 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization in-the-Wild: Disentangling Classification from Domain-Aware Representations
Aug 29, 2025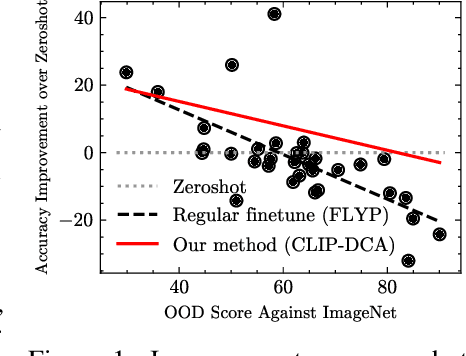
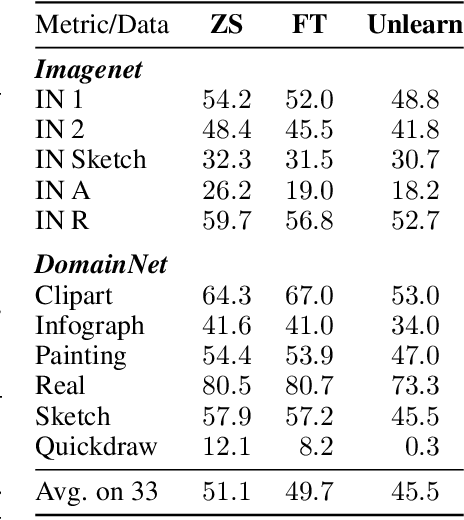
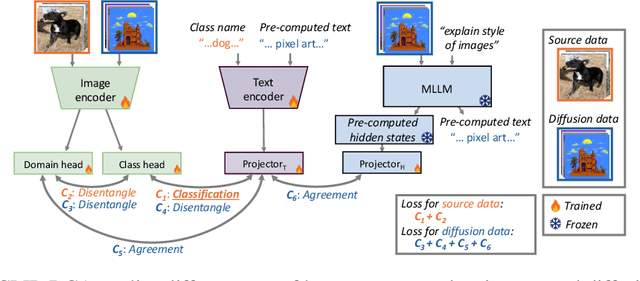
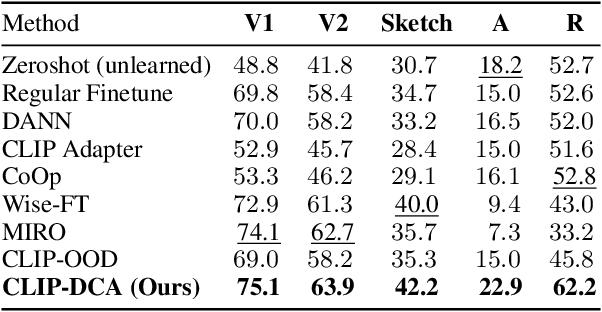
Evaluating domain generalization (DG) for foundational models like CLIP is challenging, as web-scale pretraining data potentially covers many existing benchmarks. Consequently, current DG evaluation may neither be sufficiently challenging nor adequately test genuinely unseen data scenarios. To better assess the performance of CLIP on DG in-the-wild, a scenario where CLIP encounters challenging unseen data, we consider two approaches: (1) evaluating on 33 diverse datasets with quantified out-of-distribution (OOD) scores after fine-tuning CLIP on ImageNet, and (2) using unlearning to make CLIP `forget' some domains as an approximation. We observe that CLIP's performance deteriorates significantly on more OOD datasets. To address this, we present CLIP-DCA (Disentangling Classification from enhanced domain Aware representations). Our approach is motivated by the observation that while standard domain invariance losses aim to make representations domain-invariant, this can be harmful to foundation models by forcing the discarding of domain-aware representations beneficial for generalization. We instead hypothesize that enhancing domain awareness is a prerequisite for effective domain-invariant classification in foundation models. CLIP-DCA identifies and enhances domain awareness within CLIP's encoders using a separate domain head and synthetically generated diverse domain data. Simultaneously, it encourages domain-invariant classification through disentanglement from the domain features. CLIP-DCA shows significant improvements within this challenging evaluation compared to existing methods, particularly on datasets that are more OOD.
FixCLR: Negative-Class Contrastive Learning for Semi-Supervised Domain Generalization
Jun 25, 2025Semi-supervised domain generalization (SSDG) aims to solve the problem of generalizing to out-of-distribution data when only a few labels are available. Due to label scarcity, applying domain generalization methods often underperform. Consequently, existing SSDG methods combine semi-supervised learning methods with various regularization terms. However, these methods do not explicitly regularize to learn domains invariant representations across all domains, which is a key goal for domain generalization. To address this, we introduce FixCLR. Inspired by success in self-supervised learning, we change two crucial components to adapt contrastive learning for explicit domain invariance regularization: utilization of class information from pseudo-labels and using only a repelling term. FixCLR can also be added on top of most existing SSDG and semi-supervised methods for complementary performance improvements. Our research includes extensive experiments that have not been previously explored in SSDG studies. These experiments include benchmarking different improvements to semi-supervised methods, evaluating the performance of pretrained versus non-pretrained models, and testing on datasets with many domains. Overall, FixCLR proves to be an effective SSDG method, especially when combined with other semi-supervised methods.
