 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Latent Signals to Reflection Behavior: Tracing Meta-Cognitive Activation Trajectory in R1-Style LLMs
Feb 02, 2026R1-style LLMs have attracted growing attention for their capacity for self-reflection, yet the internal mechanisms underlying such behavior remain unclear. To bridge this gap, we anchor on the onset of reflection behavior and trace its layer-wise activation trajectory. Using the logit lens to read out token-level semantics, we uncover a structured progression: (i) Latent-control layers, where an approximate linear direction encodes the semantics of thinking budget; (ii) Semantic-pivot layers, where discourse-level cues, including turning-point and summarization cues, surface and dominate the probability mass; and (iii) Behavior-overt layers, where the likelihood of reflection-behavior tokens begins to rise until they become highly likely to be sampled. Moreover, our targeted interventions uncover a causal chain across these stages: prompt-level semantics modulate the projection of activations along latent-control directions, thereby inducing competition between turning-point and summarization cues in semantic-pivot layers, which in turn regulates the sampling likelihood of reflection-behavior tokens in behavior-overt layers. Collectively, our findings suggest a human-like meta-cognitive process-progressing from latent monitoring, to discourse-level regulation, and to finally overt self-reflection. Our analysis code can be found at https://github.com/DYR1/S3-CoT.
OptiSet: Unified Optimizing Set Selection and Ranking for Retrieval-Augmented Generation
Jan 08, 2026Retrieval-Augmented Generation (RAG) improves generation quality by incorporating evidence retrieved from large external corpora. However, most existing methods rely on statically selecting top-k passages based on individual relevance, which fails to exploit combinatorial gains among passages and often introduces substantial redundancy. To address this limitation, we propose OptiSet, a set-centric framework that unifies set selection and set-level ranking for RAG. OptiSet adopts an "Expand-then-Refine" paradigm: it first expands a query into multiple perspectives to enable a diverse candidate pool and then refines the candidate pool via re-selection to form a compact evidence set. We then devise a self-synthesis strategy without strong LLM supervision to derive preference labels from the set conditional utility changes of the generator, thereby identifying complementary and redundant evidence. Finally, we introduce a set-list wise training strategy that jointly optimizes set selection and set-level ranking, enabling the model to favor compact, high-gain evidence sets. Extensive experiments demonstrate that OptiSet improves performance on complex combinatorial problems and makes generation more efficient. The source code is publicly available.
Orchestrating Intelligence: Confidence-Aware Routing for Efficient Multi-Agent Collaboration across Multi-Scale Models
Jan 08, 2026While multi-agent systems (MAS) have demonstrated superior performance over single-agent approaches in complex reasoning tasks, they often suffer from significant computational inefficiencies. Existing frameworks typically deploy large language models (LLMs) uniformly across all agent roles, failing to account for the varying cognitive demands of different reasoning stages. We address this inefficiency by proposing OI-MAS framework, a novel multi-agent framework that implements an adaptive model-selection policy across a heterogeneous pool of multi-scale LLMs. Specifically, OI-MAS introduces a state-dependent routing mechanism that dynamically selects agent roles and model scales throughout the reasoning process. In addition, we introduce a confidence-aware mechanism that selects appropriate model scales conditioned on task complexity, thus reducing unnecessary reliance on large-scale models. Experimental results show that OI-MAS consistently outperforms baseline multi-agent systems, improving accuracy by up to 12.88\% while reducing cost by up to 79.78\%.
ArcAligner: Adaptive Recursive Aligner for Compressed Context Embeddings in RAG
Jan 08, 2026Retrieval-Augmented Generation (RAG) helps LLMs stay accurate, but feeding long documents into a prompt makes the model slow and expensive. This has motivated context compression, ranging from token pruning and summarization to embedding-based compression. While researchers have tried ''compressing'' these documents into smaller summaries or mathematical embeddings, there is a catch: the more you compress the data, the more the LLM struggles to understand it. To address this challenge, we propose ArcAligner (Adaptive recursive context *Aligner*), a lightweight module integrated into the language model layers to help the model better utilize highly compressed context representations for downstream generation. It uses an adaptive ''gating'' system that only adds extra processing power when the information is complex, keeping the system fast. Across knowledge-intensive QA benchmarks, ArcAligner consistently beats compression baselines at comparable compression rates, especially on multi-hop and long-tail settings. The source code is publicly available.
Uncovering the Role of Initial Saliency in U-Shaped Attention Bias: Scaling Initial Token Weight for Enhanced Long-Text Processing
Dec 15, 2025Large language models (LLMs) have demonstrated strong performance on a variety of natural language processing (NLP) tasks. However, they often struggle with long-text sequences due to the ``lost in the middle'' phenomenon. This issue has been shown to arise from a U-shaped attention bias, where attention is disproportionately focused on the beginning and end of a text, leaving the middle section underrepresented. While previous studies have attributed this bias to position encoding, our research first identifies an additional factor: initial saliency. It means that in the attention computation for each token, tokens with higher attention weights relative to the initial token tend to receive more attention in the prediction of the next token. We further find that utilizing this property by scaling attention weight between the initial token and others improves the model's ability to process long contexts, achieving a maximum improvement of 3.6\% in MDQA dataset. Moreover, combining this approach with existing methods to reduce position encoding bias further enhances performance, achieving a maximum improvement of 3.4\% in KV-Retrieval tasks.
