 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering the Role of Initial Saliency in U-Shaped Attention Bias: Scaling Initial Token Weight for Enhanced Long-Text Processing
Dec 15, 2025Large language models (LLMs) have demonstrated strong performance on a variety of natural language processing (NLP) tasks. However, they often struggle with long-text sequences due to the ``lost in the middle'' phenomenon. This issue has been shown to arise from a U-shaped attention bias, where attention is disproportionately focused on the beginning and end of a text, leaving the middle section underrepresented. While previous studies have attributed this bias to position encoding, our research first identifies an additional factor: initial saliency. It means that in the attention computation for each token, tokens with higher attention weights relative to the initial token tend to receive more attention in the prediction of the next token. We further find that utilizing this property by scaling attention weight between the initial token and others improves the model's ability to process long contexts, achieving a maximum improvement of 3.6\% in MDQA dataset. Moreover, combining this approach with existing methods to reduce position encoding bias further enhances performance, achieving a maximum improvement of 3.4\% in KV-Retrieval tasks.
Beyond Frameworks: Unpacking Collaboration Strategies in Multi-Agent Systems
May 18, 2025Multi-agent collaboration has emerged as a pivotal paradigm for addressing complex, distributed tasks in large language model (LLM)-driven applications. While prior research has focused on high-level architectural frameworks, the granular mechanisms governing agents, critical to performance and scalability, remain underexplored. This study systematically investigates four dimensions of collaboration strategies: (1) agent governance, (2) participation control, (3) interaction dynamics, and (4) dialogue history management. Through rigorous experimentation under two context-dependent scenarios: Distributed Evidence Integration (DEI) and Structured Evidence Synthesis (SES), we quantify the impact of these strategies on both task accuracy and computational efficiency. Our findings reveal that centralized governance, instructor-led participation, ordered interaction patterns, and instructor-curated context summarization collectively optimize the trade-off between decision quality and resource utilization with the support of the proposed Token-Accuracy Ratio (TAR). This work establishes a foundation for designing adaptive, scalable multi-agent systems, shifting the focus from structural novelty to strategic interaction mechanics.
MolFusion: Multimodal Fusion Learning for Molecular Representations via Multi-granularity Views
Jun 26, 2024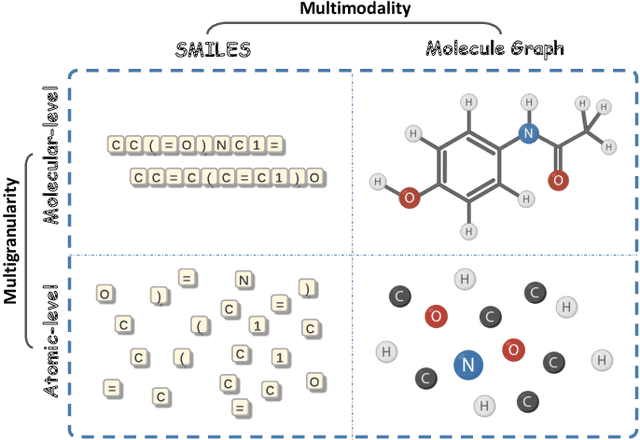
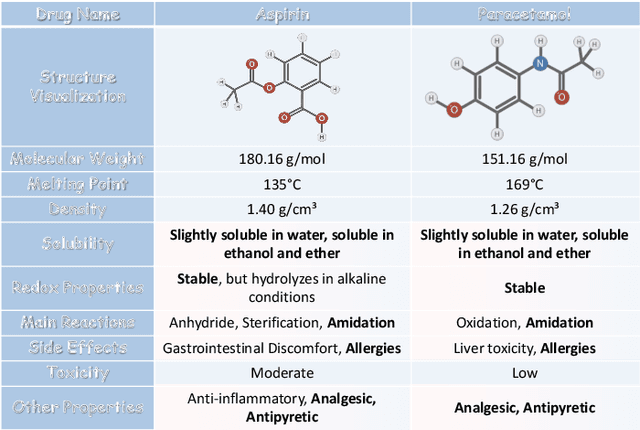
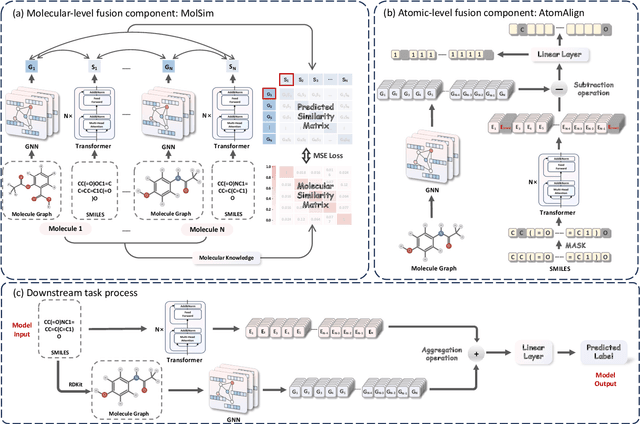
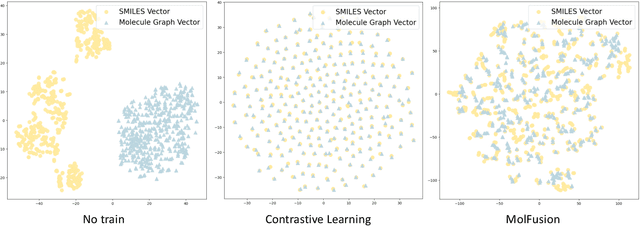
