 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolFusion: Multimodal Fusion Learning for Molecular Representations via Multi-granularity Views
Jun 26, 2024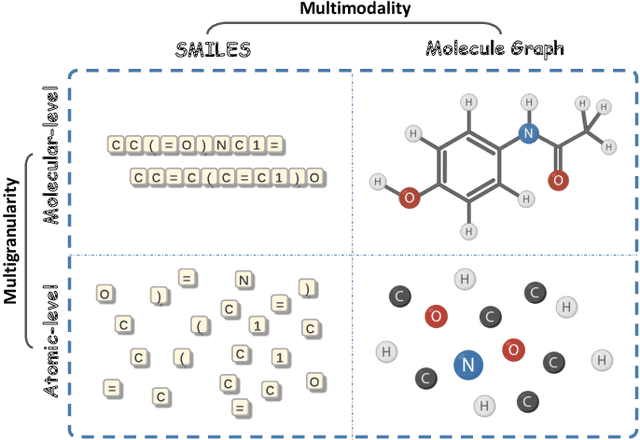
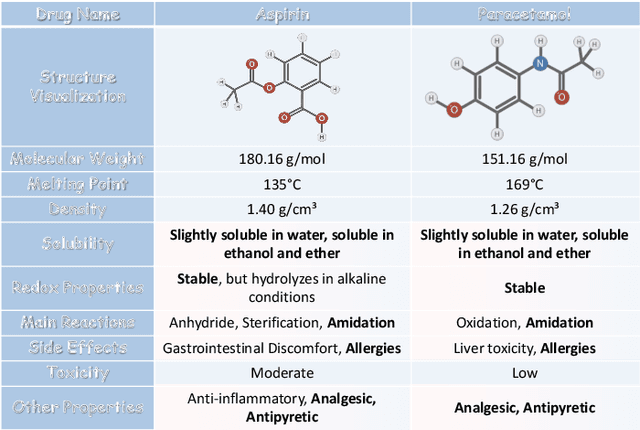
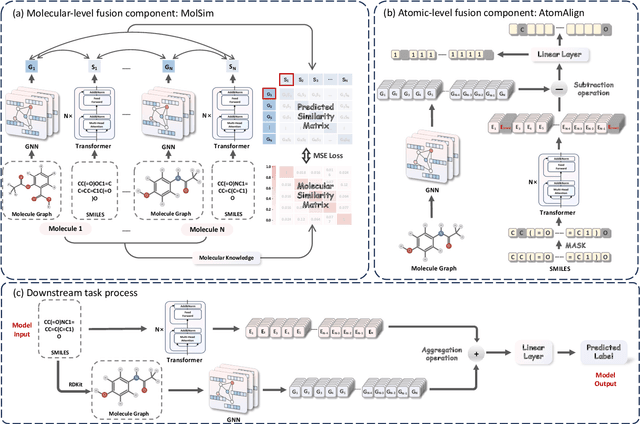
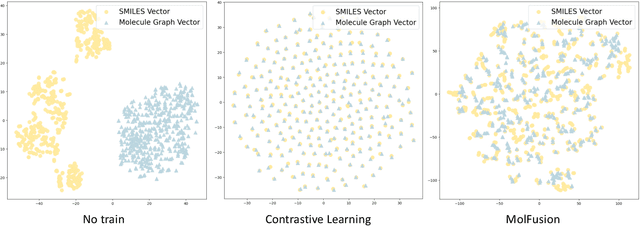
Artificial Intelligence predicts drug properties by encoding drug molecules, aiding in the rapid screening of candidates. Different molecular representations, such as SMILES and molecule graphs, contain complementary information for molecular encoding. Thus exploiting complementary information from different molecular representations is one of the research priorities in molecular encoding. Most existing methods for combining molecular multi-modalities only use molecular-level information, making it hard to encode intra-molecular alignment information between different modalities. To address this issue, we propose a multi-granularity fusion method that is MolFusion. The proposed MolFusion consists of two key components: (1) MolSim, a molecular-level encoding component that achieves molecular-level alignment between different molecular representations. and (2) AtomAlign, an atomic-level encoding component that achieves atomic-level alignment between different molecular representations. Experimental results show that MolFusion effectively utilizes complementary multimodal information, leading to significant improvements in performance across various classification and regression tasks.