GainRAG: Preference Alignment in Retrieval-Augmented Generation through Gain Signal Synthesis
May 24, 2025



The Retrieval-Augmented Generation (RAG) framework introduces a retrieval module to dynamically inject retrieved information into the input context of large language models (LLMs), and has demonstrated significant success in various NLP tasks. However, the current study points out that there is a preference gap between retrievers and LLMs in the RAG framework, which limit the further improvement of system performance. Some highly relevant passages may interfere with LLM reasoning because they contain complex or contradictory information; while some indirectly related or even inaccurate content may help LLM generate more accurate answers by providing suggestive information or logical clues. To solve this, we propose GainRAG, a novel approach that aligns the retriever's and LLM's preferences by defining a new metric, "gain", which measure how well an input passage contributes to correct outputs. Specifically, we propose a method to estimate these gain signals and train a middleware that aligns the preferences of the retriever and the LLM using only limited data. In addition, we introduce a pseudo-passage strategy to mitigate degradation. The experimental results on 6 datasets verify the effectiveness of GainRAG.
Beyond Frameworks: Unpacking Collaboration Strategies in Multi-Agent Systems
May 18, 2025Multi-agent collaboration has emerged as a pivotal paradigm for addressing complex, distributed tasks in large language model (LLM)-driven applications. While prior research has focused on high-level architectural frameworks, the granular mechanisms governing agents, critical to performance and scalability, remain underexplored. This study systematically investigates four dimensions of collaboration strategies: (1) agent governance, (2) participation control, (3) interaction dynamics, and (4) dialogue history management. Through rigorous experimentation under two context-dependent scenarios: Distributed Evidence Integration (DEI) and Structured Evidence Synthesis (SES), we quantify the impact of these strategies on both task accuracy and computational efficiency. Our findings reveal that centralized governance, instructor-led participation, ordered interaction patterns, and instructor-curated context summarization collectively optimize the trade-off between decision quality and resource utilization with the support of the proposed Token-Accuracy Ratio (TAR). This work establishes a foundation for designing adaptive, scalable multi-agent systems, shifting the focus from structural novelty to strategic interaction mechanics.
MolFusion: Multimodal Fusion Learning for Molecular Representations via Multi-granularity Views
Jun 26, 2024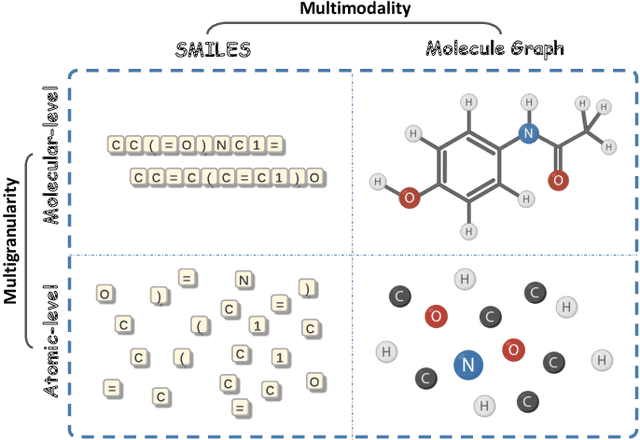
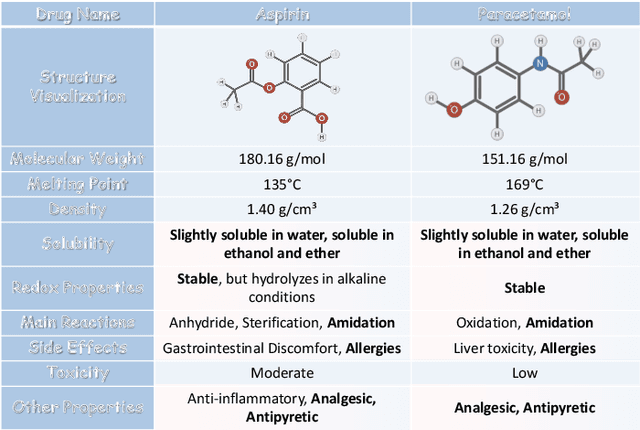
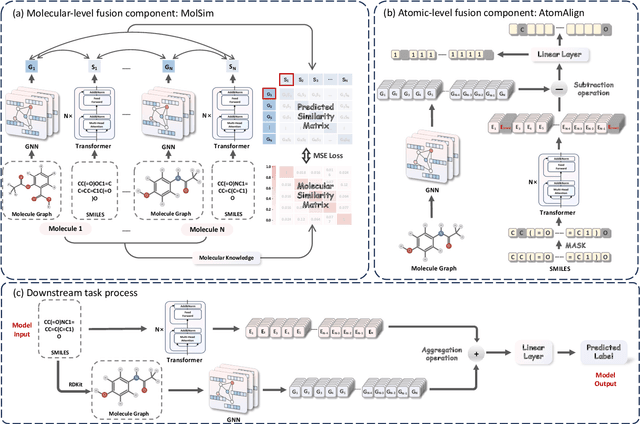
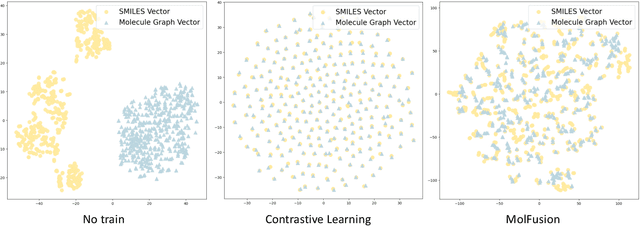
