 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained System Identification of Nonlinear Neural Circuits
Jun 09, 2021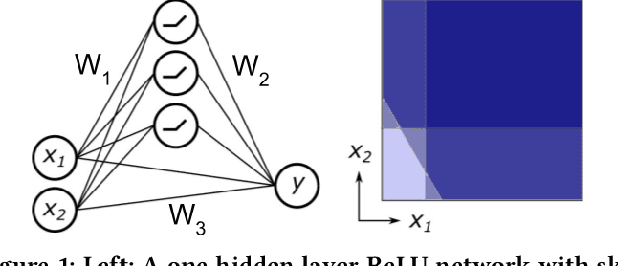
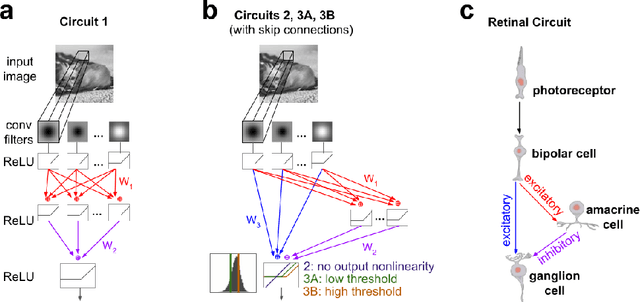
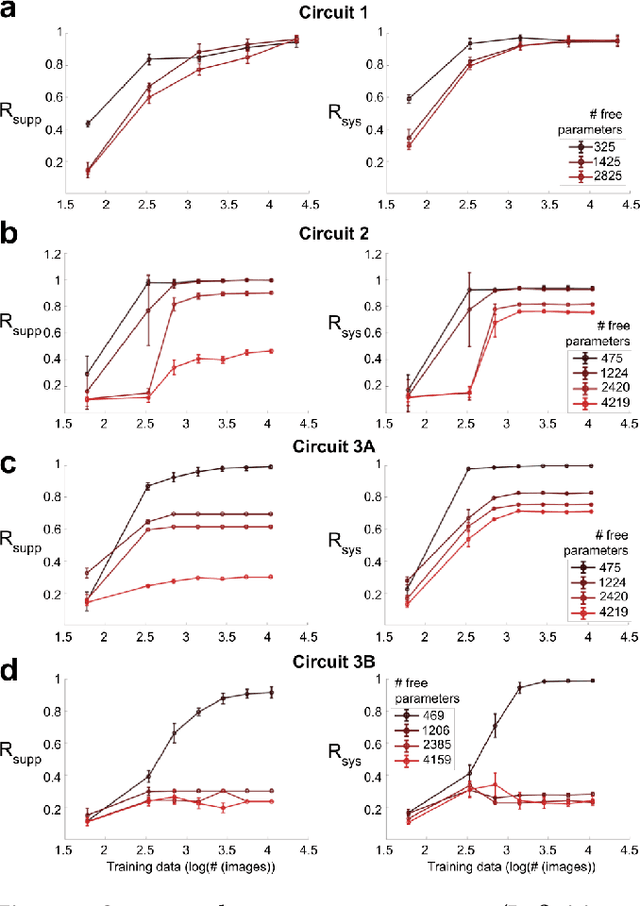
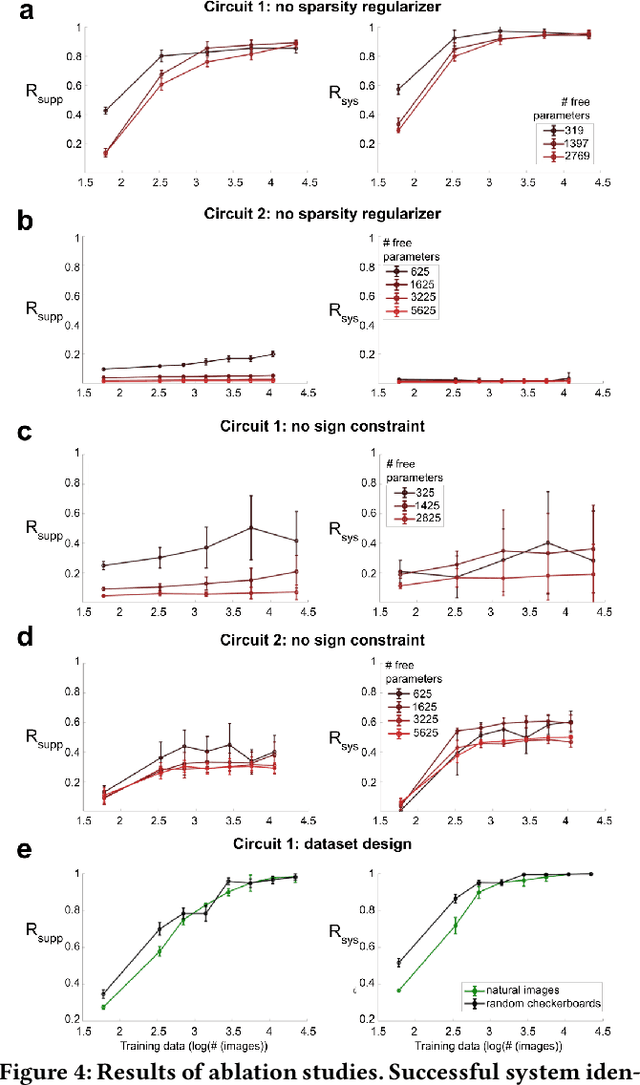
We study the problem of sparse nonlinear model recovery of high dimensional compositional functions. Our study is motivated by emerging opportunities in neuroscience to recover fine-grained models of biological neural circuits using collected measurement data. Guided by available domain knowledge in neuroscience, we explore conditions under which one can recover the underlying biological circuit that generated the training data. Our results suggest insights of both theoretical and practical interests. Most notably, we find that a sign constraint on the weights is a necessary condition for system recovery, which we establish both theoretically with an identifiability guarantee and empirically on simulated biological circuits. We conclude with a case study on retinal ganglion cell circuits using data collected from mouse retina, showcasing the practical potential of this approach.
