 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Subpopulation-based Membership Inference Attack
Paper and Code
Mar 04, 2022


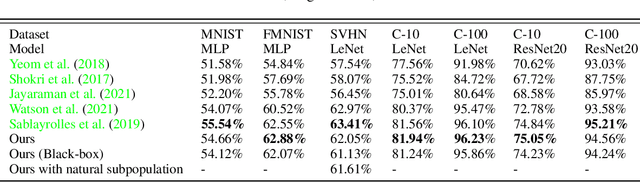
Membership inference attacks allow a malicious entity to predict whether a sample is used during training of a victim model or not. State-of-the-art membership inference attacks have shown to achieve good accuracy which poses a great privacy threat. However, majority of SOTA attacks require training dozens to hundreds of shadow models to accurately infer membership. This huge computation cost raises questions about practicality of these attacks on deep models. In this paper, we introduce a fundamentally different MI attack approach which obviates the need to train hundreds of shadow models. Simply put, we compare the victim model output on the target sample versus the samples from the same subpopulation (i.e., semantically similar samples), instead of comparing it with the output of hundreds of shadow models. The intuition is that the model response should not be significantly different between the target sample and its subpopulation if it was not a training sample. In cases where subpopulation samples are not available to the attacker, we show that training only a single generative model can fulfill the requirement. Hence, we achieve the state-of-the-art membership inference accuracy while significantly reducing the training computation cost.