FedUV: Uniformity and Variance for Heterogeneous Federated Learning
Mar 01, 2024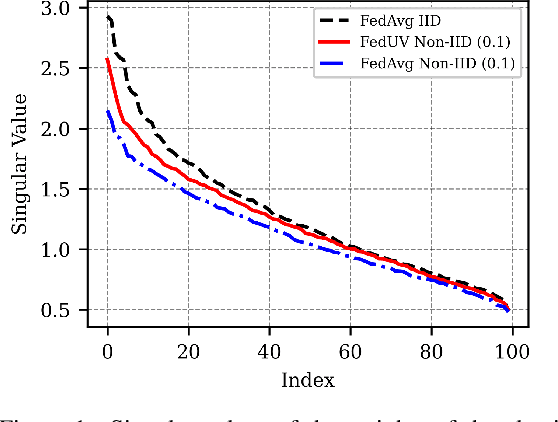

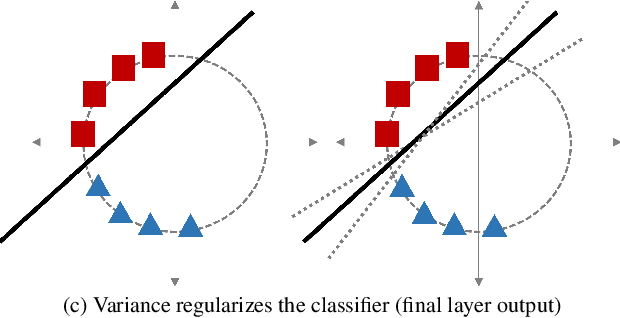

Federated learning is a promising framework to train neural networks with widely distributed data. However, performance degrades heavily with heterogeneously distributed data. Recent work has shown this is due to the final layer of the network being most prone to local bias, some finding success freezing the final layer as an orthogonal classifier. We investigate the training dynamics of the classifier by applying SVD to the weights motivated by the observation that freezing weights results in constant singular values. We find that there are differences when training in IID and non-IID settings. Based on this finding, we introduce two regularization terms for local training to continuously emulate IID settings: (1) variance in the dimension-wise probability distribution of the classifier and (2) hyperspherical uniformity of representations of the encoder. These regularizations promote local models to act as if it were in an IID setting regardless of the local data distribution, thus offsetting proneness to bias while being flexible to the data. On extensive experiments in both label-shift and feature-shift settings, we verify that our method achieves highest performance by a large margin especially in highly non-IID cases in addition to being scalable to larger models and datasets.
Compare Where It Matters: Using Layer-Wise Regularization To Improve Federated Learning on Heterogeneous Data
Dec 01, 2021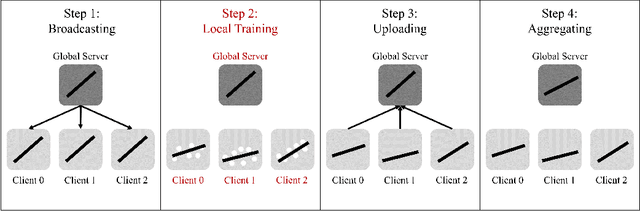

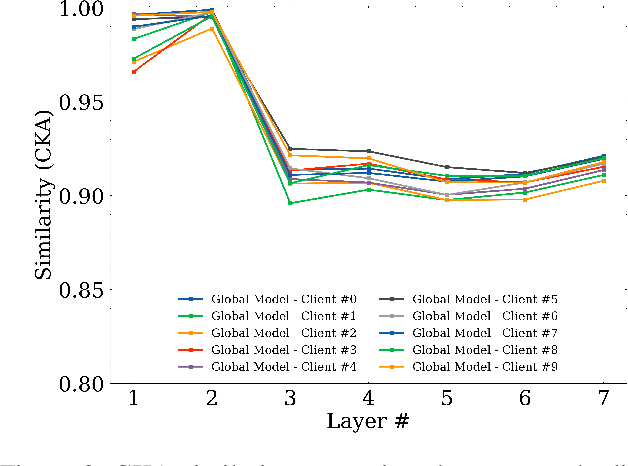

Federated Learning is a widely adopted method to train neural networks over distributed data. One main limitation is the performance degradation that occurs when data is heterogeneously distributed. While many works have attempted to address this problem, these methods under-perform because they are founded on a limited understanding of neural networks. In this work, we verify that only certain important layers in a neural network require regularization for effective training. We additionally verify that Centered Kernel Alignment (CKA) most accurately calculates similarity between layers of neural networks trained on different data. By applying CKA-based regularization to important layers during training, we significantly improve performance in heterogeneous settings. We present FedCKA: a simple framework that out-performs previous state-of-the-art methods on various deep learning tasks while also improving efficiency and scalability.
