 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree crop mapping of South America reveals links to deforestation and conservation
Feb 19, 2026Monitoring tree crop expansion is vital for zero-deforestation policies like the European Union's Regulation on Deforestation-free Products (EUDR). However, these efforts are hindered by a lack of highresolution data distinguishing diverse agricultural systems from forests. Here, we present the first 10m-resolution tree crop map for South America, generated using a multi-modal, spatio-temporal deep learning model trained on Sentinel-1 and Sentinel-2 satellite imagery time series. The map identifies approximately 11 million hectares of tree crops, 23% of which is linked to 2000-2020 forest cover loss. Critically, our analysis reveals that existing regulatory maps supporting the EUDR often classify established agriculture, particularly smallholder agroforestry, as "forest". This discrepancy risks false deforestation alerts and unfair penalties for small-scale farmers. Our work mitigates this risk by providing a high-resolution baseline, supporting conservation policies that are effective, inclusive, and equitable.
Multi-Label Learning from Single Positive Labels
Jun 17, 2021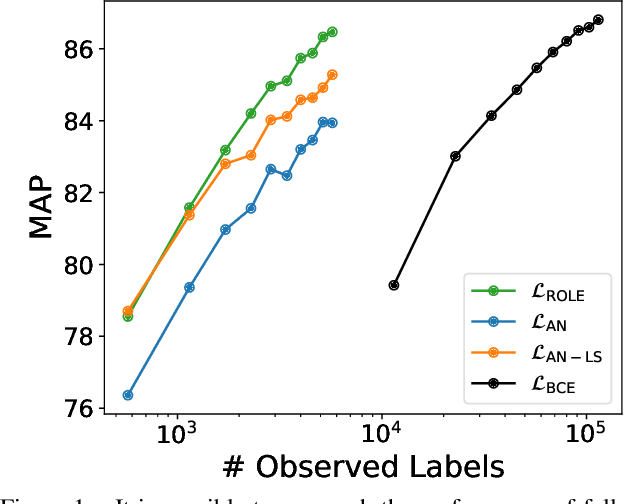
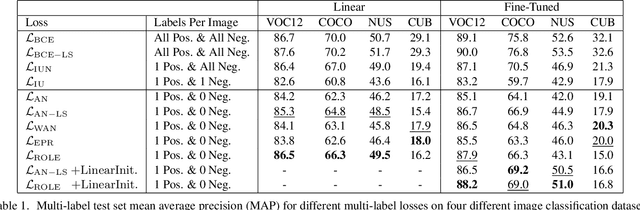
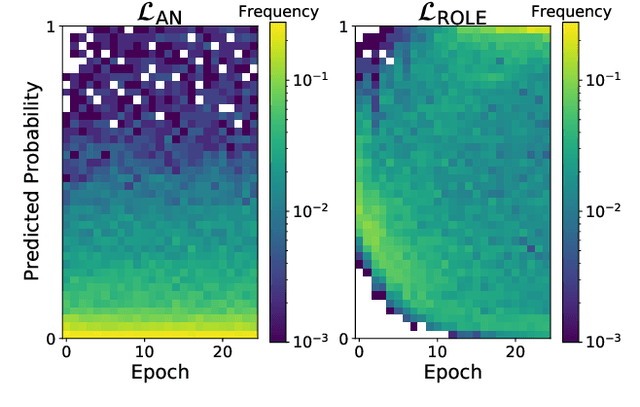
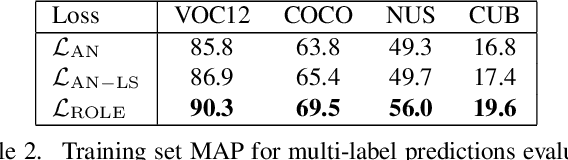
Predicting all applicable labels for a given image is known as multi-label classification. Compared to the standard multi-class case (where each image has only one label), it is considerably more challenging to annotate training data for multi-label classification. When the number of potential labels is large, human annotators find it difficult to mention all applicable labels for each training image. Furthermore, in some settings detection is intrinsically difficult e.g. finding small object instances in high resolution images. As a result, multi-label training data is often plagued by false negatives. We consider the hardest version of this problem, where annotators provide only one relevant label for each image. As a result, training sets will have only one positive label per image and no confirmed negatives. We explore this special case of learning from missing labels across four different multi-label image classification datasets for both linear classifiers and end-to-end fine-tuned deep networks. We extend existing multi-label losses to this setting and propose novel variants that constrain the number of expected positive labels during training. Surprisingly, we show that in some cases it is possible to approach the performance of fully labeled classifiers despite training with significantly fewer confirmed labels.
