 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedUV: Uniformity and Variance for Heterogeneous Federated Learning
Mar 01, 2024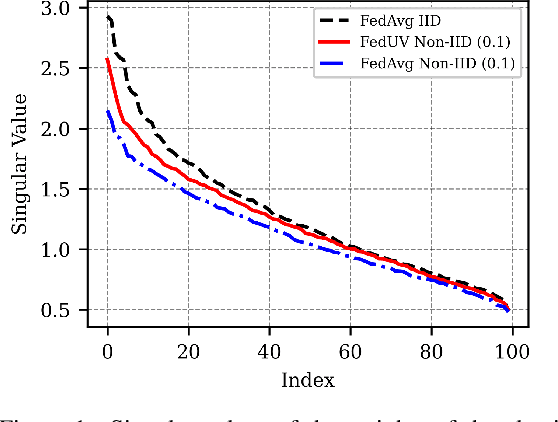

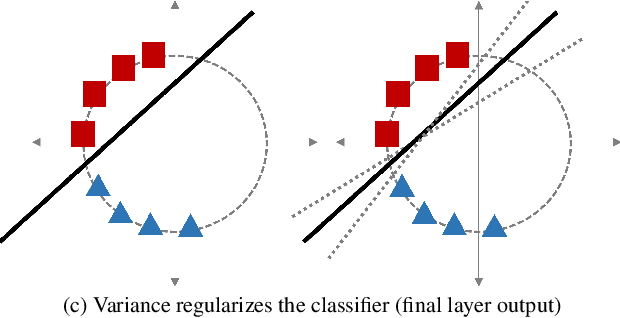

Federated learning is a promising framework to train neural networks with widely distributed data. However, performance degrades heavily with heterogeneously distributed data. Recent work has shown this is due to the final layer of the network being most prone to local bias, some finding success freezing the final layer as an orthogonal classifier. We investigate the training dynamics of the classifier by applying SVD to the weights motivated by the observation that freezing weights results in constant singular values. We find that there are differences when training in IID and non-IID settings. Based on this finding, we introduce two regularization terms for local training to continuously emulate IID settings: (1) variance in the dimension-wise probability distribution of the classifier and (2) hyperspherical uniformity of representations of the encoder. These regularizations promote local models to act as if it were in an IID setting regardless of the local data distribution, thus offsetting proneness to bias while being flexible to the data. On extensive experiments in both label-shift and feature-shift settings, we verify that our method achieves highest performance by a large margin especially in highly non-IID cases in addition to being scalable to larger models and datasets.
Security and Privacy Issues and Solutions in Federated Learning for Digital Healthcare
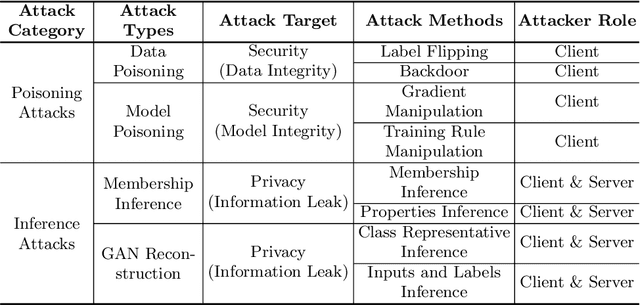
Jan 16, 2024The advent of Federated Learning has enabled the creation of a high-performing model as if it had been trained on a considerable amount of data. A multitude of participants and a server cooperatively train a model without the need for data disclosure or collection. The healthcare industry, where security and privacy are paramount, can substantially benefit from this new learning paradigm, as data collection is no longer feasible due to stringent data policies. Nonetheless, unaddressed challenges and insufficient attack mitigation are hampering its adoption. Attack surfaces differ from traditional centralized learning in that the server and clients communicate between each round of training. In this paper, we thus present vulnerabilities, attacks, and defenses based on the widened attack surfaces, as well as suggest promising new research directions toward a more robust FL.
FedCC: Robust Federated Learning against Model Poisoning Attacks
Dec 05, 2022



Federated Learning has emerged to cope with raising concerns about privacy breaches in using Machine or Deep Learning models. This new paradigm allows the leverage of deep learning models in a distributed manner, enhancing privacy preservation. However, the server's blindness to local datasets introduces its vulnerability to model poisoning attacks and data heterogeneity, tampering with the global model performance. Numerous works have proposed robust aggregation algorithms and defensive mechanisms, but the approaches are orthogonal to individual attacks or issues. FedCC, the proposed method, provides robust aggregation by comparing the Centered Kernel Alignment of Penultimate Layers Representations. The experiment results on FedCC demonstrate that it mitigates untargeted and targeted model poisoning or backdoor attacks while also being effective in non-Independently and Identically Distributed data environments. By applying FedCC against untargeted attacks, global model accuracy is recovered the most. Against targeted backdoor attacks, FedCC nullified attack confidence while preserving the test accuracy. Most of the experiment results outstand the baseline methods.
Compare Where It Matters: Using Layer-Wise Regularization To Improve Federated Learning on Heterogeneous Data
Dec 01, 2021

