 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSL-BiLEM: Structured Learnable Behavior-in-the-Loop Epidemic Modeling for Forecasting and Policy Evaluation
May 26, 2026Epidemic forecasting faces a fundamental challenge: human behavior dynamically responds to disease spread, creating feedback loops that induce distribution shifts at policy intervention points. This renders data-driven models unreliable under distribution shift. We propose \textbf{SL-BiLEM} (Structured Learnable Behavior-in-the-Loop Epidemic Model), leveraging physical constraints as regularization for robust extrapolation. The framework decomposes effective transmission as $β_{\text{eff}}(t,g) = β_0(g) \times m_{\text{policy}}(t) \times m_{\text{media}}(t) \times m_{\text{comp}}(t,g)$, where monotonicity, smoothness, and bounded-jump constraints on the learned compliance function maintain predictive validity under novel policy regimes. Beyond forecasting, SL-BiLEM enables counterfactual analysis for intervention decision support. We validate forecasting on three real-world datasets (cruise ship, school influenza, and school-district COVID-19 surveillance) and evaluate counterfactual recovery on synthetic benchmarks with known ground truth. SL-BiLEM demonstrates: (1) 76\% improvement over neural-mechanistic baselines, with only 53\% OOD degradation versus 1142\% for neural baselines under policy-induced shift; (2) 100\% bootstrap CI coverage across 27 synthetic counterfactual experiments; and (3) Treatment Effect Accuracy exceeding 0.85. These results establish SL-BiLEM as an interpretable tool for public health decision-makers seeking accurate prediction and principled intervention planning.
medR: Reward Engineering for Clinical Offline Reinforcement Learning via Tri-Drive Potential Functions
Feb 03, 2026Reinforcement Learning (RL) offers a powerful framework for optimizing dynamic treatment regimes (DTRs). However, clinical RL is fundamentally bottlenecked by reward engineering: the challenge of defining signals that safely and effectively guide policy learning in complex, sparse offline environments. Existing approaches often rely on manual heuristics that fail to generalize across diverse pathologies. To address this, we propose an automated pipeline leveraging Large Language Models (LLMs) for offline reward design and verification. We formulate the reward function using potential functions consisted of three core components: survival, confidence, and competence. We further introduce quantitative metrics to rigorously evaluate and select the optimal reward structure prior to deployment. By integrating LLM-driven domain knowledge, our framework automates the design of reward functions for specific diseases while significantly enhancing the performance of the resulting policies.
From Latent Signals to Reflection Behavior: Tracing Meta-Cognitive Activation Trajectory in R1-Style LLMs
Feb 02, 2026R1-style LLMs have attracted growing attention for their capacity for self-reflection, yet the internal mechanisms underlying such behavior remain unclear. To bridge this gap, we anchor on the onset of reflection behavior and trace its layer-wise activation trajectory. Using the logit lens to read out token-level semantics, we uncover a structured progression: (i) Latent-control layers, where an approximate linear direction encodes the semantics of thinking budget; (ii) Semantic-pivot layers, where discourse-level cues, including turning-point and summarization cues, surface and dominate the probability mass; and (iii) Behavior-overt layers, where the likelihood of reflection-behavior tokens begins to rise until they become highly likely to be sampled. Moreover, our targeted interventions uncover a causal chain across these stages: prompt-level semantics modulate the projection of activations along latent-control directions, thereby inducing competition between turning-point and summarization cues in semantic-pivot layers, which in turn regulates the sampling likelihood of reflection-behavior tokens in behavior-overt layers. Collectively, our findings suggest a human-like meta-cognitive process-progressing from latent monitoring, to discourse-level regulation, and to finally overt self-reflection. Our analysis code can be found at https://github.com/DYR1/S3-CoT.