Make Your Decision Convincing! A Unified Two-Stage Framework: Self-Attribution and Decision-Making
Oct 20, 2023
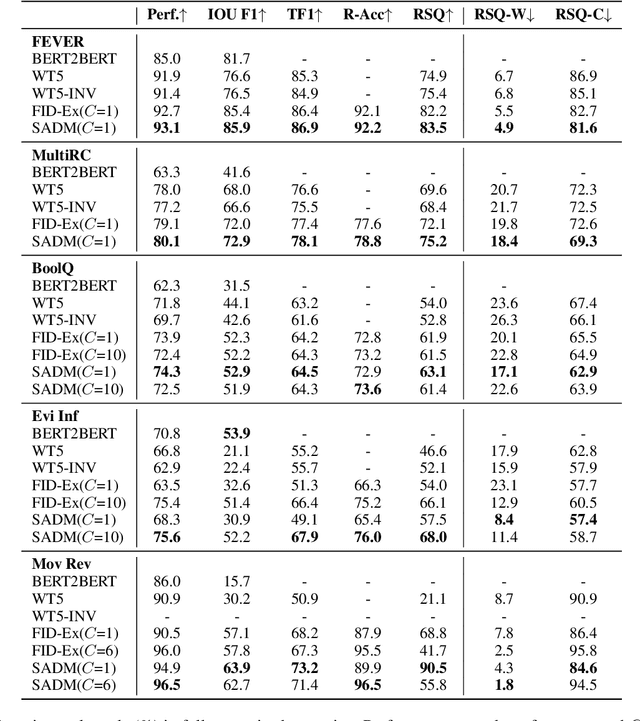
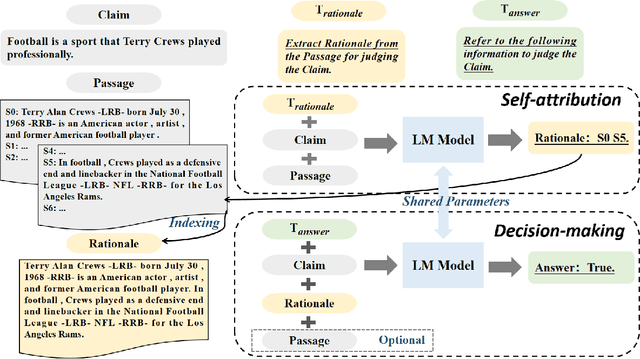
Explaining black-box model behavior with natural language has achieved impressive results in various NLP tasks. Recent research has explored the utilization of subsequences from the input text as a rationale, providing users with evidence to support the model decision. Although existing frameworks excel in generating high-quality rationales while achieving high task performance, they neglect to account for the unreliable link between the generated rationale and model decision. In simpler terms, a model may make correct decisions while attributing wrong rationales, or make poor decisions while attributing correct rationales. To mitigate this issue, we propose a unified two-stage framework known as Self-Attribution and Decision-Making (SADM). Through extensive experiments on five reasoning datasets from the ERASER benchmark, we demonstrate that our framework not only establishes a more reliable link between the generated rationale and model decision but also achieves competitive results in task performance and the quality of rationale. Furthermore, we explore the potential of our framework in semi-supervised scenarios.
The CALLA Dataset: Probing LLMs' Interactive Knowledge Acquisition from Chinese Medical Literature
Sep 12, 2023The application of Large Language Models (LLMs) to the medical domain has stimulated the interest of researchers. Recent studies have focused on constructing Instruction Fine-Tuning (IFT) data through medical knowledge graphs to enrich the interactive medical knowledge of LLMs. However, the medical literature serving as a rich source of medical knowledge remains unexplored. Our work introduces the CALLA dataset to probe LLMs' interactive knowledge acquisition from Chinese medical literature. It assesses the proficiency of LLMs in mastering medical knowledge through a free-dialogue fact-checking task. We identify a phenomenon called the ``fact-following response``, where LLMs tend to affirm facts mentioned in questions and display a reluctance to challenge them. To eliminate the inaccurate evaluation caused by this phenomenon, for the golden fact, we artificially construct test data from two perspectives: one consistent with the fact and one inconsistent with the fact. Drawing from the probing experiment on the CALLA dataset, we conclude that IFT data highly correlated with the medical literature corpus serves as a potent catalyst for LLMs, enabling themselves to skillfully employ the medical knowledge acquired during the pre-training phase within interactive scenarios, enhancing accuracy. Furthermore, we design a framework for automatically constructing IFT data based on medical literature and discuss some real-world applications.