Personalized Federated Learning with Clustering: Non-IID Heart Rate Variability Data Application
Aug 11, 2021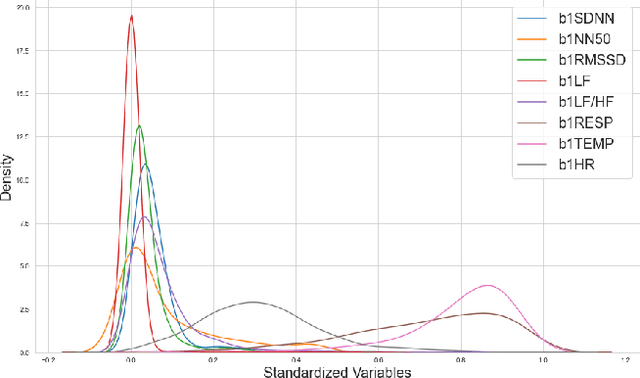
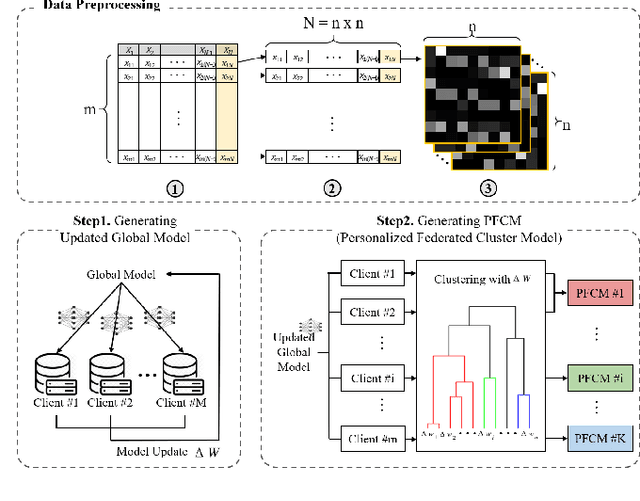
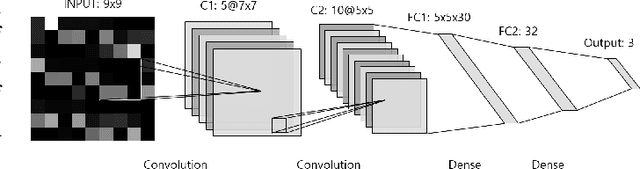
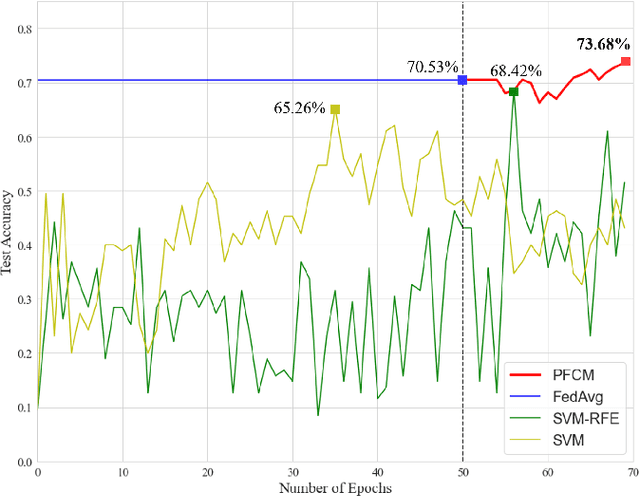
While machine learning techniques are being applied to various fields for their exceptional ability to find complex relations in large datasets, the strengthening of regulations on data ownership and privacy is causing increasing difficulty in its application to medical data. In light of this, Federated Learning has recently been proposed as a solution to train on private data without breach of confidentiality. This conservation of privacy is particularly appealing in the field of healthcare, where patient data is highly confidential. However, many studies have shown that its assumption of Independent and Identically Distributed data is unrealistic for medical data. In this paper, we propose Personalized Federated Cluster Models, a hierarchical clustering-based FL process, to predict Major Depressive Disorder severity from Heart Rate Variability. By allowing clients to receive more personalized model, we address problems caused by non-IID data, showing an accuracy increase in severity prediction. This increase in performance may be sufficient to use Personalized Federated Cluster Models in many existing Federated Learning scenarios.