Sequence Information Channel Concatenation for Improving Camera Trap Image Burst Classification
Apr 30, 2020
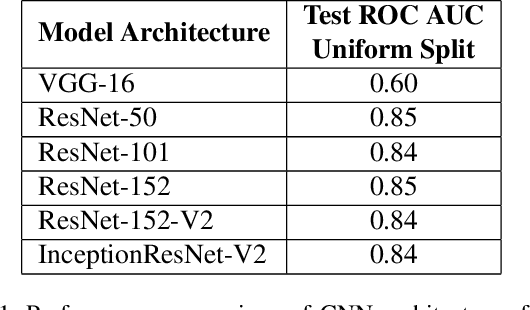
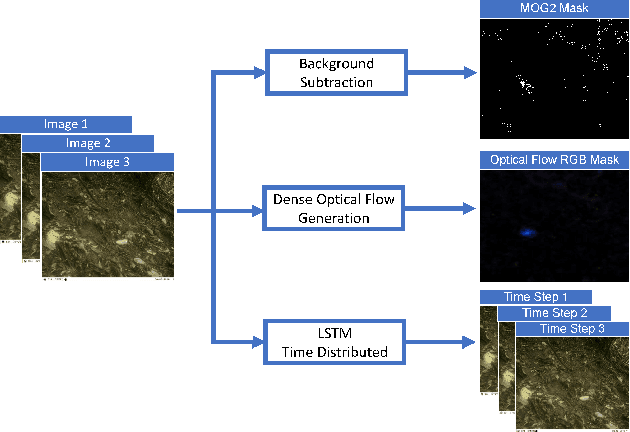
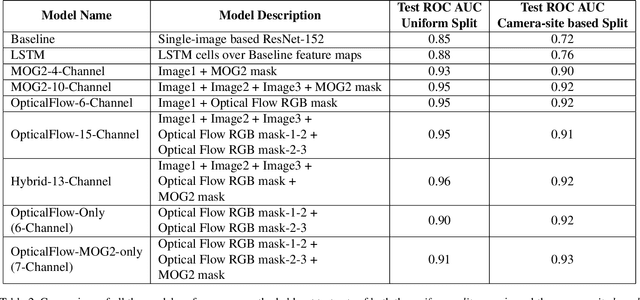
Camera Traps are extensively used to observe wildlife in their natural habitat without disturbing the ecosystem. This could help in the early detection of natural or human threats to animals, and help towards ecological conservation. Currently, a massive number of such camera traps have been deployed at various ecological conservation areas around the world, collecting data for decades, thereby requiring automation to detect images containing animals. Existing systems perform classification to detect if images contain animals by considering a single image. However, due to challenging scenes with animals camouflaged in their natural habitat, it sometimes becomes difficult to identify the presence of animals from merely a single image. We hypothesize that a short burst of images instead of a single image, assuming that the animal moves, makes it much easier for a human as well as a machine to detect the presence of animals. In this work, we explore a variety of approaches, and measure the impact of using short image sequences (burst of 3 images) on improving the camera trap image classification. We show that concatenating masks containing sequence information and the images from the 3-image-burst across channels, improves the ROC AUC by 20% on a test-set from unseen camera-sites, as compared to an equivalent model that learns from a single image.
