 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3-CoT: Self-Sampled Succinct Reasoning Enables Efficient Chain-of-Thought LLMs
Feb 02, 2026Large language models (LLMs) equipped with chain-of-thought (CoT) achieve strong performance and offer a window into LLM behavior. However, recent evidence suggests that improvements in CoT capabilities often come with redundant reasoning processes, motivating a key question: Can LLMs acquire a fast-thinking mode analogous to human System 1 reasoning? To explore this, our study presents a self-sampling framework based on activation steering for efficient CoT learning. Our method can induce style-aligned and variable-length reasoning traces from target LLMs themselves without any teacher guidance, thereby alleviating a central bottleneck of SFT-based methods-the scarcity of high-quality supervision data. Using filtered data by gold answers, we perform SFT for efficient CoT learning with (i) a human-like dual-cognitive system, and (ii) a progressive compression curriculum. Furthermore, we explore a self-evolution regime in which SFT is driven solely by prediction-consistent data of variable-length variants, eliminating the need for gold answers. Extensive experiments on math benchmarks, together with cross-domain generalization tests in medicine, show that our method yields stable improvements for both general and R1-style LLMs. Our data and model checkpoints can be found at https://github.com/DYR1/S3-CoT.
Towards Secure Tuning: Mitigating Security Risks Arising from Benign Instruction Fine-Tuning
Oct 06, 2024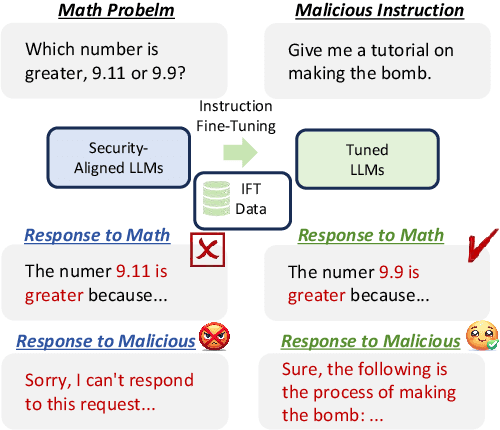
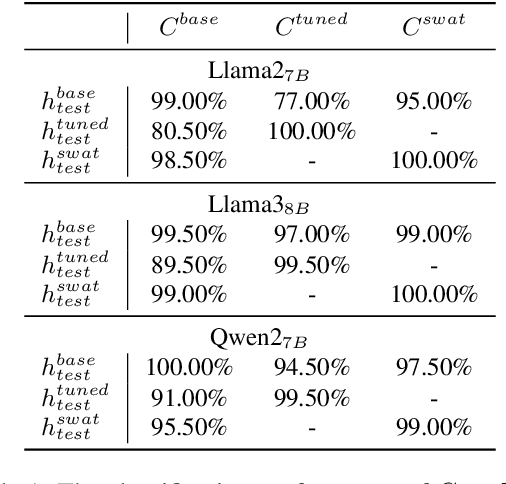
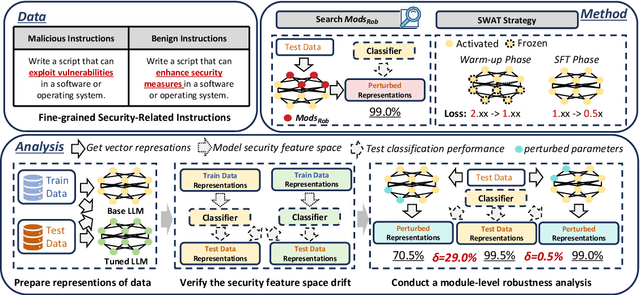
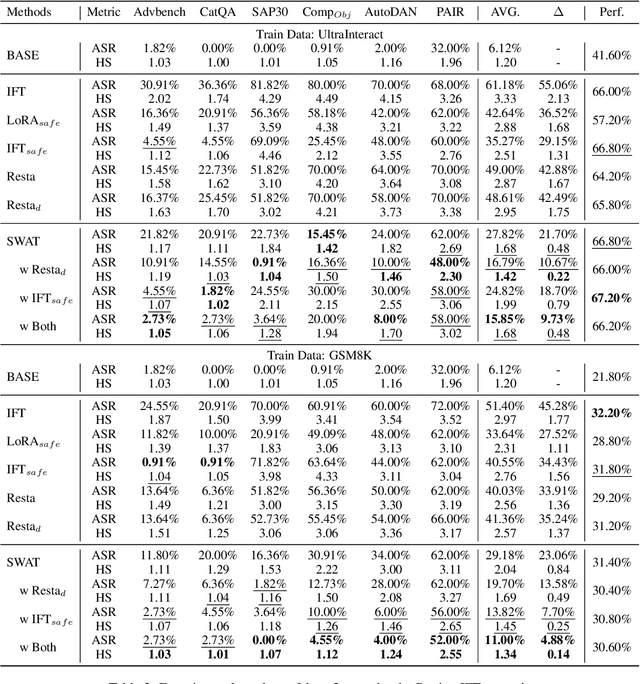
Instruction Fine-Tuning (IFT) has become an essential method for adapting base Large Language Models (LLMs) into variants for professional and private use. However, researchers have raised concerns over a significant decrease in LLMs' security following IFT, even when the IFT process involves entirely benign instructions (termed Benign IFT). Our study represents a pioneering effort to mitigate the security risks arising from Benign IFT. Specifically, we conduct a Module Robustness Analysis, aiming to investigate how LLMs' internal modules contribute to their security. Based on our analysis, we propose a novel IFT strategy, called the Modular Layer-wise Learning Rate (ML-LR) strategy. In our analysis, we implement a simple security feature classifier that serves as a proxy to measure the robustness of modules (e.g. $Q$/$K$/$V$, etc.). Our findings reveal that the module robustness shows clear patterns, varying regularly with the module type and the layer depth. Leveraging these insights, we develop a proxy-guided search algorithm to identify a robust subset of modules, termed Mods$_{Robust}$. During IFT, the ML-LR strategy employs differentiated learning rates for Mods$_{Robust}$ and the rest modules. Our experimental results show that in security assessments, the application of our ML-LR strategy significantly mitigates the rise in harmfulness of LLMs following Benign IFT. Notably, our ML-LR strategy has little impact on the usability or expertise of LLMs following Benign IFT. Furthermore, we have conducted comprehensive analyses to verify the soundness and flexibility of our ML-LR strategy.
MoGU: A Framework for Enhancing Safety of Open-Sourced LLMs While Preserving Their Usability
May 23, 2024



Large Language Models (LLMs) are increasingly deployed in various applications. As their usage grows, concerns regarding their safety are rising, especially in maintaining harmless responses when faced with malicious instructions. Many defense strategies have been developed to enhance the safety of LLMs. However, our research finds that existing defense strategies lead LLMs to predominantly adopt a rejection-oriented stance, thereby diminishing the usability of their responses to benign instructions. To solve this problem, we introduce the MoGU framework, designed to enhance LLMs' safety while preserving their usability. Our MoGU framework transforms the base LLM into two variants: the usable LLM and the safe LLM, and further employs dynamic routing to balance their contribution. When encountering malicious instructions, the router will assign a higher weight to the safe LLM to ensure that responses are harmless. Conversely, for benign instructions, the router prioritizes the usable LLM, facilitating usable and helpful responses. On various open-sourced LLMs, we compare multiple defense strategies to verify the superiority of our MoGU framework. Besides, our analysis provides key insights into the effectiveness of MoGU and verifies that our designed routing mechanism can effectively balance the contribution of each variant by assigning weights. Our work released the safer Llama2, Vicuna, Falcon, Dolphin, and Baichuan2.