 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Evolutionary Cell Type Matching via Entropy-Minimized Optimal Transport
May 30, 2025Identifying evolutionary correspondences between cell types across species is a fundamental challenge in comparative genomics and evolutionary biology. Existing approaches often rely on either reference-based matching, which imposes asymmetry by designating one species as the reference, or projection-based matching, which may increase computational complexity and obscure biological interpretability at the cell-type level. Here, we present OT-MESH, an unsupervised computational framework leveraging entropy-regularized optimal transport (OT) to systematically determine cross-species cell type homologies. Our method uniquely integrates the Minimize Entropy of Sinkhorn (MESH) technique to refine the OT plan. It begins by selecting genes with high Signal-to-Noise Ratio (SNR) to capture the most informative features, from which a cost matrix is constructed using cosine distances between cell-type centroids. Importantly, the MESH procedure iteratively refines the cost matrix, leading to a transport plan with significantly enhanced sparsity and interpretability of the resulting correspondence matrices. Applied to retinal bipolar cells (BCs) and retinal ganglion cells (RGCs) from mouse and macaque, OT-MESH accurately recovers known evolutionary relationships and uncovers novel correspondences, one of which was independently validated experimentally. Thus, our framework offers a principled, scalable, symmetric, and interpretable solution for evolutionary cell type mapping, facilitating deeper insights into cellular specialization and conservation across species.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025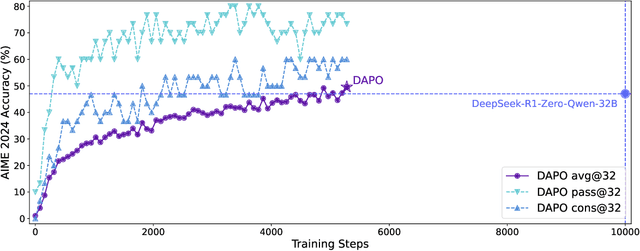

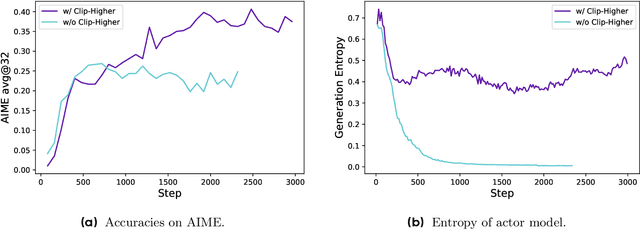

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
OCSU: Optical Chemical Structure Understanding for Molecule-centric Scientific Discovery
Jan 26, 2025Understanding the chemical structure from a graphical representation of a molecule is a challenging image caption task that would greatly benefit molecule-centric scientific discovery. Variations in molecular images and caption subtasks pose a significant challenge in both image representation learning and task modeling. Yet, existing methods only focus on a specific caption task that translates a molecular image into its graph structure, i.e., OCSR. In this paper, we propose the Optical Chemical Structure Understanding (OCSU) task, which extends OCSR to molecular image caption from motif level to molecule level and abstract level. We present two approaches for that, including an OCSR-based method and an end-to-end OCSR-free method. The proposed Double-Check achieves SOTA OCSR performance on real-world patent and journal article scenarios via attentive feature enhancement for local ambiguous atoms. Cascading with SMILES-based molecule understanding methods, it can leverage the power of existing task-specific models for OCSU. While Mol-VL is an end-to-end optimized VLM-based model. An OCSU dataset, Vis-CheBI20, is built based on the widely used CheBI20 dataset for training and evaluation. Extensive experimental results on Vis-CheBI20 demonstrate the effectiveness of the proposed approaches. Improving OCSR capability can lead to a better OCSU performance for OCSR-based approach, and the SOTA performance of Mol-VL demonstrates the great potential of end-to-end approach.
Reach Measurement, Optimization and Frequency Capping In Targeted Online Advertising Under k-Anonymity
Jan 08, 2025



The growth in the use of online advertising to foster brand awareness over recent years is largely attributable to the ubiquity of social media. One pivotal technology contributing to the success of online brand advertising is frequency capping, a mechanism that enables marketers to control the number of times an ad is shown to a specific user. However, the very foundation of this technology is being scrutinized as the industry gravitates towards advertising solutions that prioritize user privacy. This paper delves into the issue of reach measurement and optimization within the context of $k$-anonymity, a privacy-preserving model gaining traction across major online advertising platforms. We outline how to report reach within this new privacy landscape and demonstrate how probabilistic discounting, a probabilistic adaptation of traditional frequency capping, can be employed to optimize campaign performance. Experiments are performed to assess the trade-off between user privacy and the efficacy of online brand advertising. Notably, we discern a significant dip in performance as long as privacy is introduced, yet this comes with a limited additional cost for advertising platforms to offer their users more privacy.