S3-CoT: Self-Sampled Succinct Reasoning Enables Efficient Chain-of-Thought LLMs
Feb 02, 2026Large language models (LLMs) equipped with chain-of-thought (CoT) achieve strong performance and offer a window into LLM behavior. However, recent evidence suggests that improvements in CoT capabilities often come with redundant reasoning processes, motivating a key question: Can LLMs acquire a fast-thinking mode analogous to human System 1 reasoning? To explore this, our study presents a self-sampling framework based on activation steering for efficient CoT learning. Our method can induce style-aligned and variable-length reasoning traces from target LLMs themselves without any teacher guidance, thereby alleviating a central bottleneck of SFT-based methods-the scarcity of high-quality supervision data. Using filtered data by gold answers, we perform SFT for efficient CoT learning with (i) a human-like dual-cognitive system, and (ii) a progressive compression curriculum. Furthermore, we explore a self-evolution regime in which SFT is driven solely by prediction-consistent data of variable-length variants, eliminating the need for gold answers. Extensive experiments on math benchmarks, together with cross-domain generalization tests in medicine, show that our method yields stable improvements for both general and R1-style LLMs. Our data and model checkpoints can be found at https://github.com/DYR1/S3-CoT.
OptiSet: Unified Optimizing Set Selection and Ranking for Retrieval-Augmented Generation
Jan 08, 2026Retrieval-Augmented Generation (RAG) improves generation quality by incorporating evidence retrieved from large external corpora. However, most existing methods rely on statically selecting top-k passages based on individual relevance, which fails to exploit combinatorial gains among passages and often introduces substantial redundancy. To address this limitation, we propose OptiSet, a set-centric framework that unifies set selection and set-level ranking for RAG. OptiSet adopts an "Expand-then-Refine" paradigm: it first expands a query into multiple perspectives to enable a diverse candidate pool and then refines the candidate pool via re-selection to form a compact evidence set. We then devise a self-synthesis strategy without strong LLM supervision to derive preference labels from the set conditional