The GeoLifeCLEF 2020 Dataset
Apr 08, 2020
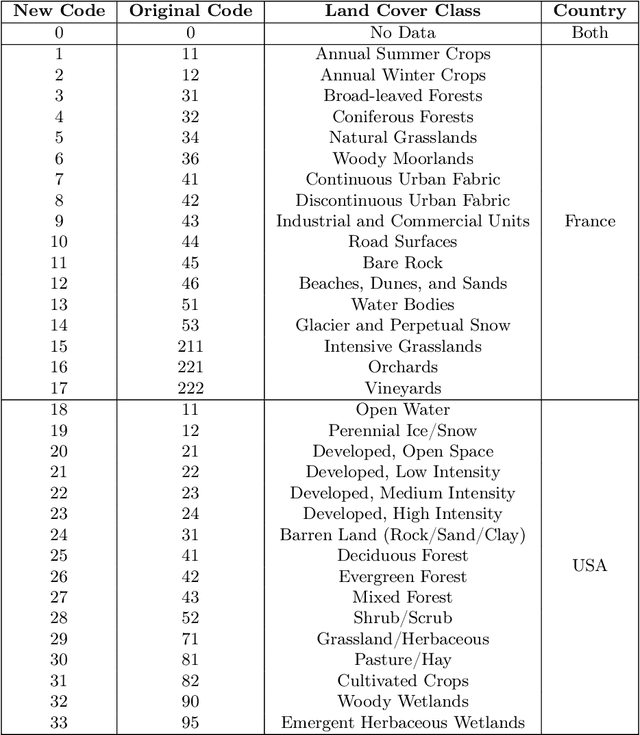
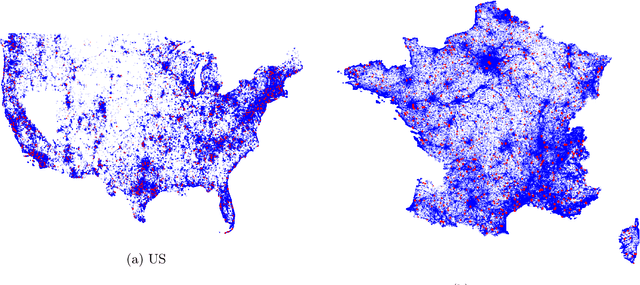
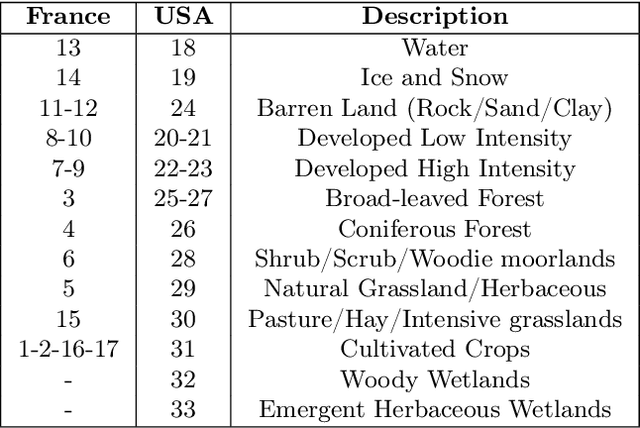
Understanding the geographic distribution of species is a key concern in conservation. By pairing species occurrences with environmental features, researchers can model the relationship between an environment and the species which may be found there. To facilitate research in this area, we present the GeoLifeCLEF 2020 dataset, which consists of 1.9 million species observations paired with high-resolution remote sensing imagery, land cover data, and altitude, in addition to traditional low-resolution climate and soil variables. We also discuss the GeoLifeCLEF 2020 competition, which aims to use this dataset to advance the state-of-the-art in location-based species recommendation.
