 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization in-the-Wild: Disentangling Classification from Domain-Aware Representations
Aug 29, 2025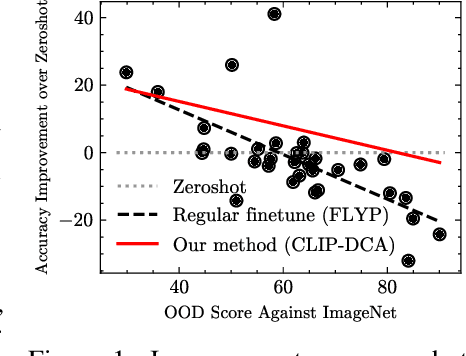
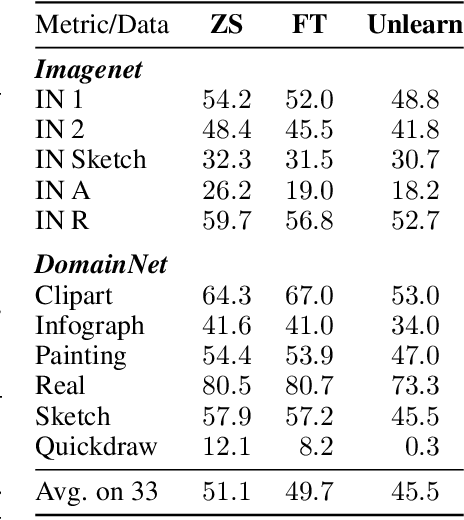
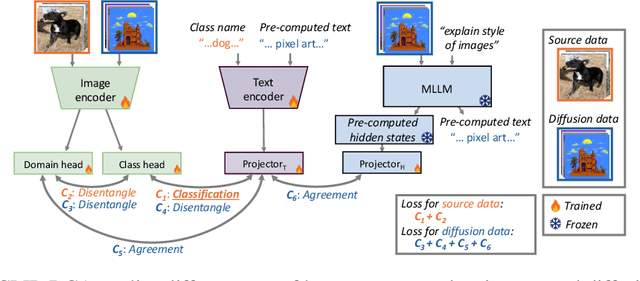
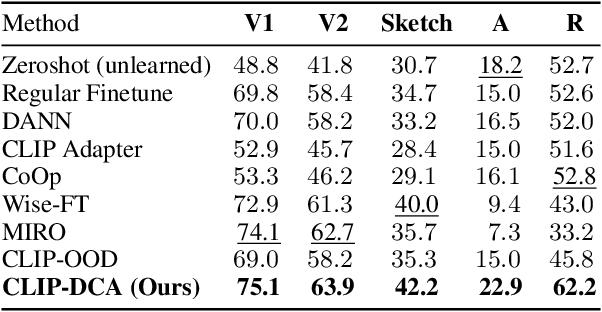
Evaluating domain generalization (DG) for foundational models like CLIP is challenging, as web-scale pretraining data potentially covers many existing benchmarks. Consequently, current DG evaluation may neither be sufficiently challenging nor adequately test genuinely unseen data scenarios. To better assess the performance of CLIP on DG in-the-wild, a scenario where CLIP encounters challenging unseen data, we consider two approaches: (1) evaluating on 33 diverse datasets with quantified out-of-distribution (OOD) scores after fine-tuning CLIP on ImageNet, and (2) using unlearning to make CLIP `forget' some domains as an approximation. We observe that CLIP's performance deteriorates significantly on more OOD datasets. To address this, we present CLIP-DCA (Disentangling Classification from enhanced domain Aware representations). Our approach is motivated by the observation that while standard domain invariance losses aim to make representations domain-invariant, this can be harmful to foundation models by forcing the discarding of domain-aware representations beneficial for generalization. We instead hypothesize that enhancing domain awareness is a prerequisite for effective domain-invariant classification in foundation models. CLIP-DCA identifies and enhances domain awareness within CLIP's encoders using a separate domain head and synthetically generated diverse domain data. Simultaneously, it encourages domain-invariant classification through disentanglement from the domain features. CLIP-DCA shows significant improvements within this challenging evaluation compared to existing methods, particularly on datasets that are more OOD.