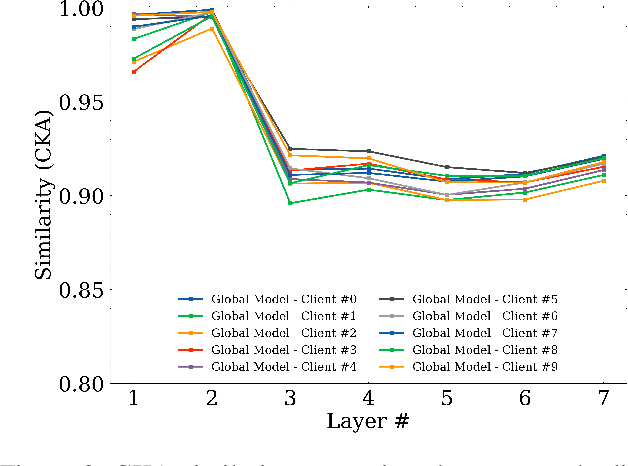

Federated Learning is a widely adopted method to train neural networks over distributed data. One main limitation is the performance degradation that occurs when data is heterogeneously distributed. While many works have attempted to address this problem, these methods under-perform because they are founded on a limited understanding of neural networks. In this work, we verify that only certain important layers in a neural network require regularization for effective training. We additionally verify that Centered Kernel Alignment (CKA) most accurately calculates similarity between layers of neural networks trained on different data. By applying CKA-based regularization to important layers during training, we significantly improve performance in heterogeneous settings. We present FedCKA: a simple framework that out-performs previous state-of-the-art methods on various deep learning tasks while also improving efficiency and scalability.
Federated Learning: Issues in Medical Application
Sep 01, 2021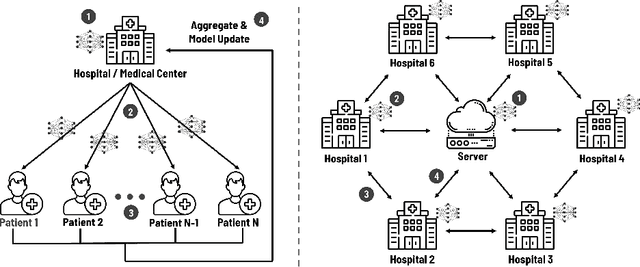
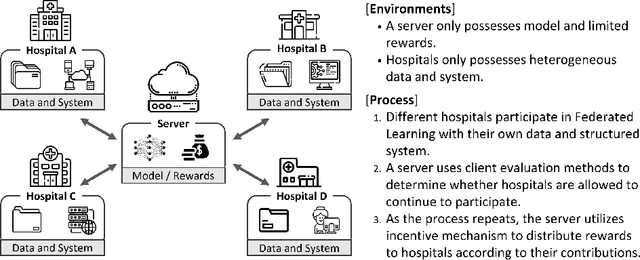
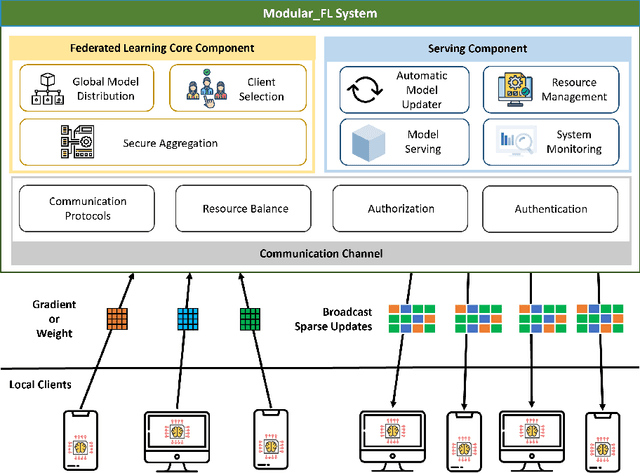
Since the federated learning, which makes AI learning possible without moving local data around, was introduced by google in 2017 it has been actively studied particularly in the field of medicine. In fact, the idea of machine learning in AI without collecting data from local clients is very attractive because data remain in local sites. However, federated learning techniques still have various open issues due to its own characteristics such as non identical distribution, client participation management, and vulnerable environments. In this presentation, the current issues to make federated learning flawlessly useful in