 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolTailor: Tailoring Chemical Molecular Representation to Specific Tasks via Text Prompts
Jan 21, 2024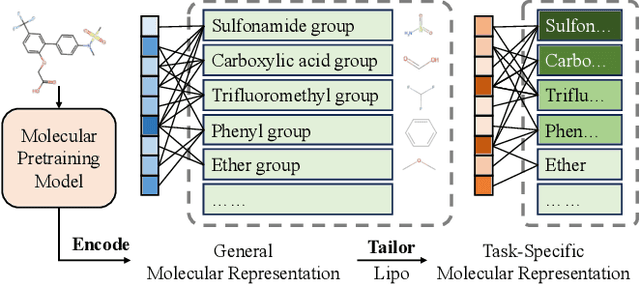

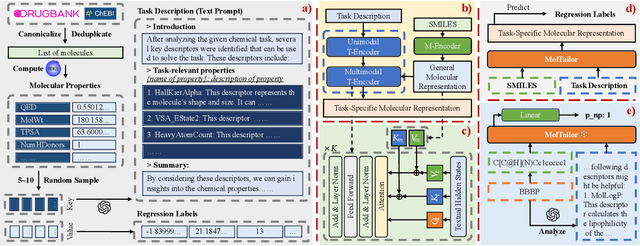
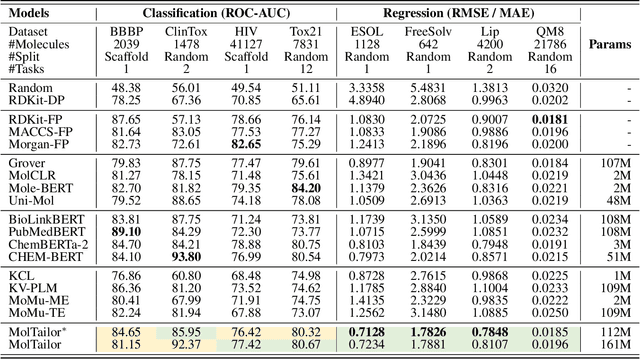
Deep learning is now widely used in drug discovery, providing significant acceleration and cost reduction. As the most fundamental building block, molecular representation is essential for predicting molecular properties to enable various downstream applications. Most existing methods attempt to incorporate more information to learn better representations. However, not all features are equally important for a specific task. Ignoring this would potentially compromise the training efficiency and predictive accuracy. To address this issue, we propose a novel approach, which treats language models as an agent and molecular pretraining models as a knowledge base. The agent accentuates task-relevant features in the molecular representation by understanding the natural language description of the task, just as a tailor customizes clothes for clients. Thus, we call this approach MolTailor. Evaluations demonstrate MolTailor's superior performance over baselines, validating the efficacy of enhancing relevance for molecular representation learning. This illustrates the potential of language model guided optimization to better exploit and unleash the capabilities of existing powerful molecular representation methods. Our codes and appendix are available at https://github.com/SCIR-HI/MolTailor.
The CALLA Dataset: Probing LLMs' Interactive Knowledge Acquisition from Chinese Medical Literature
Sep 12, 2023


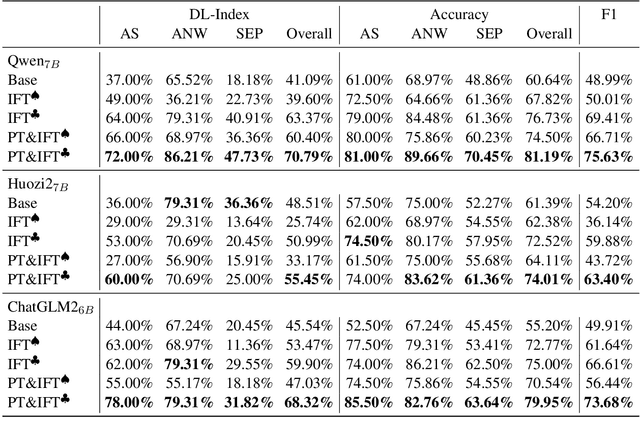
The application of Large Language Models (LLMs) to the medical domain has stimulated the interest of researchers. Recent studies have focused on constructing Instruction Fine-Tuning (IFT) data through medical knowledge graphs to enrich the interactive medical knowledge of LLMs. However, the medical literature serving as a rich source of medical knowledge remains unexplored. Our work introduces the CALLA dataset to probe LLMs' interactive knowledge acquisition from Chinese medical literature. It assesses the proficiency of LLMs in mastering medical knowledge through a free-dialogue fact-checking task. We identify a phenomenon called the ``fact-following response``, where LLMs tend to affirm facts mentioned in questions and display a reluctance to challenge them. To eliminate the inaccurate evaluation caused by this phenomenon, for the golden fact, we artificially construct test data from two perspectives: one consistent with the fact and one inconsistent with the fact. Drawing from the probing experiment on the CALLA dataset, we conclude that IFT data highly correlated with the medical literature corpus serves as a potent catalyst for LLMs, enabling themselves to skillfully employ the medical knowledge acquired during the pre-training phase within interactive scenarios, enhancing accuracy. Furthermore, we design a framework for automatically constructing IFT data based on medical literature and discuss some real-world applications.
Knowledge-tuning Large Language Models with Structured Medical Knowledge Bases for Reliable Response Generation in Chinese
Sep 08, 2023