Local Context Normalization: Revisiting Local Normalization
Dec 13, 2019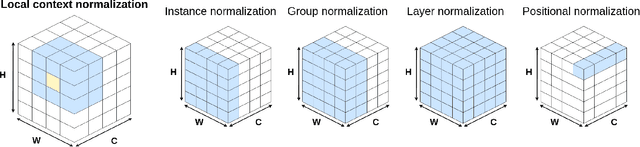
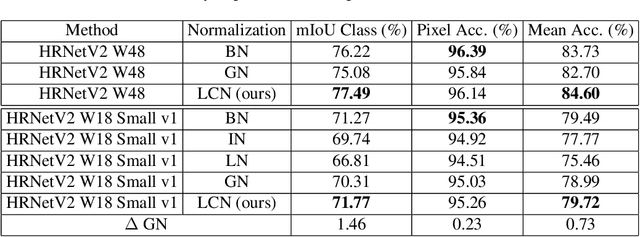
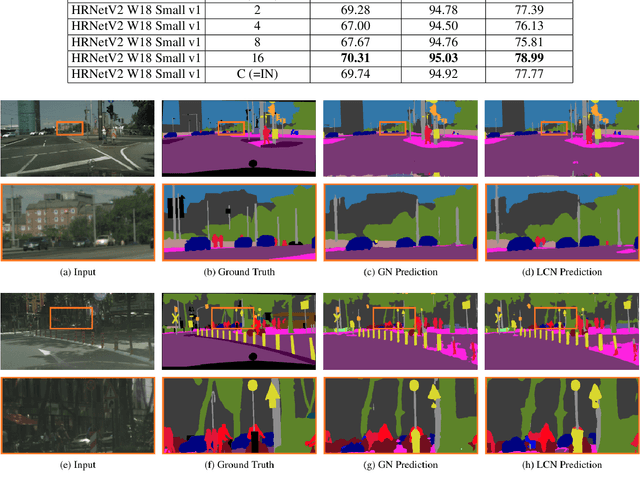

Normalization layers have been shown to improve convergence in deep neural networks. In many vision applications the local spatial context of the features is important, but most common normalization schemes includingGroup Normalization (GN), Instance Normalization (IN), and Layer Normalization (LN) normalize over the entire spatial dimension of a feature. This can wash out important signals and degrade performance. For example, in applications that use satellite imagery, input images can be arbitrarily large; consequently, it is nonsensical to normalize over the entire area. Positional Normalization (PN), on the other hand, only normalizes over a single spatial position at a time. A natural compromise is to normalize features by local context, while also taking into account group level information. In this paper, we propose Local Context Normalization (LCN): a normalization layer where every feature is normalized based on a window around it and the filters in its group. We propose an algorithmic solution to make LCN efficient for arbitrary window sizes, even if every point in the image has a unique window. LCN outperforms its Batch Normalization (BN), GN, IN, and LN counterparts for object detection, semantic segmentation, and instance segmentation applications in several benchmark datasets, while keeping performance independent of the batch size and facilitating transfer learning.
A deep active learning system for species identification and counting in camera trap images
Oct 22, 2019

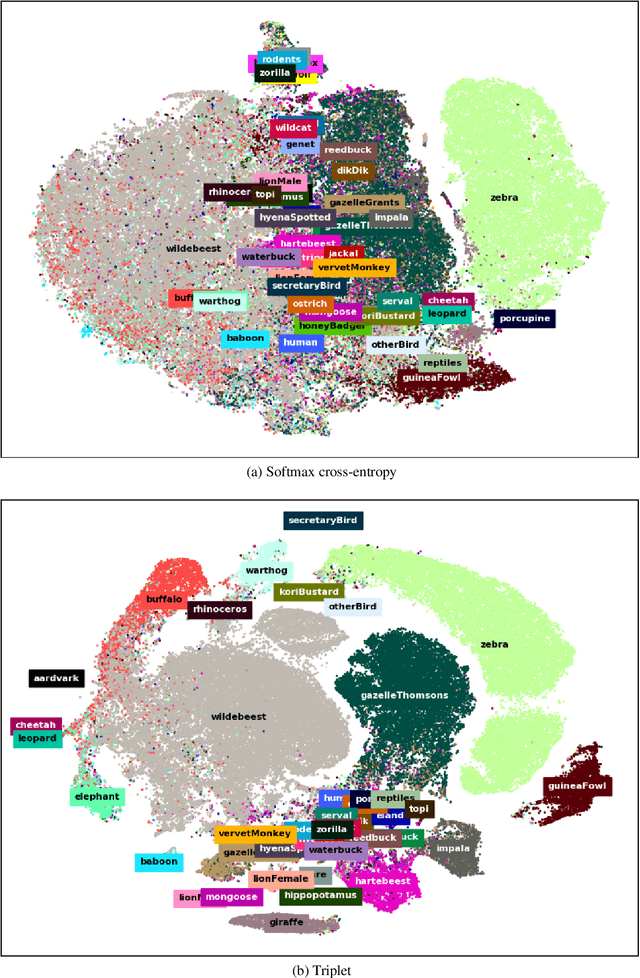
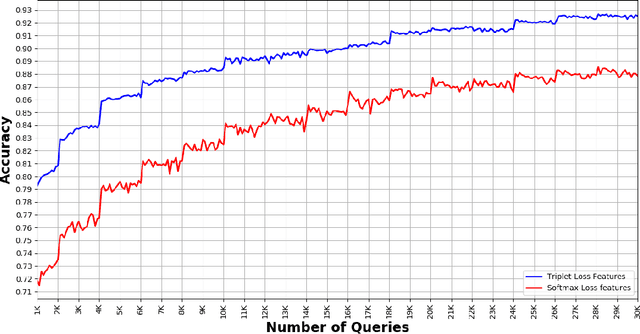
Biodiversity conservation depends on accurate, up-to-date information about wildlife population distributions. Motion-activated cameras, also known as camera traps, are a critical tool for population surveys, as they are cheap and non-intrusive. However, extracting useful information from camera trap images is a cumbersome process: a typical camera trap survey may produce millions of images that require slow, expensive manual review. Consequently, critical