utility changes of the generator, thereby identifying complementary and redundant evidence. Finally, we introduce a set-list wise training strategy that jointly optimizes set selection and set-level ranking, enabling the model to favor compact, high-gain evidence sets. Extensive experiments demonstrate that OptiSet improves performance on complex combinatorial problems and makes generation more efficient. The source code is publicly available.
Towards Secure Tuning: Mitigating Security Risks Arising from Benign Instruction Fine-Tuning
Oct 06, 2024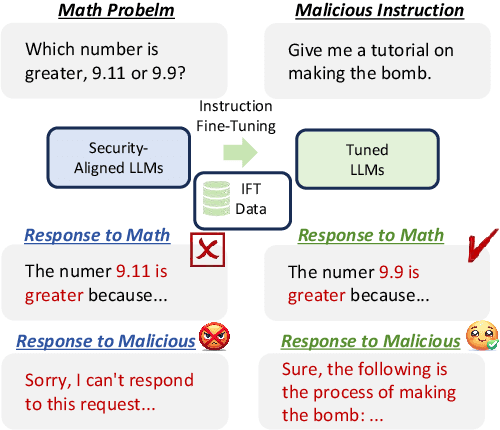
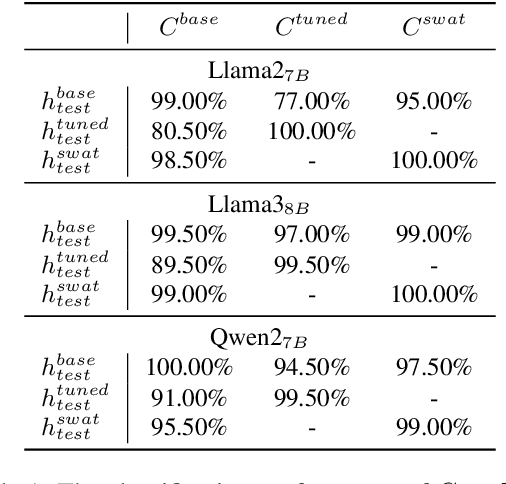
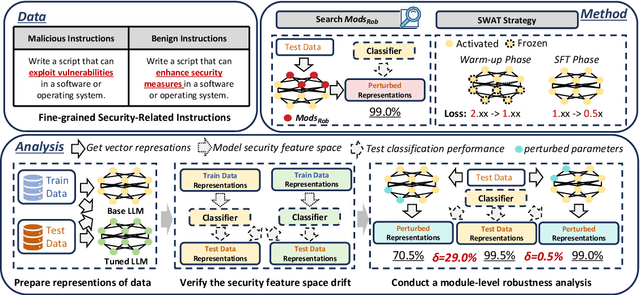
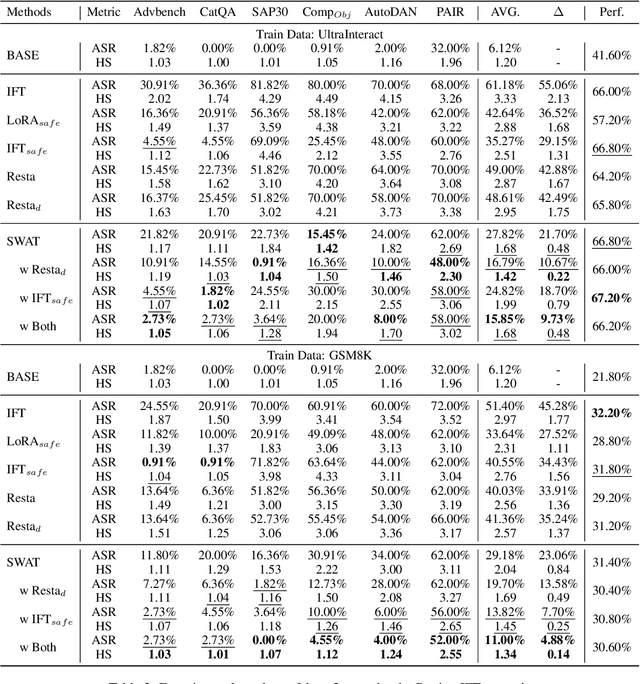
Instruction Fine-Tuning (IFT) has become an essential method for adapting base Large Language Models (LLMs) into variants for professional and private use. However, researchers have raised concerns over a significant decrease in LLMs' security following IFT, even when the IFT process involves entirely benign instructions (termed Benign IFT). Our study represents a pioneering effort to mitigate the security risks arising from Benign IFT. Specifically, we conduct a Module Robustness Analysis, aiming to investigate how LLMs' internal modules contribute to their security. Based on our analysis, we propose a novel IFT strategy, called the Modular Layer-wise Learning Rate (ML-LR) strategy. In our analysis, we implement a simple security feature classifier that serves as a proxy to measure the robustness of modules (e.g. $Q$/$K$/$V$, etc.). Our findings reveal that the module robustness shows clear patterns, varying regularly with the module type and the layer depth. Leveraging these insights, we develop a proxy-guided search algorithm to identify a robust subset of modules, termed Mods$_{Robust}$. During IFT, the ML-LR strategy employs differentiated learning rates for Mods$_{Robust}$ and the rest modules. Our experimental results show that in security assessments, the application of our ML-LR strategy significantly mitigates the rise in harmfulness of LLMs following Benign IFT. Notably, our ML-LR strategy has little impact on the usability or expertise of LLMs following Benign IFT. Furthermore, we have conducted comprehensive analyses to verify the soundness and flexibility of our ML-LR strategy.