Artificial Intelligence predicts drug properties by encoding drug molecules, aiding in the rapid screening of candidates. Different molecular representations, such as SMILES and molecule graphs, contain complementary information for molecular encoding. Thus exploiting complementary information from different molecular representations is one of the research priorities in molecular encoding. Most existing methods for combining molecular multi-modalities only use molecular-level information, making it hard to encode intra-molecular alignment information between different modalities. To address this issue, we propose a multi-granularity fusion method that is MolFusion. The proposed MolFusion consists of two key components: (1) MolSim, a molecular-level encoding component that achieves molecular-level alignment between different molecular representations. and (2) AtomAlign, an atomic-level encoding component that achieves atomic-level alignment between different molecular representations. Experimental results show that MolFusion effectively utilizes complementary multimodal information, leading to significant improvements in performance across various classification and regression tasks.
Beyond the Answers: Reviewing the Rationality of Multiple Choice Question Answering for the Evaluation of Large Language Models
Feb 02, 2024



In the field of natural language processing (NLP), Large Language Models (LLMs) have precipitated a paradigm shift, markedly enhancing performance in natural language generation tasks. Despite these advancements, the comprehensive evaluation of LLMs remains an inevitable challenge for the community. Recently, the utilization of Multiple Choice Question Answering (MCQA) as a benchmark for LLMs has gained considerable traction. This study investigates the rationality of MCQA as an evaluation method for LLMs. If LLMs genuinely understand the semantics of questions, their performance should exhibit consistency across the varied configurations derived from the same questions. Contrary to this expectation, our empirical findings suggest a notable disparity in the consistency of LLM responses, which we define as REsponse VAriability Syndrome (REVAS) of the LLMs, indicating that current MCQA-based benchmarks may not adequately capture the true capabilities of LLMs, which underscores the need for more robust evaluation mechanisms in assessing the performance of LLMs.
Beyond Direct Diagnosis: LLM-based Multi-Specialist Agent Consultation for Automatic Diagnosis
Jan 29, 2024Automatic diagnosis is a significant application of AI in healthcare, where diagnoses are generated based on the symptom description of patients. Previous works have approached this task directly by modeling the relationship between the normalized symptoms and all possible diseases. However, in the clinical diagnostic process, patients are initially consulted by a general practitioner and, if necessary, referred to specialists in specific domains for a more comprehensive evaluation. The final diagnosis often emerges from a collaborative consultation among medical specialist groups. Recently, large language models have shown impressive capabilities in natural language understanding. In this study, we adopt tuning-free LLM-based agents as medical practitioners and propose the Agent-derived Multi-Specialist Consultation (AMSC) framework to model the diagnosis process in the real world by adaptively fusing probability distributions of agents over potential diseases. Experimental results demonstrate the superiority of our approach compared with baselines. Notably, our approach requires significantly less parameter updating and training time, enhancing efficiency and practical utility. Furthermore, we delve into a novel perspective on the role of implicit symptoms within the context of automatic diagnosis.