FixCLR: Negative-Class Contrastive Learning for Semi-Supervised Domain Generalization
Jun 25, 2025Semi-supervised domain generalization (SSDG) aims to solve the problem of generalizing to out-of-distribution data when only a few labels are available. Due to label scarcity, applying domain generalization methods often underperform. Consequently, existing SSDG methods combine semi-supervised learning methods with various regularization terms. However, these methods do not explicitly regularize to learn domains invariant representations across all domains, which is a key goal for domain generalization. To address this, we introduce FixCLR. Inspired by success in self-supervised learning, we change two crucial components to adapt contrastive learning for explicit domain invariance regularization: utilization of class information from pseudo-labels and using only a repelling term. FixCLR can also be added on top of most existing SSDG and semi-supervised methods for complementary performance improvements. Our research includes extensive experiments that have not been previously explored in SSDG studies. These experiments include benchmarking different improvements to semi-supervised methods, evaluating the performance of pretrained versus non-pretrained models, and testing on datasets with many domains. Overall, FixCLR proves to be an effective SSDG method, especially when combined with other semi-supervised methods.
Implet: A Post-hoc Subsequence Explainer for Time Series Models
May 13, 2025Explainability in time series models is crucial for fostering trust, facilitating debugging, and ensuring interpretability in real-world applications. In this work, we introduce Implet, a novel post-hoc explainer that generates accurate and concise subsequence-level explanations for time series models. Our approach identifies critical temporal segments that significantly contribute to the model's predictions, providing enhanced interpretability beyond traditional feature-attribution methods. Based on it, we propose a cohort-based (group-level) explanation framework designed to further improve the conciseness and interpretability of our explanations. We evaluate Implet on several standard time-series classification benchmarks, demonstrating its effectiveness in improving interpretability. The code is available at https://github.com/LbzSteven/implet
Explanation Space: A New Perspective into Time Series Interpretability
Sep 02, 2024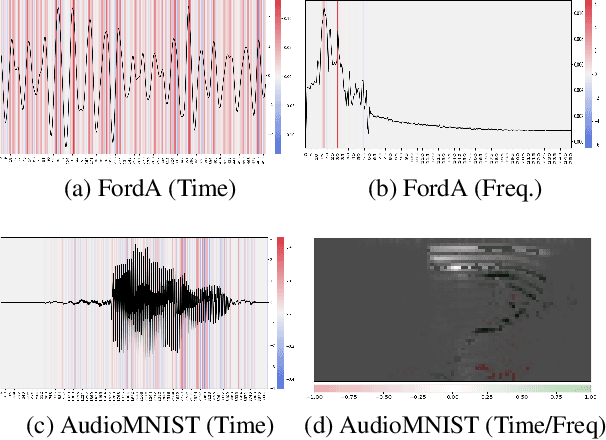



Human understandable explanation of deep learning models is necessary for many critical and sensitive applications. Unlike image or tabular data where the importance of each input feature (for the classifier's decision) can be directly projected into the input, time series distinguishable features (e.g. dominant frequency) are often hard to manifest in time domain for a user to easily understand. Moreover, most explanation methods require a baseline value as an indication of the absence of any feature. However, the notion of lack of feature, which is often defined as black pixels for vision tasks or zero/mean values for tabular data, is not well-defined in time series. Despite the adoption of explainable AI methods (XAI) from tabular and vision domain into time series domain, these differences limit the application of these XAI methods in practice. In this paper, we propose a simple yet effective method that allows a model originally trained on time domain to be interpreted in other explanation spaces using existing methods. We suggest four explanation spaces that each can potentially alleviate these issues in certain types of time series. Our method can be readily adopted in existing platforms without any change to trained models or XAI methods.
