 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersuasion Propagation in LLM Agents
Jan 31, 2026Modern AI agents increasingly combine conversational interaction with autonomous task execution, such as coding and web research, raising a natural question: what happens when an agent engaged in long-horizon tasks is subjected to user persuasion? We study how belief-level intervention can influence downstream task behavior, a phenomenon we name \emph{persuasion propagation}. We introduce a behavior-centered evaluation framework that distinguishes between persuasion applied during or prior to task execution. Across web research and coding tasks, we find that on-the-fly persuasion induces weak and inconsistent behavioral effects. In contrast, when the belief state is explicitly specified at task time, belief-prefilled agents conduct on average 26.9\% fewer searches and visit 16.9\% fewer unique sources than neutral-prefilled agents. These results suggest that persuasion, even in prior interaction, can affect the agent's behavior, motivating behavior-level evaluation in agentic systems.
Bias Similarity Across Large Language Models
Oct 15, 2024Bias in machine learning models has been a chronic problem, especially as these models influence decision-making in human society. In generative AI, such as Large Language Models, the impact of bias is even more profound compared to the classification models. LLMs produce realistic and human-like content that users may unconsciously trust, which could perpetuate harmful stereotypes to the uncontrolled public. It becomes particularly concerning when utilized in journalism or education. While prior studies have explored and quantified bias in individual AI models, no work has yet compared bias similarity across different LLMs. To fill this gap, we take a comprehensive look at ten open- and closed-source LLMs from four model families, assessing the extent of biases through output distribution. Using two datasets-one containing 4k questions and another with one million questions for each of the four bias dimensions -- we measure functional similarity to understand how biases manifest across models. Our findings reveal that 1) fine-tuning does not significantly alter output distributions, which would limit its ability to mitigate bias, 2) LLMs within the same family tree do not produce similar output distributions, implying that addressing bias in one model could have limited implications for others in the same family, and 3) there is a possible risk of training data information leakage, raising concerns about privacy and data security. Our analysis provides insight into LLM behavior and highlights potential risks in real-world deployment.
SoK: Challenges and Opportunities in Federated Unlearning
Mar 04, 2024Federated learning (FL), introduced in 2017, facilitates collaborative learning between non-trusting parties with no need for the parties to explicitly share their data among themselves. This allows training models on user data while respecting privacy regulations such as GDPR and CPRA. However, emerging privacy requirements may mandate model owners to be able to \emph{forget} some learned data, e.g., when requested by data owners or law enforcement. This has given birth to an active field of research called \emph{machine unlearning}. In the context of FL, many techniques developed for unlearning in centralized settings are not trivially applicable! This is due to the unique differences between centralized and distributed learning, in particular, interactivity, stochasticity, heterogeneity, and limited accessibility in FL. In response, a recent line of work has focused on developing unlearning mechanisms tailored to FL. This SoK paper aims to take a deep look at the \emph{federated unlearning} literature, with the goal of identifying research trends and challenges in this emerging field. By carefully categorizing papers published on FL unlearning (since 2020), we aim to pinpoint the unique complexities of federated unlearning, highlighting limitations on directly applying centralized unlearning methods. We compare existing federated unlearning methods regarding influence removal and performance recovery, compare their threat models and assumptions, and discuss their implications and limitations. For instance, we analyze the experimental setup of FL unlearning studies from various perspectives, including data heterogeneity and its simulation, the datasets used for demonstration, and evaluation metrics. Our work aims to offer insights and suggestions for future research on federated unlearning.
Security and Privacy Issues and Solutions in Federated Learning for Digital Healthcare
Jan 16, 2024The advent of Federated Learning has enabled the creation of a high-performing model as if it had been trained on a considerable amount of data. A multitude of participants and a server cooperatively train a model without the need for data disclosure or collection. The healthcare industry, where security and privacy are paramount, can substantially benefit from this new learning paradigm, as data collection is no longer feasible due to stringent data policies. Nonetheless, unaddressed challenges and insufficient attack mitigation are hampering its adoption. Attack surfaces differ from traditional centralized learning in that the server and clients communicate between each round of training. In this paper, we thus present vulnerabilities, attacks, and defenses based on the widened attack surfaces, as well as suggest promising new research directions toward a more robust FL.