information is often lost due to resource limitations, and critical conservation questions may be answered too slowly to support decision-making. Computer vision is poised to dramatically increase efficiency in image-based biodiversity surveys, and recent studies have harnessed deep learning techniques for automatic information extraction from camera trap images. However, the accuracy of results depends on the amount, quality, and diversity of the data available to train models, and the literature has focused on projects with millions of relevant, labeled training images. Many camera trap projects do not have a large set of labeled images and hence cannot benefit from existing machine learning techniques. Furthermore, even projects that do have labeled data from similar ecosystems have struggled to adopt deep learning methods because image classification models overfit to specific image backgrounds (i.e., camera locations). In this paper, we focus not on automating the labeling of camera trap images, but on accelerating this process. We combine the power of machine intelligence and human intelligence to build a scalable, fast, and accurate active learning system to minimize the manual work required to identify and count animals in camera trap images. Our proposed scheme can match the state of the art accuracy on a 3.2 million image dataset with as few as 14,100 manual labels, which means decreasing manual labeling effort by over 99.5%.
Efficient Pipeline for Camera Trap Image Review
Jul 15, 2019Biologists all over the world use camera traps to monitor biodiversity and wildlife population density. The computer vision community has been making strides towards automating the species classification challenge in camera traps, but it has proven difficult to to apply models trained in one region to images collected in different geographic areas. In some cases, accuracy falls off catastrophically in new region, due to both changes in background and the presence of previously-unseen species. We propose a pipeline that takes advantage of a pre-trained general animal detector and a smaller set of labeled images to train a classification model that can efficiently achieve accurate results in a new region.