GNN-Ensemble: Towards Random Decision Graph Neural Networks
Mar 20, 2023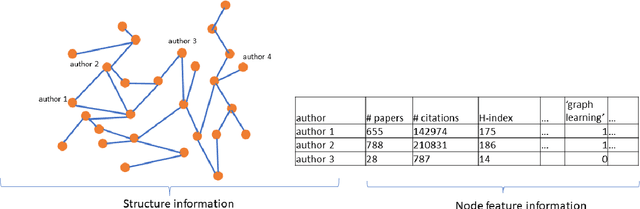
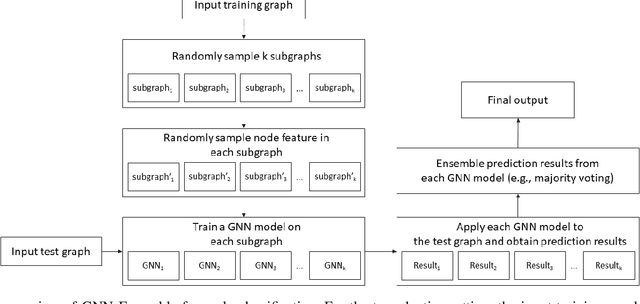

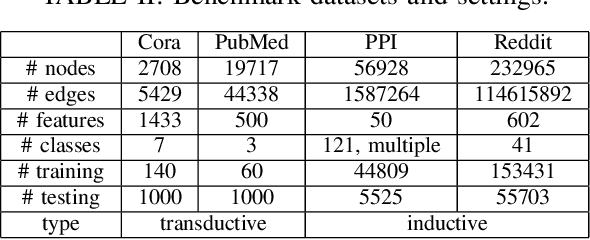
Graph Neural Networks (GNNs) have enjoyed wide spread applications in graph-structured data. However, existing graph based applications commonly lack annotated data. GNNs are required to learn latent patterns from a limited amount of training data to perform inferences on a vast amount of test data. The increased complexity of GNNs, as well as a single point of model parameter initialization, usually lead to overfitting and sub-optimal performance. In addition, it is known that GNNs are vulnerable to adversarial attacks. In this paper, we push one step forward on the ensemble learning of GNNs with improved accuracy, generalization, and adversarial robustness. Following the principles of stochastic modeling, we propose a new method called GNN-Ensemble to construct an ensemble of random decision graph neural networks whose capacity can be arbitrarily expanded for improvement in performance. The essence of the method is to build multiple GNNs in randomly selected substructures in the topological space and subfeatures in the feature space, and then combine them for final decision making. These GNNs in different substructure and subfeature spaces generalize their classification in complementary ways. Consequently, their combined classification performance can be improved and overfitting on the training data can be effectively reduced. In the meantime, we show that GNN-Ensemble can significantly improve the adversarial robustness against attacks on GNNs.
Towards a New Science of Disinformation
Mar 17, 2022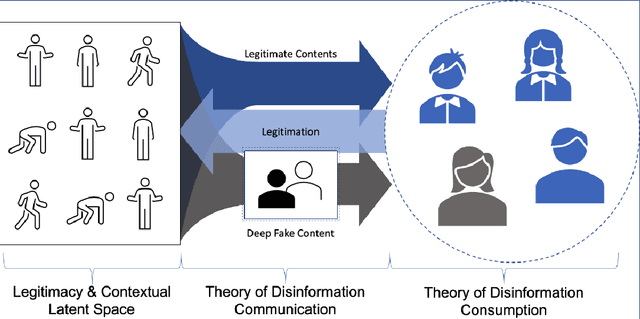

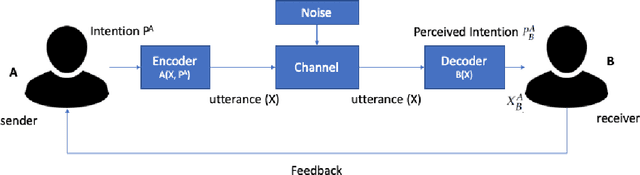
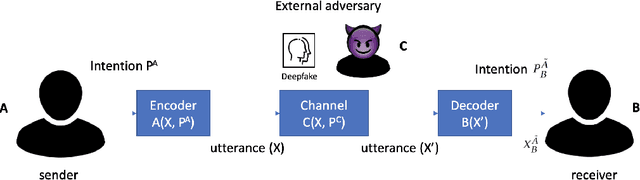
How can we best address the dangerous impact that deep learning-generated fake audios, photographs, and videos (a.k.a. deepfakes) may have in personal and societal life? We foresee that the availability of cheap deepfake technology will create a second wave of disinformation where people will receive specific, personalized disinformation through different channels, making the current approaches to fight disinformation obsolete. We argue that fake media has to be seen as an upcoming cybersecurity problem, and we have to shift from combating its spread to a prevention and cure framework where users have available ways to verify, challenge, and argue against the veracity of each piece of media they are exposed to. To create the technologies behind this framework, we propose that a new Science of Disinformation is needed, one which creates a theoretical framework both for the processes of communication and consumption of false content. Key scientific and technological challenges facing this research agenda are listed and discussed in the light of state-of-art technologies for fake media generation and detection, argument finding and construction, and how to effectively engage users in the prevention and cure processes.