Manifold-based Verbalizer Space Re-embedding for Tuning-free Prompt-based Classification
Sep 08, 2023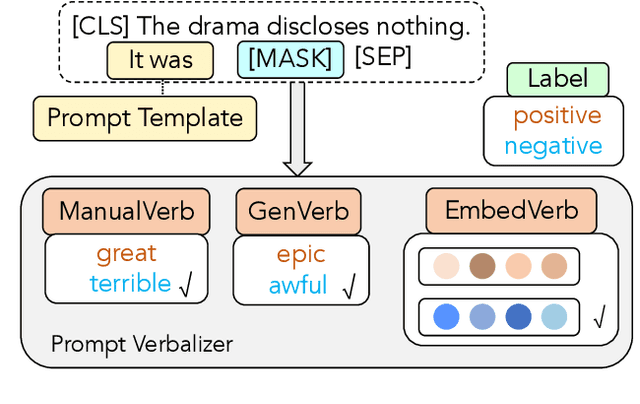
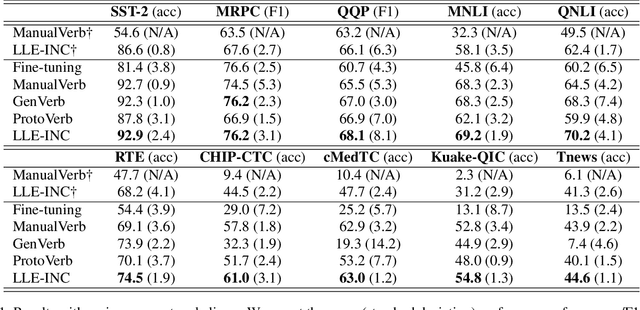
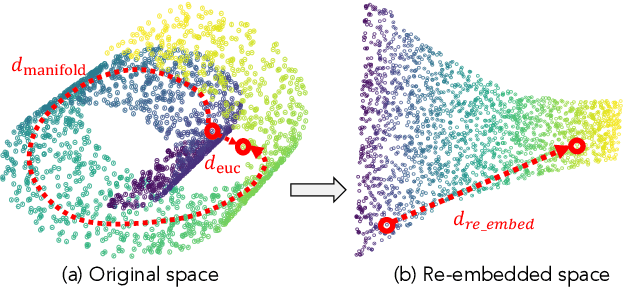
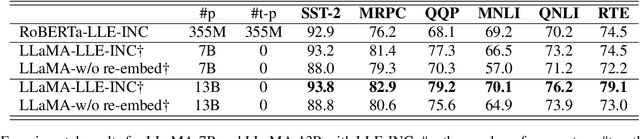
Prompt-based classification adapts tasks to a cloze question format utilizing the [MASK] token and the filled tokens are then mapped to labels through pre-defined verbalizers. Recent studies have explored the use of verbalizer embeddings to reduce labor in this process. However, all existing studies require a tuning process for either the pre-trained models or additional trainable embeddings. Meanwhile, the distance between high-dimensional verbalizer embeddings should not be measured by Euclidean distance due to the potential for non-linear manifolds in the representation space. In this study, we propose a tuning-free manifold-based space re-embedding method called Locally Linear Embedding with Intra-class Neighborhood Constraint (LLE-INC) for verbalizer embeddings, which preserves local properties within the same class as guidance for classification. Experimental results indicate that even without tuning any parameters, our LLE-INC is on par with automated verbalizers with parameter tuning. And with the parameter updating, our approach further enhances prompt-based tuning by up to 3.2%. Furthermore, experiments with the LLaMA-7B&13B indicate that LLE-INC is an efficient tuning-free classification approach for the hyper-scale language models.