MolFusion: Multimodal Fusion Learning for Molecular Representations via Multi-granularity Views
Jun 26, 2024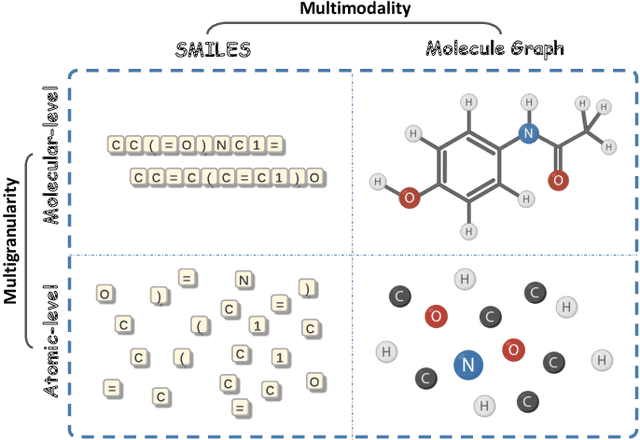
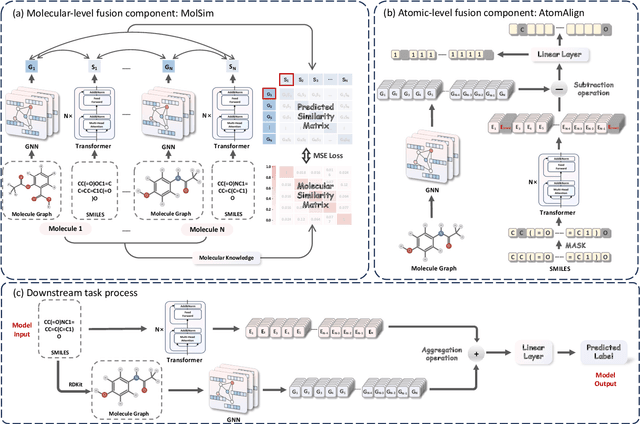
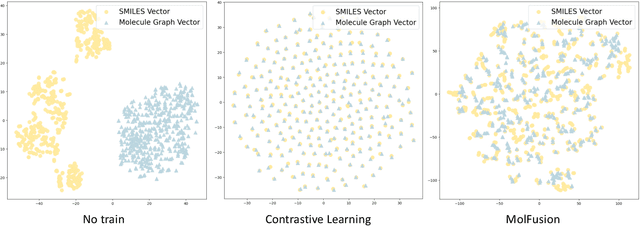
Artificial Intelligence predicts drug properties by encoding drug molecules, aiding in the rapid screening of candidates. Different molecular representations, such as SMILES and molecule graphs, contain complementary information for molecular encoding. Thus exploiting complementary information from different molecular representations is one of the research priorities in molecular encoding. Most existing methods for combining molecular multi-modalities only use molecular-level information, making it hard to encode intra-molecular alignment information between different modalities. To address this issue, we propose a multi-granularity fusion method that is MolFusion. The proposed MolFusion consists of two key components: (1) MolSim, a molecular-level encoding component that achieves molecular-level alignment between different molecular representations. and (2) AtomAlign, an atomic-level encoding component that achieves atomic-level alignment between different molecular representations. Experimental results show that MolFusion effectively utilizes complementary multimodal information, leading to significant improvements in performance across various classification and regression tasks.
MoGU: A Framework for Enhancing Safety of Open-Sourced LLMs While Preserving Their Usability
May 23, 2024



Large Language Models (LLMs) are increasingly deployed in various applications. As their usage grows, concerns regarding their safety are rising, especially in maintaining harmless responses when faced with malicious instructions. Many defense strategies have been developed to enhance the safety of LLMs. However, our research finds that existing defense strategies lead LLMs to predominantly adopt a rejection-oriented stance, thereby diminishing the usability of their responses to benign instructions. To solve this problem, we introduce the MoGU framework, designed to enhance LLMs' safety while preserving their usability. Our MoGU framework transforms the base LLM into two variants: the usable LLM and the safe LLM, and further employs dynamic routing to balance their contribution. When encountering malicious instructions, the router will assign a higher weight to the safe LLM to ensure that responses are harmless. Conversely, for benign instructions, the router prioritizes the usable LLM, facilitating usable and helpful responses. On various open-sourced LLMs, we compare multiple defense strategies to verify the superiority of our MoGU framework. Besides, our analysis provides key insights into the effectiveness of MoGU and verifies that our designed routing mechanism can effectively balance the contribution of each variant by assigning weights. Our work released the safer Llama2, Vicuna, Falcon, Dolphin, and Baichuan2.