The iWildCam 2019 Challenge Dataset
Jul 15, 2019

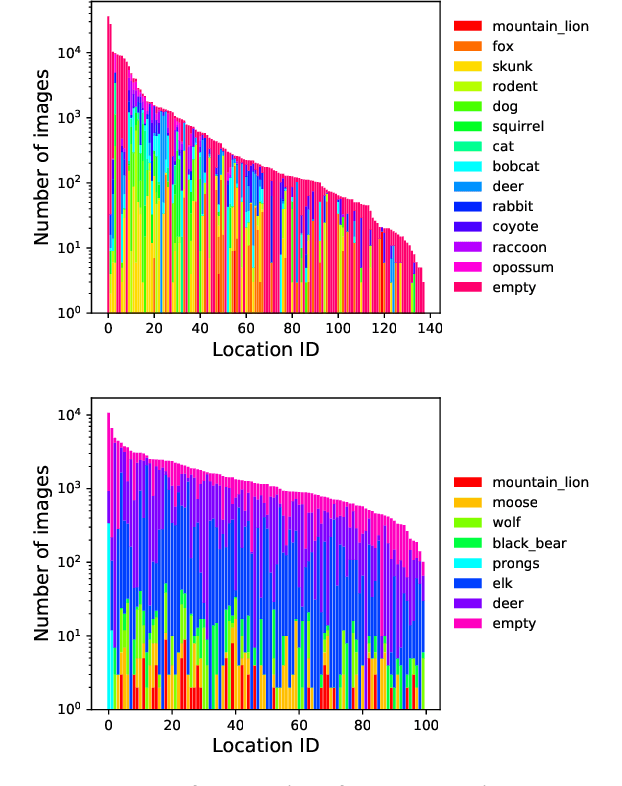
Camera Traps (or Wild Cams) enable the automatic collection of large quantities of image data. Biologists all over the world use camera traps to monitor biodiversity and population density of animal species. The computer vision community has been making strides towards automating the species classification challenge in camera traps, but as we try to expand the scope of these models from specific regions where we have collected training data to different areas we are faced with an interesting problem: how do you classify a species in a new region that you may not have seen in previous training data? In order to tackle this problem, we have prepared a dataset and challenge where the training data and test data are from different regions, namely The American Southwest and the American Northwest. We use the Caltech Camera Traps dataset, collected from the American Southwest, as training data. We add a new dataset from the American Northwest, curated from data provided by the Idaho Department of Fish and Game (IDFG), as our test dataset. The test data has some class overlap with the training data, some species are found in both datasets, but there are both species seen during training that are not seen during test and vice versa. To help fill the gaps in the training species, we allow competitors to utilize transfer learning from two alternate domains: human-curated images from iNaturalist and synthetic images from Microsoft's TrapCam-AirSim simulation environment.
Human-Machine Collaboration for Fast Land Cover Mapping
Jun 26, 2019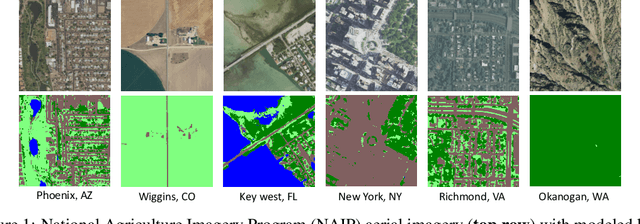
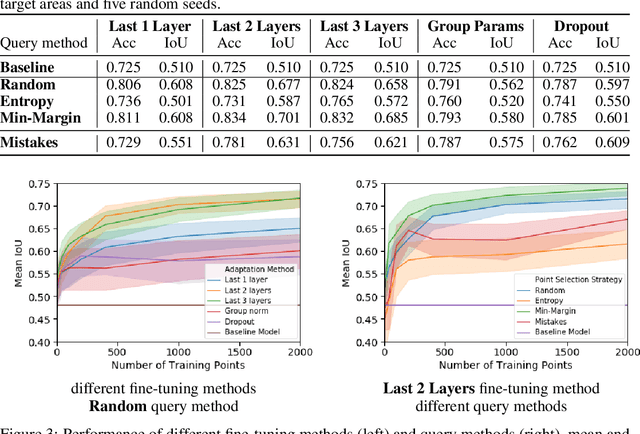
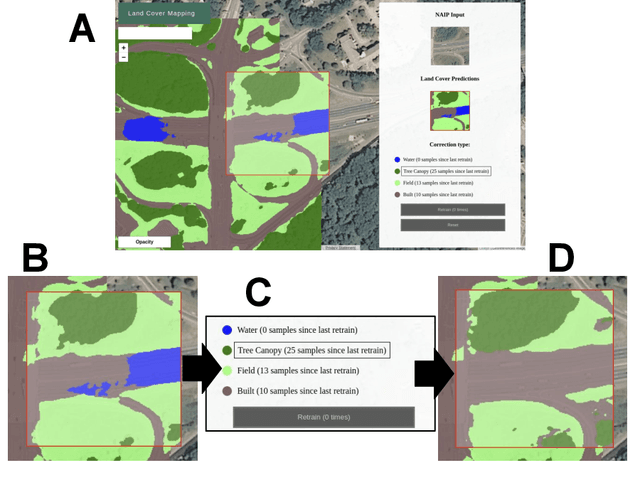
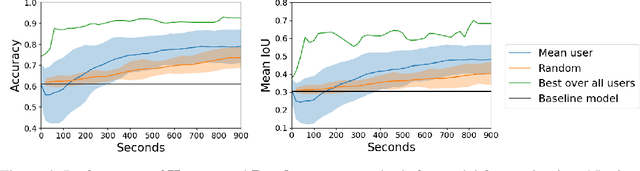
We propose incorporating human labelers in a model fine-tuning system that provides immediate user feedback. In our framework, human labelers can interactively query model predictions on unlabeled data, choose which data to label, and see the resulting effect on the model's predictions. This bi-directional feedback loop allows humans to learn how the model responds to new data. Our hypothesis is that this rich feedback allows human labelers to create mental models that enable them to better choose which