the real world will be briefly overviewed. They are related to data/system heterogeneity, client management, traceability, and security. Also, we introduce the modularized federated learning framework, we currently develop, to experiment various techniques and protocols to find solutions for aforementioned issues. The framework will be open to public after development completes.
Personalized Federated Learning with Clustering: Non-IID Heart Rate Variability Data Application
Aug 11, 2021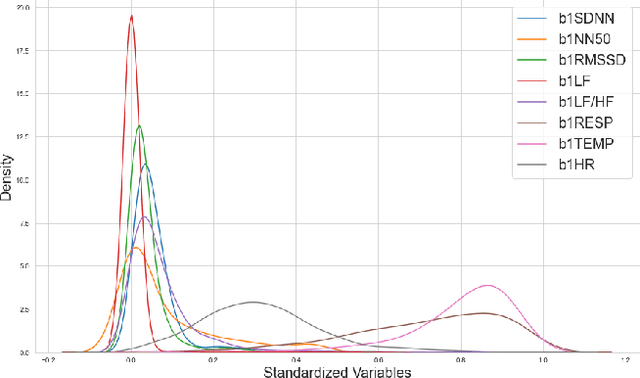
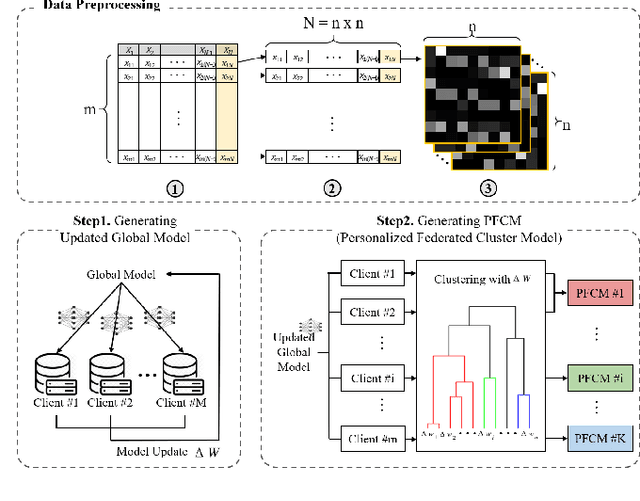
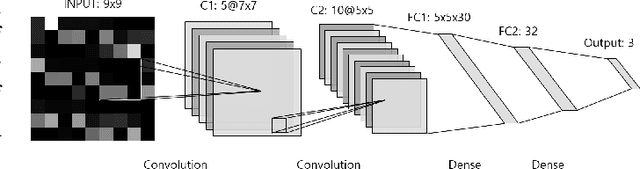
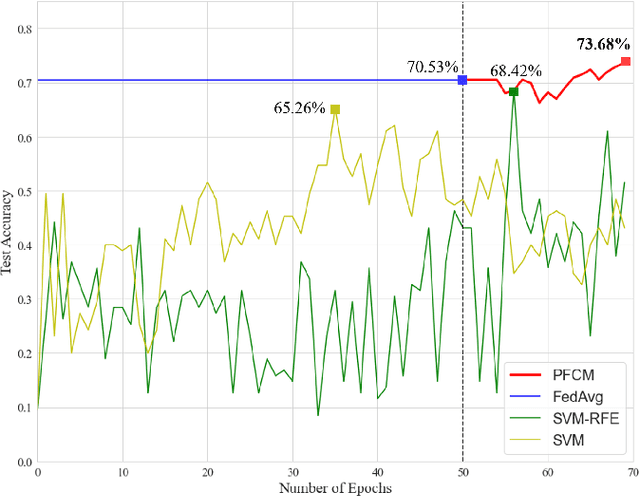
While machine learning techniques are being applied to various fields for their exceptional ability to find complex relations in large datasets, the strengthening of regulations on data ownership and privacy is causing increasing difficulty in its application to medical data. In light of this, Federated Learning has recently been proposed as a solution to train on private data without breach of confidentiality. This conservation of privacy is particularly appealing in the field of healthcare, where patient data is highly confidential. However, many studies have shown that its assumption of Independent and Identically Distributed data is unrealistic for medical data. In this paper, we propose Personalized Federated Cluster Models, a hierarchical clustering-based FL process, to predict Major Depressive Disorder severity from Heart Rate Variability. By allowing clients to receive more personalized model, we address problems caused by non-IID data, showing an accuracy increase in severity prediction. This increase in performance may be sufficient to use Personalized Federated Cluster Models in many existing Federated Learning scenarios.