 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLIP: Adapting Vision-Language models with Hypernetworks
Dec 21, 2024Self-supervised vision-language models trained with contrastive objectives form the basis of current state-of-the-art methods in AI vision tasks. The success of these models is a direct consequence of the huge web-scale datasets used to train them, but they require correspondingly large vision components to properly learn powerful and general representations from such a broad data domain. This poses a challenge for deploying large vision-language models, especially in resource-constrained environments. To address this, we propose an alternate vision-language architecture, called HyperCLIP, that uses a small image encoder along with a hypernetwork that dynamically adapts image encoder weights to each new set of text inputs. All three components of the model (hypernetwork, image encoder, and text encoder) are pre-trained jointly end-to-end, and with a trained HyperCLIP model, we can generate new zero-shot deployment-friendly image classifiers for any task with a single forward pass through the text encoder and hypernetwork. HyperCLIP increases the zero-shot accuracy of SigLIP trained models with small image encoders by up to 3% on ImageNet and 5% on CIFAR-100 with minimal training throughput overhead.
Leveraging Multiple Descriptive Features for Robust Few-shot Image Learning
Jul 10, 2023
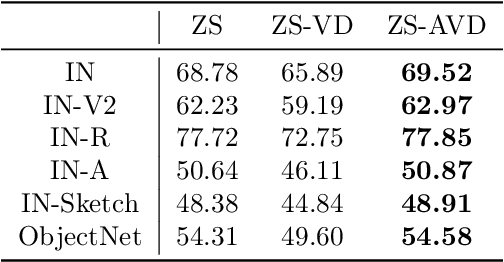


Modern image classification is based upon directly predicting model classes via large discriminative networks, making it difficult to assess the intuitive visual ``features'' that may constitute a classification decision. At the same time, recent works in joint visual language models such as CLIP provide ways to specify natural language descriptions of image classes but typically focus on providing single descriptions for each class. In this work, we demonstrate that an alternative approach, arguably more akin to our understanding of multiple ``visual features'' per class, can also provide compelling performance in the robust few-shot learning setting. In particular, we automatically enumerate multiple visual descriptions of each class -- via a large language model (LLM) -- then use a vision-image model to translate these descriptions to a set of multiple visual features of each image; we finally use sparse logistic regression to select a relevant subset of these features to classify each image. This both provides an ``intuitive'' set of relevant features for each class, and in the few-shot learning setting, outperforms standard approaches such as linear probing. When combined with finetuning, we also show that the method is able to outperform existing state-of-the-art finetuning approaches on both in-distribution and out-of-distribution performance.
Adaptive Sharpness-Aware Pruning for Robust Sparse Networks
Jun 25, 2023Robustness and compactness are two essential components of deep learning models that are deployed in the real world. The seemingly conflicting aims of (i) generalization across domains as in robustness, and (ii) specificity to one domain as in compression, are why the overall design goal of achieving robust compact models, despite being highly important, is still a challenging open problem. We introduce Adaptive Sharpness-Aware Pruning, or AdaSAP, a method that yields robust sparse networks. The central tenet of our approach is to optimize the loss landscape so that the model is primed for pruning via adaptive weight perturbation, and is also consistently regularized toward flatter regions for improved robustness. This unifies both goals through the lens of network sharpness. AdaSAP achieves strong performance in a comprehensive set of experiments. For classification on ImageNet and object detection on Pascal VOC datasets, AdaSAP improves the robust accuracy of pruned models by +6% on ImageNet C, +4% on ImageNet V2, and +4% on corrupted VOC datasets, over a wide range of compression ratios, saliency criteria, and network architectures, outperforming recent pruning art by large margins.
A Simple and Effective Pruning Approach for Large Language Models
Jun 20, 2023



As their size increases, Large Languages Models (LLMs) are natural candidates for network pruning methods: approaches that drop a subset of network weights while striving to preserve performance. Existing methods, however, require either retraining, which is rarely affordable for billion-scale LLMs, or solving a weight reconstruction problem reliant on second-order information, which may also be computationally expensive. In this paper, we introduce a novel, straightforward yet effective pruning method, termed Wanda (Pruning by Weights and activations), designed to induce sparsity in pretrained LLMs. Motivated by the recent observation of emergent large magnitude features in LLMs, our approach prune weights with the smallest magnitudes multiplied by the corresponding input activations, on a per-output basis. Notably, Wanda requires no retraining or weight update, and the pruned LLM can be used as is. We conduct a thorough evaluation of our method on LLaMA across various language benchmarks. Wanda significantly outperforms the established baseline of magnitude pruning and competes favorably against recent methods involving intensive weight update. Code is available at https://github.com/locuslab/wanda.