Learning by Turning: Neural Architecture Aware Optimisation
Feb 14, 2021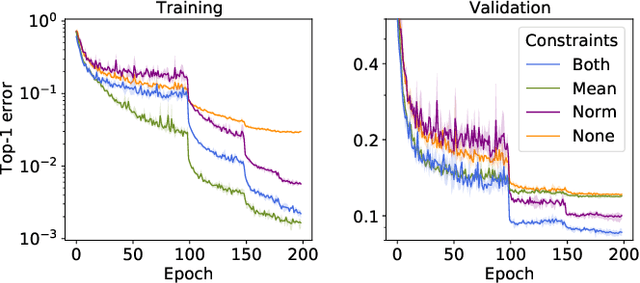

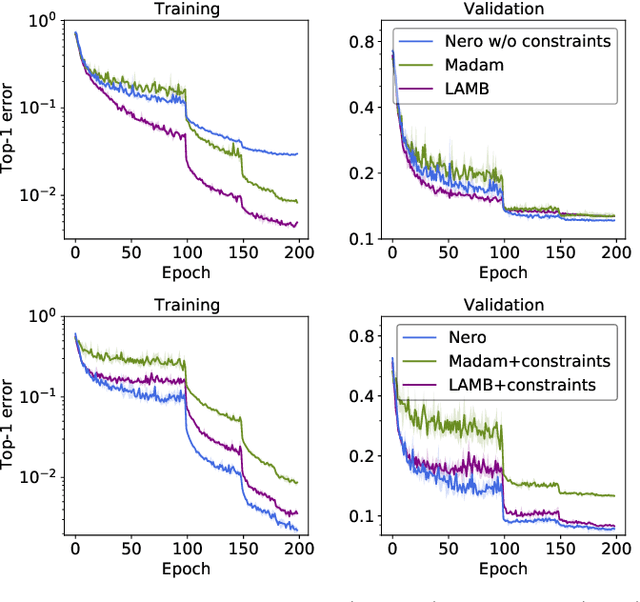
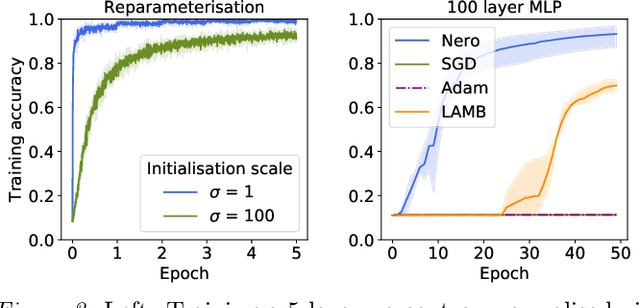
Descent methods for deep networks are notoriously capricious: they require careful tuning of step size, momentum and weight decay, and which method will work best on a new benchmark is a priori unclear. To address this problem, this paper conducts a combined study of neural architecture and optimisation, leading to a new optimiser called Nero: the neuronal rotator. Nero trains reliably without momentum or weight decay, works in situations where Adam and SGD fail, and requires little to no learning rate tuning. Also, Nero's memory footprint is ~ square root that of Adam or LAMB. Nero combines two ideas: (1) projected gradient descent over the space of balanced networks; (2) neuron-specific updates, where the step size sets the angle through which each neuron's hyperplane turns. The paper concludes by discussing how this geometric connection between architecture and optimisation may impact theories of generalisation in deep learning.
