charts, and figures, are widely used to communicate statistical conclusions. Extracting information directly from such visualizations is a key sub-problem for effective search through scientific corpora, fact-checking, and data extraction. This paper presents a framework for automatically extracting compared variables from statistical charts. Due to the diversity and variation of charting styles, libraries, and tools, we leverage a computer vision based framework to automatically identify and localize visualization facets in line graphs, scatter plots, or bar graphs and can include multiple series per graph. The framework is trained on a large synthetically generated corpus of matplotlib charts and we evaluate the trained model on other chart datasets. In controlled experiments, our framework is able to classify, with 87.5% accuracy, the correlation between variables for graphs with 1-3 series per graph, varying colors, and solid line styles. When deployed on real-world graphs scraped from the internet, it achieves 72.8% accuracy (81.2% accuracy when excluding "hard" graphs). When deployed on the FigureQA dataset, it achieves 84.7% accuracy.