Dual-view Snapshot Compressive Imaging via Optical Flow Aided Recurrent Neural Network
Sep 11, 2021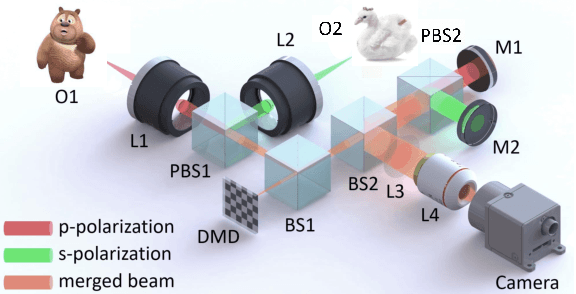
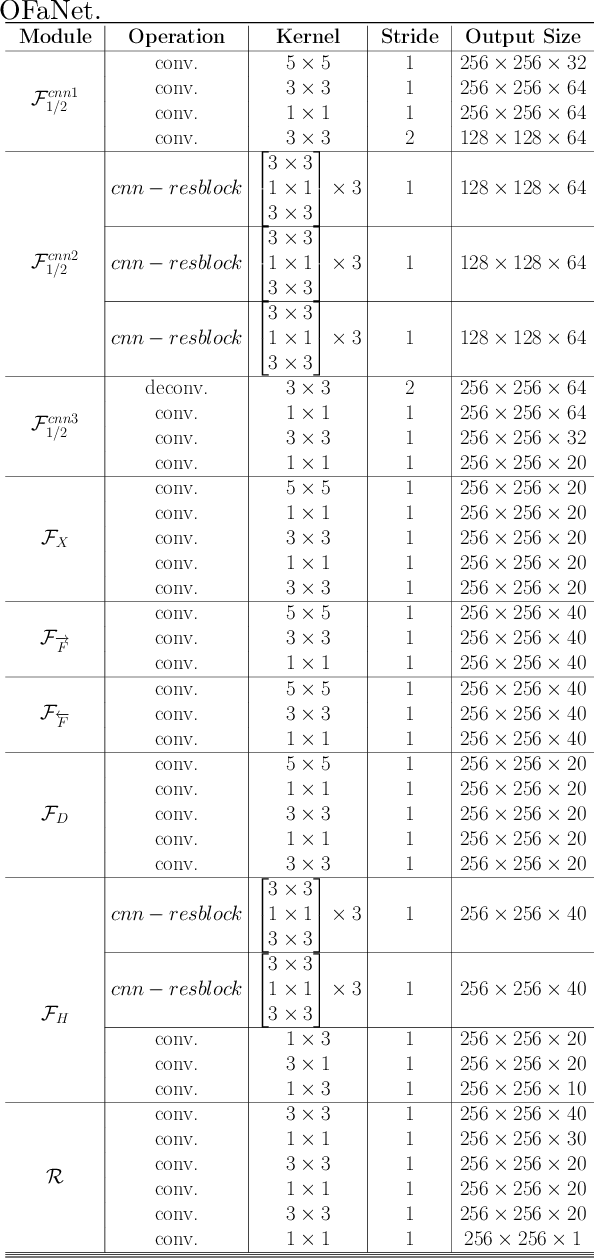

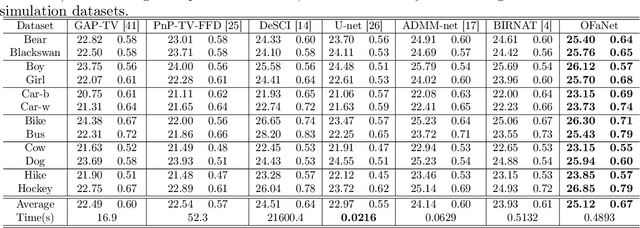
Dual-view snapshot compressive imaging (SCI) aims to capture videos from two field-of-views (FoVs) using a 2D sensor (detector) in a single snapshot, achieving joint FoV and temporal compressive sensing, and thus enjoying the advantages of low-bandwidth, low-power, and low-cost. However, it is challenging for existing model-based decoding algorithms to reconstruct each individual scene, which usually require exhaustive parameter tuning with extremely long running time for large scale data. In this paper, we propose an optical flow-aided recurrent neural network for dual video SCI systems, which provides high-quality decoding in seconds. Firstly, we develop a diversity amplification method to enlarge the differences between scenes of two FoVs, and design a deep convolutional neural network with dual branches to separate different scenes from the single measurement. Secondly, we integrate the bidirectional optical flow extracted from adjacent frames with the recurrent neural network to jointly reconstruct each video in a sequential manner. Extensive results on both simulation and real data demonstrate the superior performance of our proposed model in a short inference time. The code and data are available at https://github.com/RuiyingLu/OFaNet-for-Dual-view-SCI.