Factorized linear discriminant analysis for phenotype-guided representation learning of neuronal gene expression data
Oct 05, 2020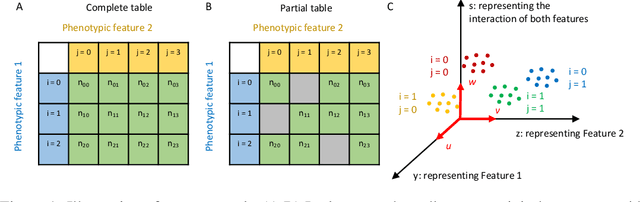
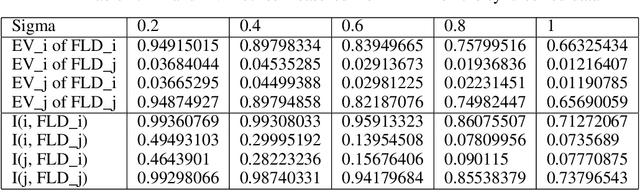
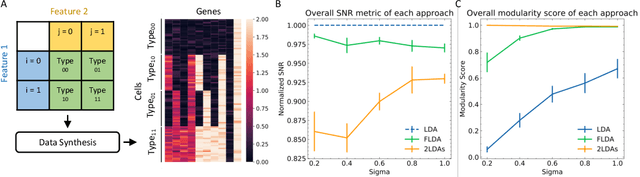
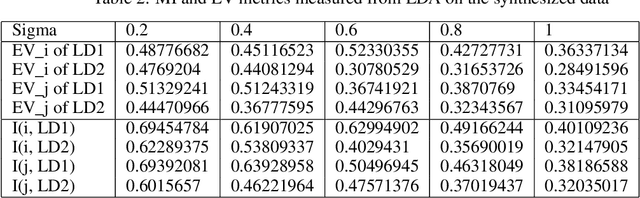
A central goal in neurobiology is to relate the expression of genes to the structural and functional properties of neuronal types, collectively called their phenotypes. Single-cell RNA sequencing can measure the expression of thousands of genes in thousands of neurons. How to interpret the data in the context of neuronal phenotypes? We propose a supervised learning approach that factorizes the gene expression data into components corresponding to individual phenotypic characteristics and their interactions. This new method, which we call factorized linear discriminant analysis (FLDA), seeks a linear transformation of gene expressions that varies highly with only one phenotypic factor and minimally with the others. We further leverage our approach with a sparsity-based regularization algorithm, which selects a few genes important to a specific phenotypic feature or feature combination. We applied this approach to a single-cell RNA-Seq dataset of Drosophila T4/T5 neurons, focusing on their dendritic and axonal phenotypes. The analysis confirms results from the previous report but also points to new genes related to the phenotypes and an intriguing hierarchy in the genetic organization of these cells.