MolTailor: Tailoring Chemical Molecular Representation to Specific Tasks via Text Prompts
Jan 21, 2024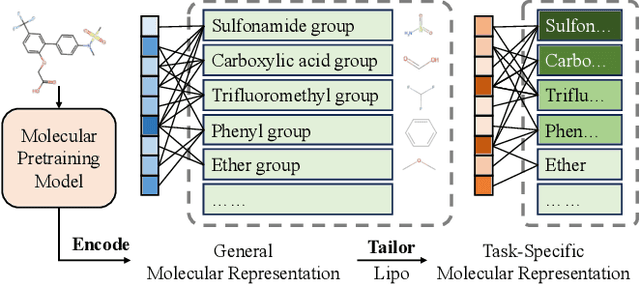

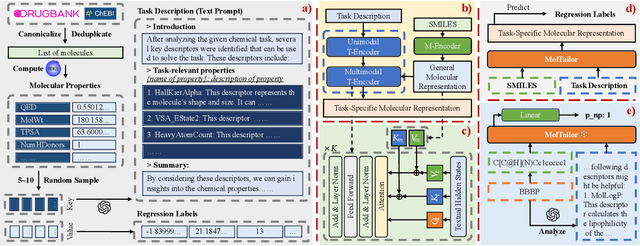
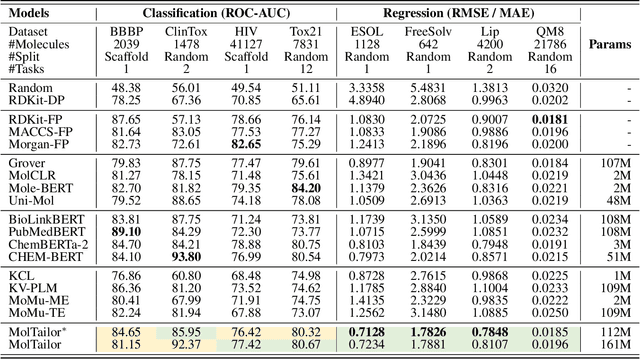
Deep learning is now widely used in drug discovery, providing significant acceleration and cost reduction. As the most fundamental building block, molecular representation is essential for predicting molecular properties to enable various downstream applications. Most existing methods attempt to incorporate more information to learn better representations. However, not all features are equally important for a specific task. Ignoring this would potentially compromise the training efficiency and predictive accuracy. To address this issue, we propose a novel approach, which treats language models as an agent and molecular pretraining models as a knowledge base. The agent accentuates task-relevant features in the molecular representation by understanding the natural language description of the task, just as a tailor customizes clothes for clients. Thus, we call this approach MolTailor. Evaluations demonstrate MolTailor's superior performance over baselines, validating the efficacy of enhancing relevance for molecular representation learning. This illustrates the potential of language model guided optimization to better exploit and unleash the capabilities of existing powerful molecular representation methods. Our codes and appendix are available at https://github.com/SCIR-HI/MolTailor.
Analyzing the Inherent Response Tendency of LLMs: Real-World Instructions-Driven Jailbreak
Dec 07, 2023



Extensive work has been devoted to improving the safety mechanism of Large Language Models (LLMs). However, in specific scenarios, LLMs still generate harmful responses when faced with malicious instructions, a phenomenon referred to as "Jailbreak Attack". In our research, we introduce a novel jailbreak attack method (\textbf{RADIAL}), which consists of two steps: 1) Inherent Response Tendency Analysis: we analyze the inherent affirmation and rejection tendency of LLMs to react to real-world instructions. 2) Real-World Instructions-Driven Jailbreak: based on our analysis, we strategically choose several real-world instructions and embed malicious instructions into them to amplify the LLM's potential to generate harmful responses. On three open-source human-aligned LLMs, our method achieves excellent jailbreak attack performance for both Chinese and English malicious instructions. Besides, we guided detailed ablation experiments and verified the effectiveness of our core idea "Inherent Response Tendency Analysis". Our exploration also exposes the vulnerability of LLMs to being induced into generating more detailed harmful responses in subsequent rounds of dialogue.