 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining self-similarity: Label super-resolution with epitomic representations
Apr 24, 2020
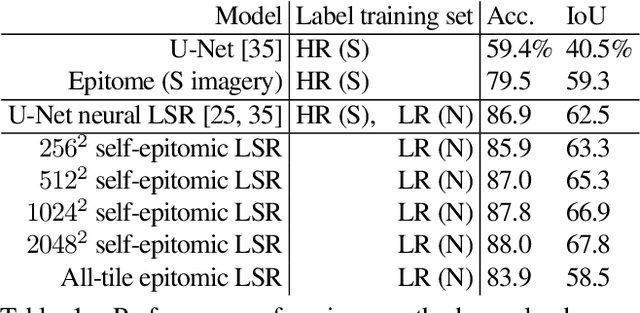

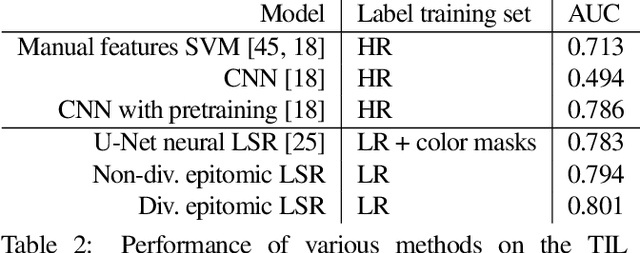
We show that simple patch-based models, such as epitomes, can have superior performance to the current state of the art in semantic segmentation and label super-resolution, which uses deep convolutional neural networks. We derive a new training algorithm for epitomes which allows, for the first time, learning from very large data sets and derive a label super-resolution algorithm as a statistical inference algorithm over epitomic representations. We illustrate our methods on land cover mapping and medical image analysis tasks.
Human-Machine Collaboration for Fast Land Cover Mapping
Jun 26, 2019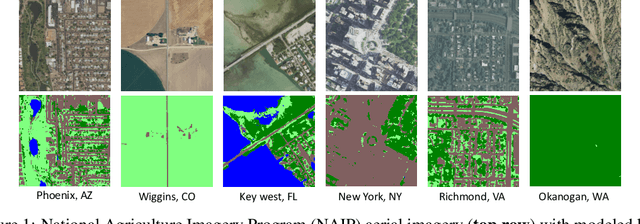
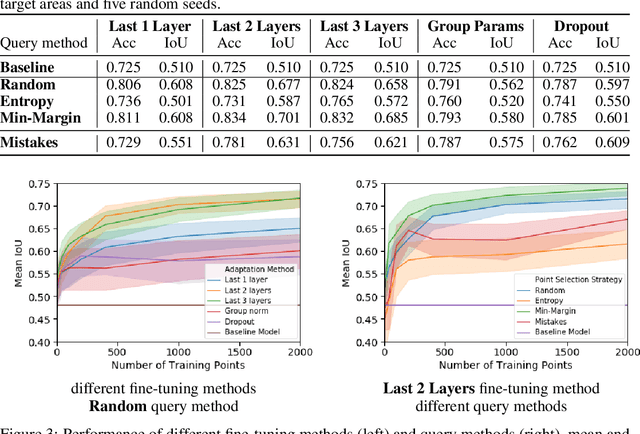
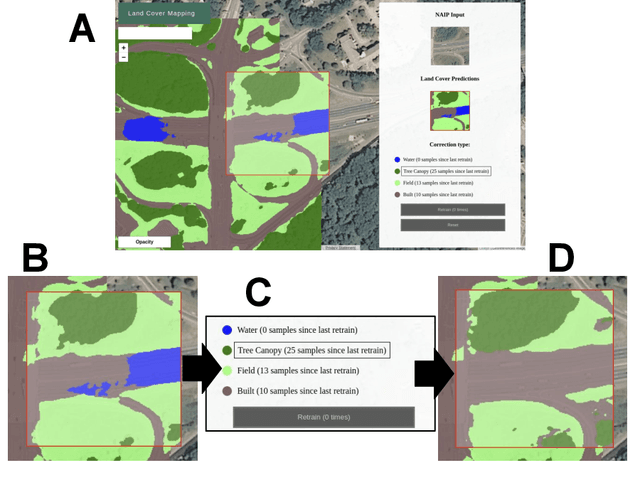
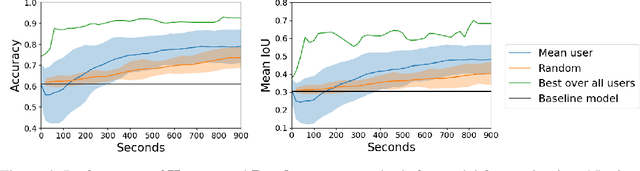
We propose incorporating human labelers in a model fine-tuning system that provides immediate user feedback. In our framework, human labelers can interactively query model predictions on unlabeled data, choose which data to label, and see the resulting effect on the model's predictions. This bi-directional feedback loop allows humans to learn how the model responds to new data. Our hypothesis is that this rich feedback allows human labelers to create mental models that enable them to better choose which biases to introduce to the model. We compare human-selected points to points selected using standard active learning methods. We further investigate how the fine-tuning methodology impacts the human labelers' performance. We implement this framework for fine-tuning high-resolution land cover segmentation models. Specifically, we fine-tune a deep neural network -- trained to segment high-resolution aerial imagery into different land cover classes in Maryland, USA -- to a new spatial area in New York, USA. The tight loop turns the algorithm and the human operator into a hybrid system that can produce land cover maps of a large area much more efficiently than the traditional workflows. Our framework has applications in geospatial machine learning settings where there is a practically limitless supply of unlabeled data, of which only a small fraction can feasibly be labeled through human efforts.