Learning compositional functions via multiplicative weight updates
Jun 25, 2020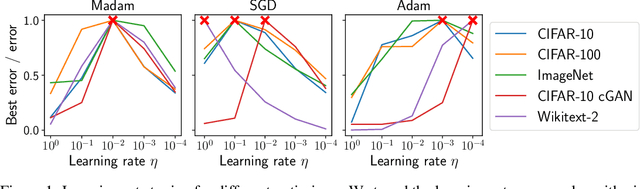
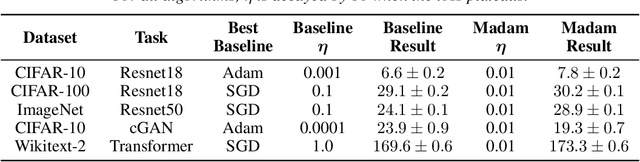

Compositionality is a basic structural feature of both biological and artificial neural networks. Learning compositional functions via gradient descent incurs well known problems like vanishing and exploding gradients, making careful learning rate tuning essential for real-world applications. This paper proves that multiplicative weight updates satisfy a descent lemma tailored to compositional functions. Based on this lemma, we derive Madam---a multiplicative version of the Adam optimiser---and show that it can train state of the art neural network architectures without learning rate tuning. We further show that Madam is easily adapted to train natively compressed neural networks by representing their weights in a logarithmic number system. We conclude by drawing connections between multiplicative weight updates and recent findings about synapses in biology.
PanDA: Panoptic Data Augmentation
Nov 27, 2019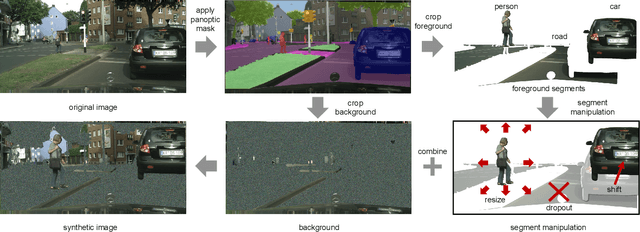



The recently proposed panoptic segmentation task presents a significant challenge of image understanding with computer vision by unifying semantic segmentation and instance segmentation tasks. In this paper we present an efficient and novel panoptic data augmentation (PanDA) method which operates exclusively in pixel space, requires no additional data or training, and is computationally cheap to implement. We retrain the original state-of-the-art UPSNet panoptic segmentation model on PanDA augmented Cityscapes dataset, and demonstrate all-round performance improvement upon the original model. We also show that PanDA is effective across scales from 10 to 30,000 images, as well as generalizable to Microsoft COCO panoptic segmentation task. Finally, the effectiveness of PanDA generated unrealistic-looking training images suggest that we should rethink about optimizing levels of image realism for efficient data augmentation.
Synthetic Examples Improve Generalization for Rare Classes
May 14, 2019
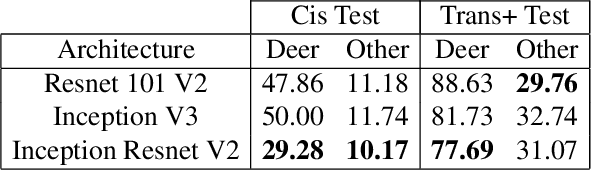

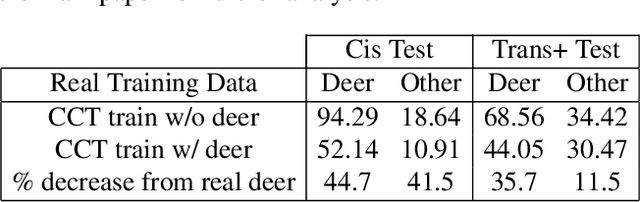
The ability to detect and classify rare occurrences in images has important applications - for example, counting rare and endangered species when studying biodiversity, or detecting infrequent traffic scenarios that pose a danger to self-driving cars. Few-shot learning is an open problem: current computer vision systems struggle to categorize objects they have seen only rarely during training, and collecting a sufficient number of training examples of rare events is often challenging and expensive, and sometimes outright impossible. We explore in depth an approach to this problem: complementing the few available training images with ad-hoc simulated data. Our testbed is animal species classification, which has a real-world long-tailed distribution. We analyze the effect of different axes of variation in simulation, such as pose, lighting, model, and simulation method, and we prescribe best practices for efficiently incorporating simulated data for real-world performance gain. Our experiments reveal that synthetic data can considerably reduce error rates for classes that are rare, that as the amount of simulated data is increased, accuracy on the target class improves, and that high variation of simulated data provides maximum performance gain.