FedCC: Robust Federated Learning against Model Poisoning Attacks
Dec 05, 2022



Federated Learning has emerged to cope with raising concerns about privacy breaches in using Machine or Deep Learning models. This new paradigm allows the leverage of deep learning models in a distributed manner, enhancing privacy preservation. However, the server's blindness to local datasets introduces its vulnerability to model poisoning attacks and data heterogeneity, tampering with the global model performance. Numerous works have proposed robust aggregation algorithms and defensive mechanisms, but the approaches are orthogonal to individual attacks or issues. FedCC, the proposed method, provides robust aggregation by comparing the Centered Kernel Alignment of Penultimate Layers Representations. The experiment results on FedCC demonstrate that it mitigates untargeted and targeted model poisoning or backdoor attacks while also being effective in non-Independently and Identically Distributed data environments. By applying FedCC against untargeted attacks, global model accuracy is recovered the most. Against targeted backdoor attacks, FedCC nullified attack confidence while preserving the test accuracy. Most of the experiment results outstand the baseline methods.
Federated Learning: Issues in Medical Application
Sep 01, 2021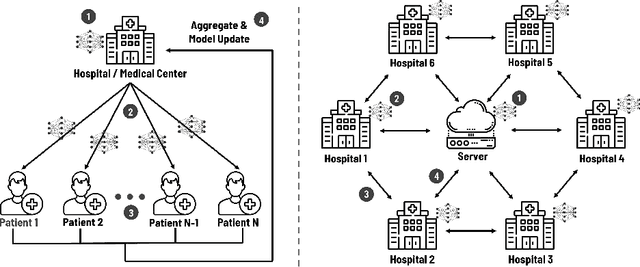
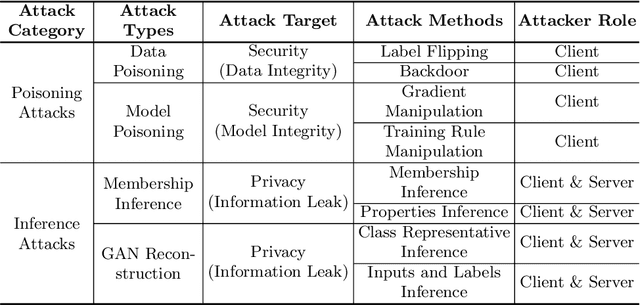
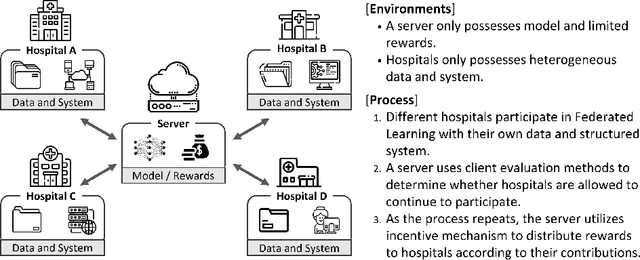
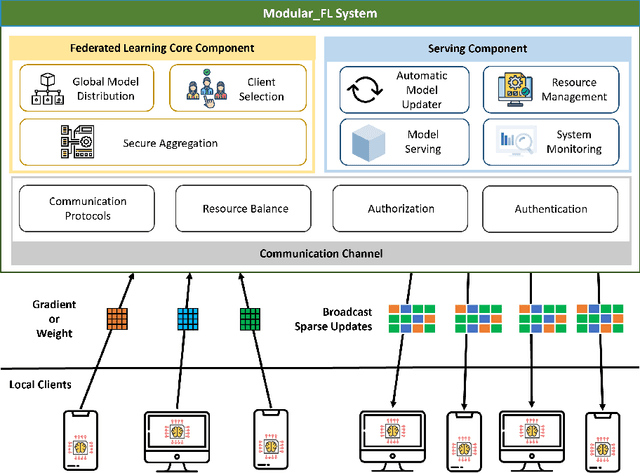
Since the federated learning, which makes AI learning possible without moving local data around, was introduced by google in 2017 it has been actively studied particularly in the field of medicine. In fact, the idea of machine learning in AI without collecting data from local clients is very attractive because data remain in local sites. However, federated learning techniques still have various open issues due to its own characteristics such as non identical distribution, client participation management, and vulnerable environments. In this presentation, the current issues to make federated learning flawlessly useful in the real world will be briefly overviewed. They are related to data/system heterogeneity, client management, traceability, and security. Also, we introduce the modularized federated learning framework, we currently develop, to experiment various techniques and protocols to find solutions for aforementioned issues. The framework will be open to public after development completes.