Benchmarking Counterfactual Interpretability in Deep Learning Models for Time Series Classification
Aug 22, 2024The popularity of deep learning methods in the time series domain boosts interest in interpretability studies, including counterfactual (CF) methods. CF methods identify minimal changes in instances to alter the model predictions. Despite extensive research, no existing work benchmarks CF methods in the time series domain. Additionally, the results reported in the literature are inconclusive due to the limited number of datasets and inadequate metrics. In this work, we redesign quantitative metrics to accurately capture desirable characteristics in CFs. We specifically redesign the metrics for sparsity and plausibility and introduce a new metric for consistency. Combined with validity, generation time, and proximity, we form a comprehensive metric set. We systematically benchmark 6 different CF methods on 20 univariate datasets and 10 multivariate datasets with 3 different classifiers. Results indicate that the performance of CF methods varies across metrics and among different models. Finally, we provide case studies and a guideline for practical usage.
Dynamic Batch Norm Statistics Update for Natural Robustness
Oct 31, 2023DNNs trained on natural clean samples have been shown to perform poorly on corrupted samples, such as noisy or blurry images. Various data augmentation methods have been recently proposed to improve DNN's robustness against common corruptions. Despite their success, they require computationally expensive training and cannot be applied to off-the-shelf trained models. Recently, it has been shown that updating BatchNorm (BN) statistics of an off-the-shelf model on a single corruption improves its accuracy on that corruption significantly. However, adopting the idea at inference time when the type of corruption is unknown and changing decreases the effectiveness of this method. In this paper, we harness the Fourier domain to detect the corruption type, a challenging task in the image domain. We propose a unified framework consisting of a corruption-detection model and BN statistics update that improves the corruption accuracy of any off-the-shelf trained model. We benchmark our framework on different models and datasets. Our results demonstrate about 8% and 4% accuracy improvement on CIFAR10-C and ImageNet-C, respectively. Furthermore, our framework can further improve the accuracy of state-of-the-art robust models, such as AugMix and DeepAug.
On the Discredibility of Membership Inference Attacks
Dec 06, 2022With the wide-spread application of machine learning models, it has become critical to study the potential data leakage of models trained on sensitive data. Recently, various membership inference (MI) attacks are proposed that determines if a sample was part of the training set or not. Although the first generation of MI attacks has been proven to be ineffective in practice, a few recent studies proposed practical MI attacks that achieve reasonable true positive rate at low false positive rate. The question is whether these attacks can be reliably used in practice. We showcase a practical application of membership inference attacks where it is used by an auditor (investigator) to prove to a judge/jury that an auditee unlawfully used sensitive data during training. Then, we show that the auditee can provide a dataset (with potentially unlimited number of samples) to a judge where MI attacks catastrophically fail. Hence, the auditee challenges the credibility of the auditor and can get the case dismissed. More importantly, we show that the auditee does not need to know anything about the MI attack neither a query access to it. In other words, all currently SOTA MI attacks in literature suffer from the same issue. Through comprehensive experimental evaluation, we show that our algorithms can increase the false positive rate from ten to thousands times larger than what auditor claim to the judge. Lastly, we argue that the implication of our algorithms is beyond discredibility: Current membership inference attacks can identify the memorized subpopulations, but they cannot reliably identify which exact sample in the subpopulation was used during training.
An Efficient Subpopulation-based Membership Inference Attack
Mar 04, 2022


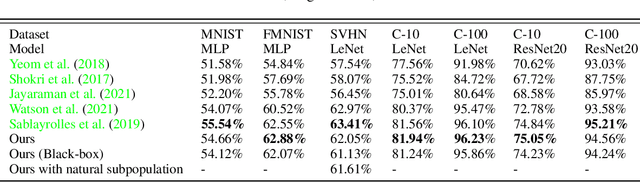
Membership inference attacks allow a malicious entity to predict whether a sample is used during training of a victim model or not. State-of-the-art membership inference attacks have shown to achieve good accuracy which poses a great privacy threat. However, majority of SOTA attacks require training dozens to hundreds of shadow models to accurately infer membership. This huge computation cost raises questions about practicality of these attacks on deep models. In this paper, we introduce a fundamentally different MI attack approach which obviates the need to train hundreds of shadow models. Simply put, we compare the victim model output on the target sample versus the samples from the same subpopulation (i.e., semantically similar samples), instead of comparing it with the output of hundreds of shadow models. The intuition is that the model response should not be significantly different between the target sample and its subpopulation if it was not a training sample. In cases where subpopulation samples are not available to the attacker, we show that training only a single generative model can fulfill the requirement. Hence, we achieve the state-of-the-art membership inference accuracy while significantly reducing the training computation cost.