Large Language Models (LLMs) have demonstrated remarkable success in diverse natural language processing (NLP) tasks in general domains. However, LLMs sometimes generate responses with the hallucination about medical facts due to limited domain knowledge. Such shortcomings pose potential risks in the utilization of LLMs within medical contexts. To address this challenge, we propose knowledge-tuning, which leverages structured medical knowledge bases for the LLMs to grasp domain knowledge efficiently and facilitate reliable response generation. We also release cMedKnowQA, a Chinese medical knowledge question-answering dataset constructed from medical knowledge bases to assess the medical knowledge proficiency of LLMs. Experimental results show that the LLMs which are knowledge-tuned with cMedKnowQA, can exhibit higher levels of accuracy in response generation compared with vanilla instruction-tuning and offer a new reliable way for the domain adaptation of LLMs.
Hardware Accelerator for Adversarial Attacks on Deep Learning Neural Networks
Aug 03, 2020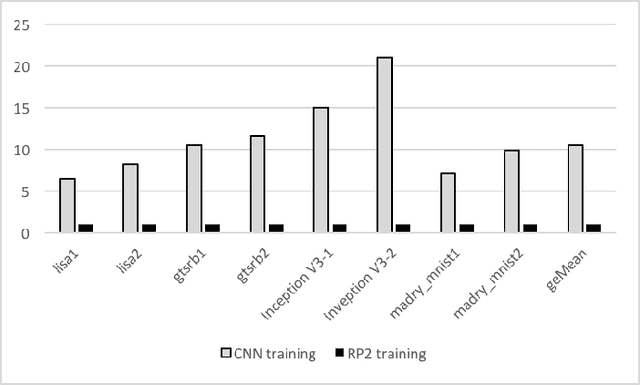
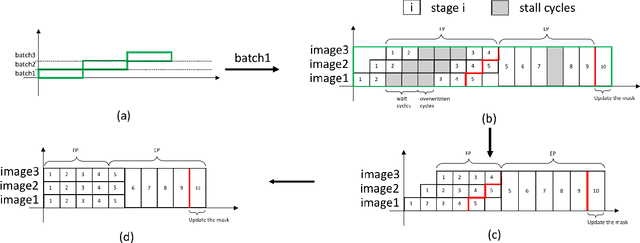
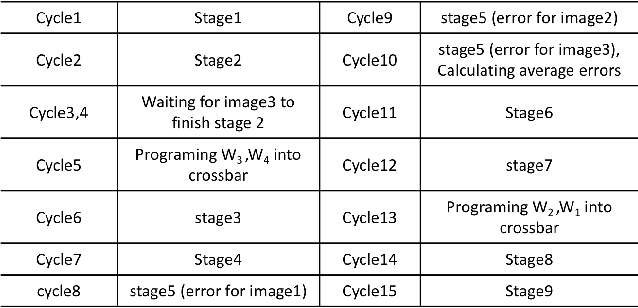
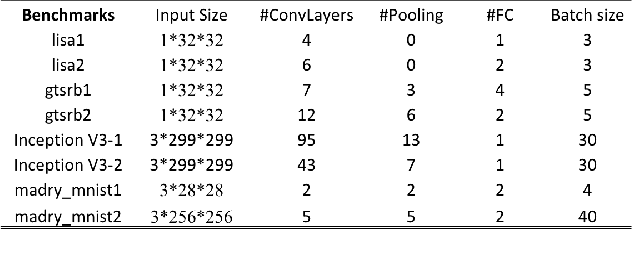
Recent studies identify that Deep learning Neural Networks (DNNs) are vulnerable to subtle perturbations, which are not perceptible to human visual system but can fool the DNN models and lead to wrong outputs. A class of adversarial attack network algorithms has been proposed to generate robust physical perturbations under different circumstances. These algorithms are the first efforts to move forward secure deep learning by providing an avenue to train future defense networks, however, the intrinsic complexity of them prevents their broader usage. In this paper, we propose the first hardware accelerator for adversarial attacks based on memristor crossbar arrays. Our design significantly improves the throughput of a visual adversarial perturbation system, which can further improve the robustness and security of future deep learning systems. Based on the algorithm uniqueness, we propose four implementations for the adversarial attack accelerator ($A^3$) to improve the throughput, energy efficiency, and computational efficiency.
* IGSC'2019 (https://shirazi21.wixsite.com/igsc2019archive) Best paper award