Make Your Decision Convincing! A Unified Two-Stage Framework: Self-Attribution and Decision-Making
Oct 20, 2023
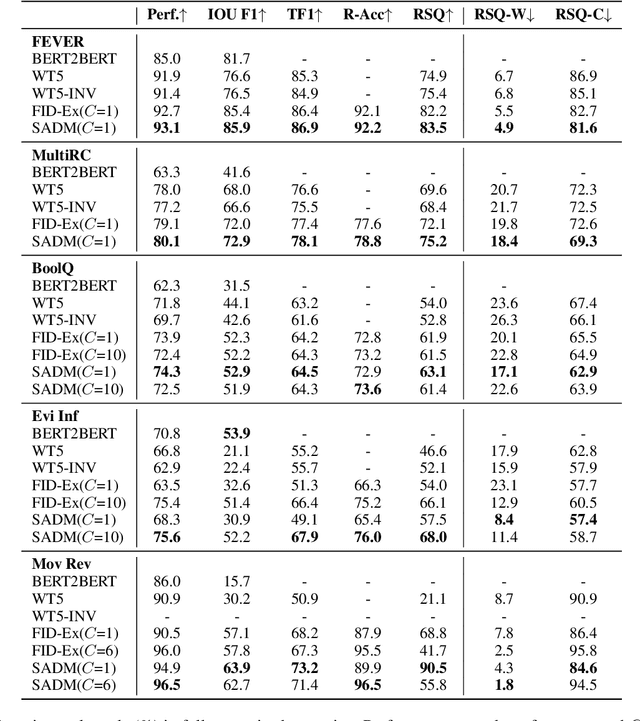
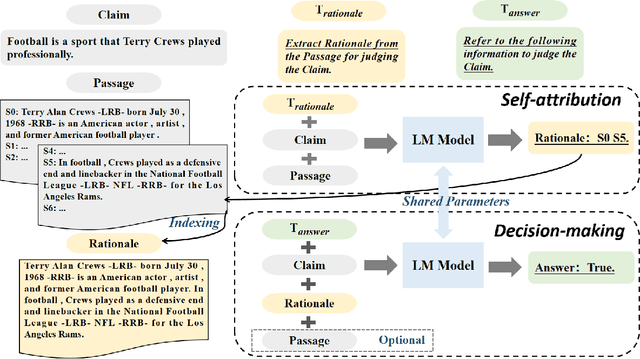
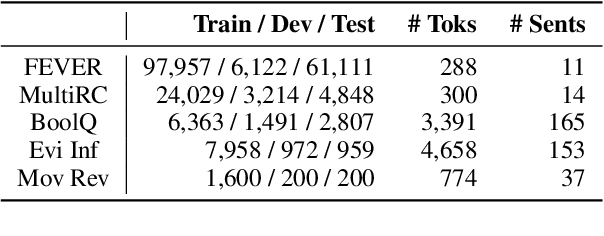
Explaining black-box model behavior with natural language has achieved impressive results in various NLP tasks. Recent research has explored the utilization of subsequences from the input text as a rationale, providing users with evidence to support the model decision. Although existing frameworks excel in generating high-quality rationales while achieving high task performance, they neglect to account for the unreliable link between the generated rationale and model decision. In simpler terms, a model may make correct decisions while attributing wrong rationales, or make poor decisions while attributing correct rationales. To mitigate this issue, we propose a unified two-stage framework known as Self-Attribution and Decision-Making (SADM). Through extensive experiments on five reasoning datasets from the ERASER benchmark, we demonstrate that our framework not only establishes a more reliable link between the generated rationale and model decision but also achieves competitive results in task performance and the quality of rationale. Furthermore, we explore the potential of our framework in semi-supervised scenarios.
Knowledge-tuning Large Language Models with Structured Medical Knowledge Bases for Reliable Response Generation in Chinese
Sep 08, 2023Large Language Models (LLMs) have demonstrated remarkable success in diverse natural language processing (NLP) tasks in general domains. However, LLMs sometimes generate responses with the hallucination about medical facts due to limited domain knowledge. Such shortcomings pose potential risks in the utilization of LLMs within medical contexts. To address this challenge, we propose knowledge-tuning, which leverages structured medical knowledge bases for the LLMs to grasp domain knowledge efficiently and facilitate reliable response generation. We also release cMedKnowQA, a Chinese medical knowledge question-answering dataset constructed from medical knowledge bases to assess the medical knowledge proficiency of LLMs. Experimental results show that the LLMs which are knowledge-tuned with cMedKnowQA, can exhibit higher levels of accuracy in response generation compared with vanilla instruction-tuning and offer a new reliable way for the domain adaptation of LLMs.
HuaTuo: Tuning LLaMA Model with Chinese Medical Knowledge
Apr 14, 2023Large Language Models (LLMs), such as the LLaMA model, have demonstrated their effectiveness in various general-domain natural language processing (NLP) tasks. Nevertheless, LLMs have not yet performed optimally in biomedical domain tasks due to the need for medical expertise in the responses. In response to this challenge, we propose HuaTuo, a LLaMA-based model that has been supervised-fine-tuned with generated QA (Question-Answer) instances. The experimental results demonstrate that HuaTuo generates responses that possess more reliable medical knowledge. Our proposed HuaTuo model is accessible at https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese.