 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Artificially Real to Real: Leveraging Pseudo Data from Large Language Models for Low-Resource Molecule Discovery
Sep 11, 2023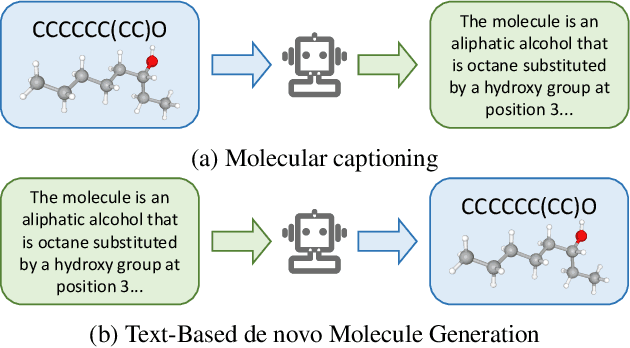
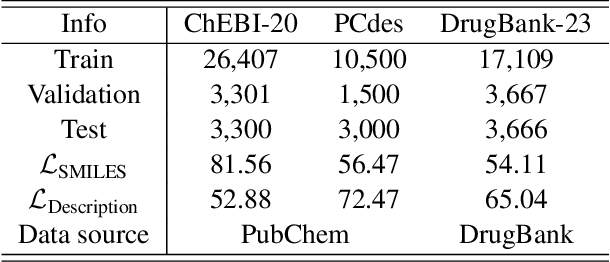
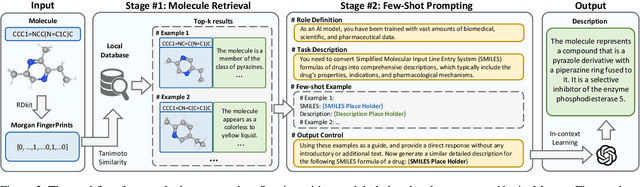
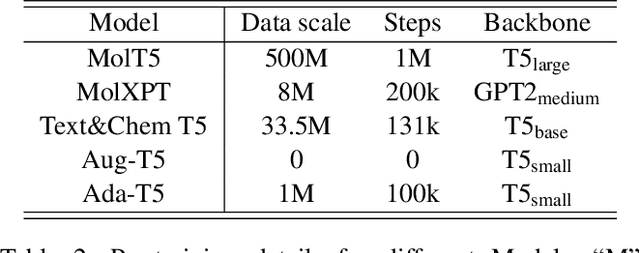
Molecule discovery serves as a cornerstone in numerous scientific domains, fueling the development of new materials and innovative drug designs. Recent developments of in-silico molecule discovery have highlighted the promising results of cross-modal techniques, which bridge molecular structures with their descriptive annotations. However, these cross-modal methods frequently encounter the issue of data scarcity, hampering their performance and application. In this paper, we address the low-resource challenge by utilizing artificially-real data generated by Large Language Models (LLMs). We first introduce a retrieval-based prompting strategy to construct high-quality pseudo data, then explore the optimal method to effectively leverage this pseudo data. Experiments show that using pseudo data for domain adaptation outperforms all existing methods, while also requiring a smaller model scale, reduced data size and lower training cost, highlighting its efficiency. Furthermore, our method shows a sustained improvement as the volume of pseudo data increases, revealing the great potential of pseudo data in advancing low-resource cross-modal molecule discovery.