Artificial Intelligence predicts drug properties by encoding drug molecules, aiding in the rapid screening of candidates. Different molecular representations, such as SMILES and molecule graphs, contain complementary information for molecular encoding. Thus exploiting complementary information from different molecular representations is one of the research priorities in molecular encoding. Most existing methods for combining molecular multi-modalities only use molecular-level information, making it hard to encode intra-molecular alignment information between different modalities. To address this issue, we propose a multi-granularity fusion method that is MolFusion. The proposed MolFusion consists of two key components: (1) MolSim, a molecular-level encoding component that achieves molecular-level alignment between different molecular representations. and (2) AtomAlign, an atomic-level encoding component that achieves atomic-level alignment between different molecular representations. Experimental results show that MolFusion effectively utilizes complementary multimodal information, leading to significant improvements in performance across various classification and regression tasks.
AS-ES Learning: Towards Efficient CoT Learning in Small Models
Mar 04, 2024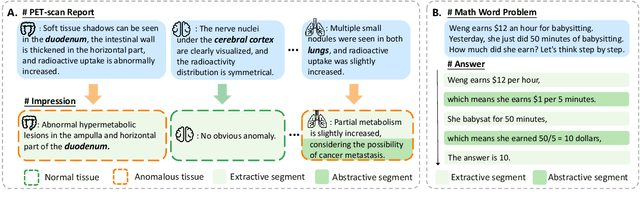
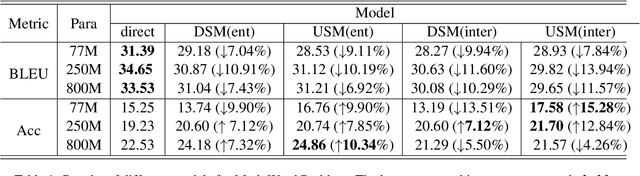
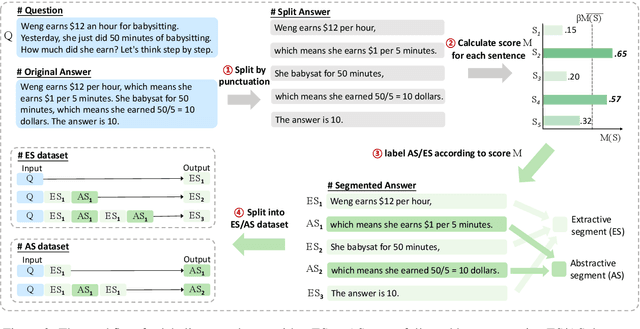

Chain-of-Thought (CoT) serves as a critical emerging ability in LLMs, especially when it comes to logical reasoning. Attempts have been made to induce such ability in small models as well by distilling from the data with CoT generated by Large Language Models (LLMs). However, existing methods often simply generate and incorporate more data from LLMs and fail to note the importance of efficiently utilizing existing CoT data. We here propose a new training paradigm AS-ES (Abstractive Segments - Extractive Segments) learning, which exploits the inherent information in CoT for iterative generation. Experiments show that our methods surpass the direct seq2seq training on CoT-extensive tasks like MWP and PET summarization, without data augmentation or altering the model itself. Furthermore, we explore the reason behind the inefficiency of small models in learning CoT and provide an explanation of why AS-ES learning works, giving insights into the underlying mechanism of CoT.
Beyond the Answers: Reviewing the Rationality of Multiple Choice Question Answering for the Evaluation of Large Language Models
Feb 02, 2024



In the field of natural language processing (NLP), Large Language Models (LLMs) have precipitated a paradigm shift, markedly enhancing performance in natural language generation tasks. Despite these advancements, the comprehensive evaluation of LLMs remains an inevitable challenge for the community. Recently, the utilization of Multiple Choice Question Answering (MCQA) as a benchmark for LLMs has gained considerable traction. This study investigates the rationality of MCQA as an evaluation method for LLMs. If LLMs genuinely understand the semantics of questions, their performance should exhibit consistency across the varied configurations derived from the same questions. Contrary to this expectation, our empirical findings suggest a notable disparity in the consistency of LLM responses, which we define as REsponse VAriability Syndrome (REVAS) of the LLMs, indicating that current MCQA-based benchmarks may not adequately capture the true capabilities of LLMs, which underscores the need for more robust evaluation mechanisms in assessing the performance of LLMs.