ABC-FL: Anomalous and Benign client Classification in Federated Learning
Aug 11, 2021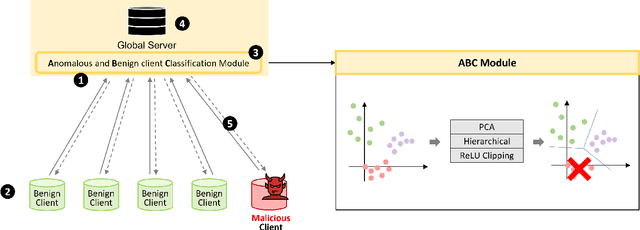
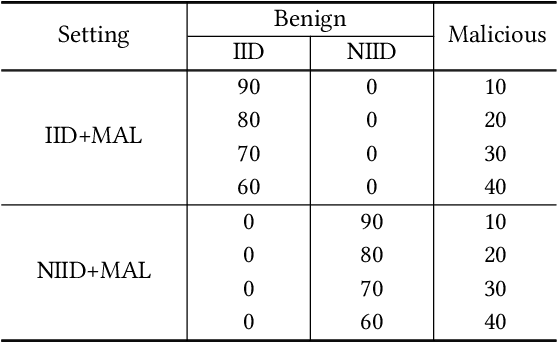

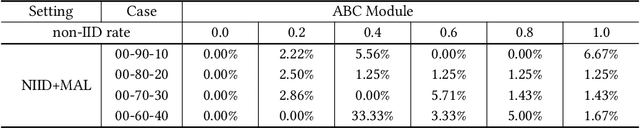
Federated Learning is a distributed machine learning framework designed for data privacy preservation i.e., local data remain private throughout the entire training and testing procedure. Federated Learning is gaining popularity because it allows one to use machine learning techniques while preserving privacy. However, it inherits the vulnerabilities and susceptibilities raised in deep learning techniques. For instance, Federated Learning is particularly vulnerable to data poisoning attacks that may deteriorate its performance and integrity due to its distributed nature and inaccessibility to the raw data. In addition, it is extremely difficult to correctly identify malicious clients due to the non-Independently and/or Identically Distributed (non-IID) data. The real-world data can be complex and diverse, making them hardly distinguishable from the malicious data without direct access to the raw data. Prior research has focused on detecting malicious clients while treating only the clients having IID data as benign. In this study, we propose a method that detects and classifies anomalous clients from benign clients when benign ones have non-IID data. Our proposed method leverages feature dimension reduction, dynamic clustering, and cosine similarity-based clipping. The experimental results validates that our proposed method not only classifies the malicious clients but also alleviates their negative influences from the entire procedure. Our findings may be used in future studies to effectively eliminate anomalous clients when building a model with diverse data.