Label Super Resolution with Inter-Instance Loss
Apr 09, 2019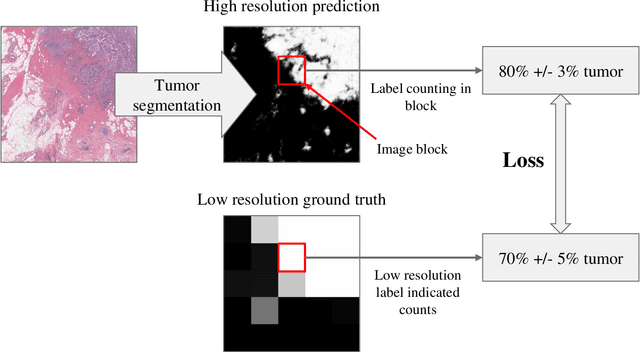
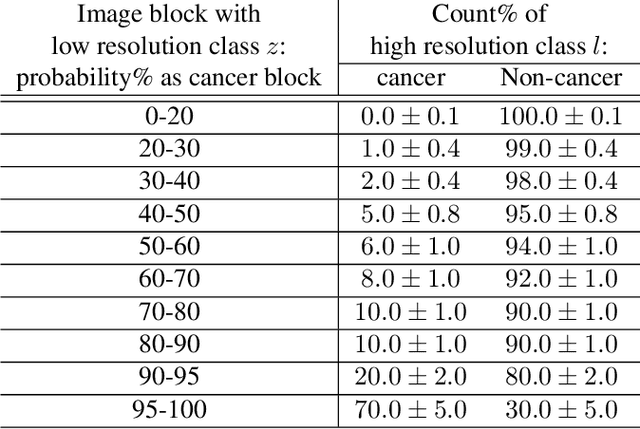
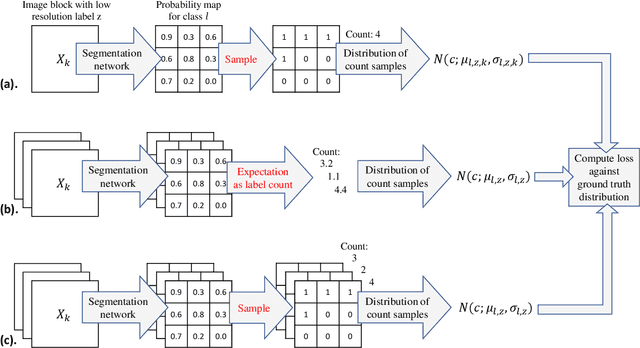

For the task of semantic segmentation, high-resolution (pixel-level) ground truth is very expensive to collect, especially for high resolution images such as gigapixel pathology images. On the other hand, collecting low resolution labels (labels for a block of pixels) for these high resolution images is much more cost efficient. Conventional methods trained on these low-resolution labels are only capable of giving low-resolution predictions. The existing state-of-the-art label super resolution (LSR) method is capable of predicting high resolution labels, using only low-resolution supervision, given the joint distribution between low resolution and high resolution labels. However, it does not consider the inter-instance variance which is crucial in the ideal mathematical formulation. In this work, we propose a novel loss function modeling the inter-instance variance. We test our method on two real world applications: cell detection in multiplex immunohistochemistry (IHC) images, and infiltrating breast cancer region segmentation in histopathology slides. Experimental results show the effectiveness of our method.