biases to introduce to the model. We compare human-selected points to points selected using standard active learning methods. We further investigate how the fine-tuning methodology impacts the human labelers' performance. We implement this framework for fine-tuning high-resolution land cover segmentation models. Specifically, we fine-tune a deep neural network -- trained to segment high-resolution aerial imagery into different land cover classes in Maryland, USA -- to a new spatial area in New York, USA. The tight loop turns the algorithm and the human operator into a hybrid system that can produce land cover maps of a large area much more efficiently than the traditional workflows. Our framework has applications in geospatial machine learning settings where there is a practically limitless supply of unlabeled data, of which only a small fraction can feasibly be labeled through human efforts.
Synthetic Examples Improve Generalization for Rare Classes
May 14, 2019
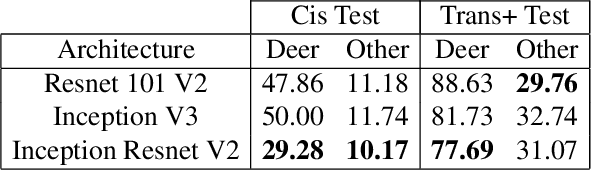

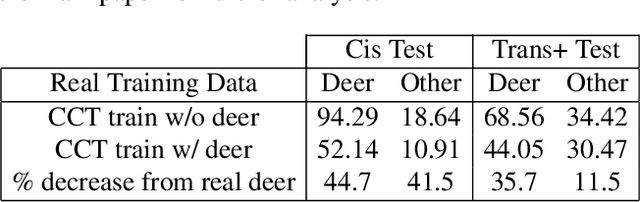
The ability to detect and classify rare occurrences in images has important applications - for example, counting rare and endangered species when studying biodiversity, or detecting infrequent traffic scenarios that pose a danger to self-driving cars. Few-shot learning is an open problem: current computer vision systems struggle to categorize objects they have seen only rarely during training, and collecting a sufficient number of training examples of rare events is often challenging and expensive, and sometimes outright impossible. We explore in depth an approach to this problem: complementing the few available training images with ad-hoc simulated data. Our testbed is animal species classification, which has a real-world long-tailed distribution. We analyze the effect of different axes of variation in simulation, such as pose, lighting, model, and simulation method, and we prescribe best practices for efficiently incorporating simulated data for real-world performance gain. Our experiments reveal that synthetic data can considerably reduce error rates for classes that are rare, that as the amount of simulated data is increased, accuracy on the target class improves, and that high variation of simulated data provides maximum performance gain.