Personalized Federated Learning with Clustering: Non-IID Heart Rate Variability Data Application
Aug 11, 2021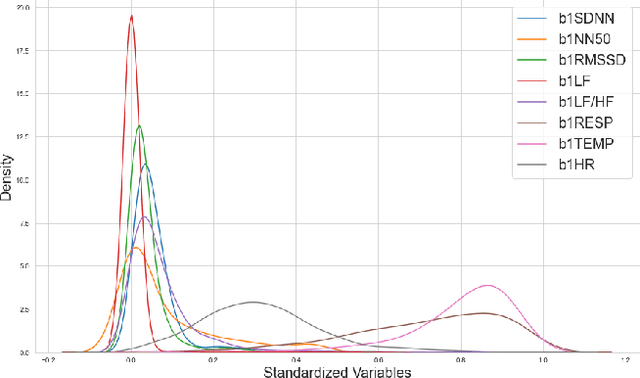
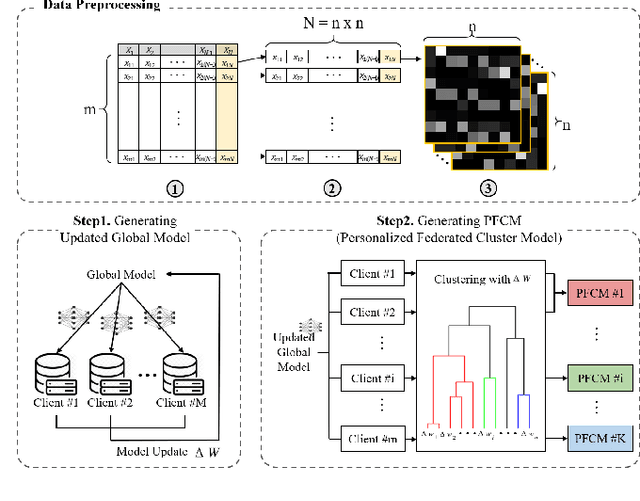
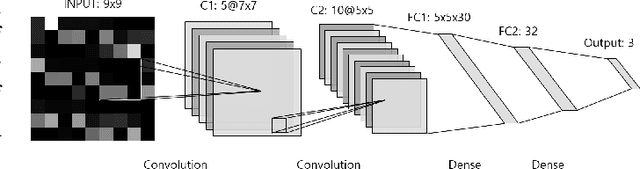
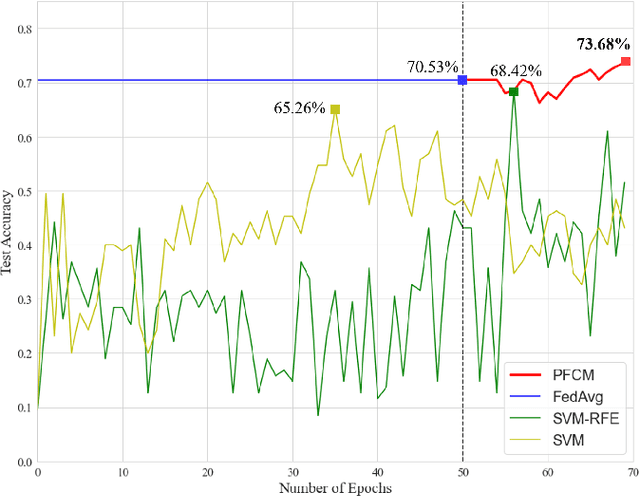
While machine learning techniques are being applied to various fields for their exceptional ability to find complex relations in large datasets, the strengthening of regulations on data ownership and privacy is causing increasing difficulty in its application to medical data. In light of this, Federated Learning has recently been proposed as a solution to train on private data without breach of confidentiality. This conservation of privacy is particularly appealing in the field of healthcare, where patient data is highly confidential. However, many studies have shown that its assumption of Independent and Identically Distributed data is unrealistic for medical data. In this paper, we propose Personalized Federated Cluster Models, a hierarchical clustering-based FL process, to predict Major Depressive Disorder severity from Heart Rate Variability. By allowing clients to receive more personalized model, we address problems caused by non-IID data, showing an accuracy increase in severity prediction. This increase in performance may be sufficient to use Personalized Federated Cluster Models in many existing Federated Learning scenarios.