User-Level Membership Inference Attack against Metric Embedding Learning
Mar 04, 2022

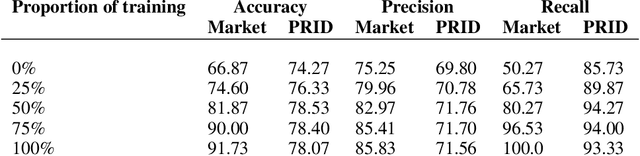
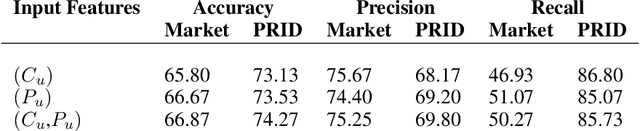
Membership inference (MI) determines if a sample was part of a victim model training set. Recent development of MI attacks focus on record-level membership inference which limits their application in many real-world scenarios. For example, in the person re-identification task, the attacker (or investigator) is interested in determining if a user's images have been used during training or not. However, the exact training images might not be accessible to the attacker. In this paper, we develop a user-level MI attack where the goal is to find if any sample from the target user has been used during training even when no exact training sample is available to the attacker. We focus on metric embedding learning due to its dominance in person re-identification, where user-level MI attack is more sensible. We conduct an extensive evaluation on several datasets and show that our approach achieves high accuracy on user-level MI task.
Accuracy-Privacy Trade-off in Deep Ensembles
May 28, 2021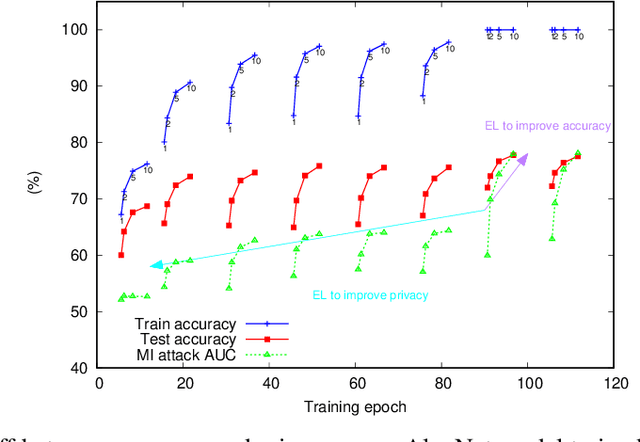

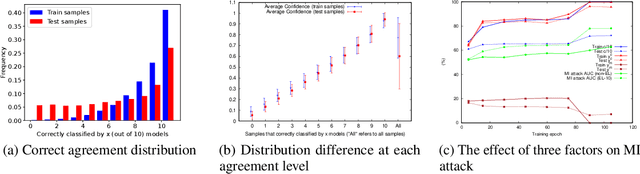

Deep ensemble learning has been shown to improve accuracy by training multiple neural networks and fusing their outputs. Ensemble learning has also been used to defend against membership inference attacks that undermine privacy. In this paper, we empirically demonstrate a trade-off between these two goals, namely accuracy and privacy (in terms of membership inference attacks), in deep ensembles. Using a wide range of datasets and model architectures, we show that the effectiveness of membership inference attacks also increases when ensembling improves accuracy. To better understand this trade-off, we study the impact of various factors such as prediction confidence and agreement between models that constitute the ensemble. Finally, we evaluate defenses against membership inference attacks based on regularization and differential privacy. We show that while these defenses can mitigate the effectiveness of the membership inference attack, they simultaneously degrade ensemble accuracy. The source code is available at https://github.com/shrezaei/MI-on-EL.