Factorized linear discriminant analysis for phenotype-guided representation learning of neuronal gene expression data
Oct 05, 2020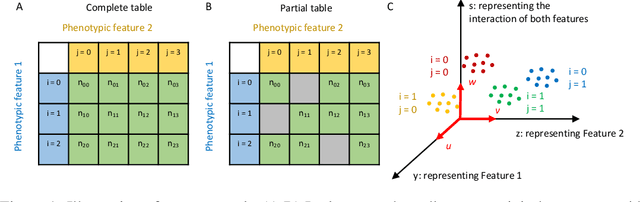
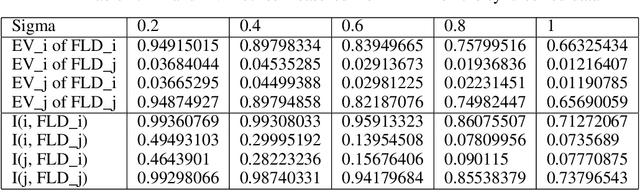
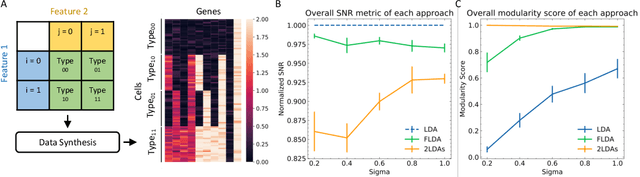
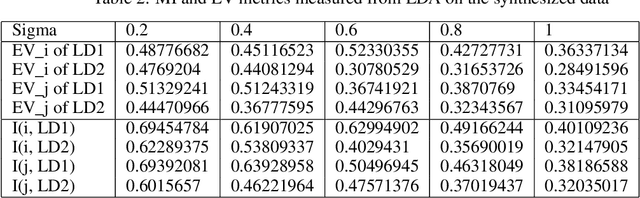
A central goal in neurobiology is to relate the expression of genes to the structural and functional properties of neuronal types, collectively called their phenotypes. Single-cell RNA sequencing can measure the expression of thousands of genes in thousands of neurons. How to interpret the data in the context of neuronal phenotypes? We propose a supervised learning approach that factorizes the gene expression data into components corresponding to individual phenotypic characteristics and their interactions. This new method, which we call factorized linear discriminant analysis (FLDA), seeks a linear transformation of gene expressions that varies highly with only one phenotypic factor and minimally with the others. We further leverage our approach with a sparsity-based regularization algorithm, which selects a few genes important to a specific phenotypic feature or feature combination. We applied this approach to a single-cell RNA-Seq dataset of Drosophila T4/T5 neurons, focusing on their dendritic and axonal phenotypes. The analysis confirms results from the previous report but also points to new genes related to the phenotypes and an intriguing hierarchy in the genetic organization of these cells.
Temporal Tensor Transformation Network for Multivariate Time Series Prediction
Jan 04, 2020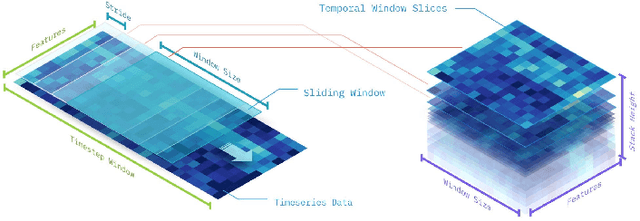
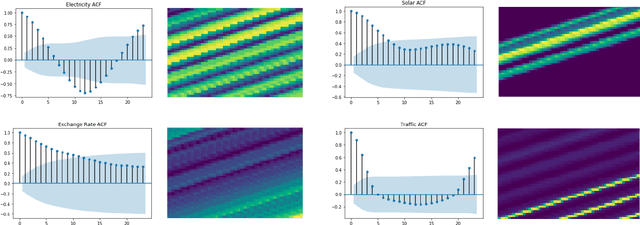

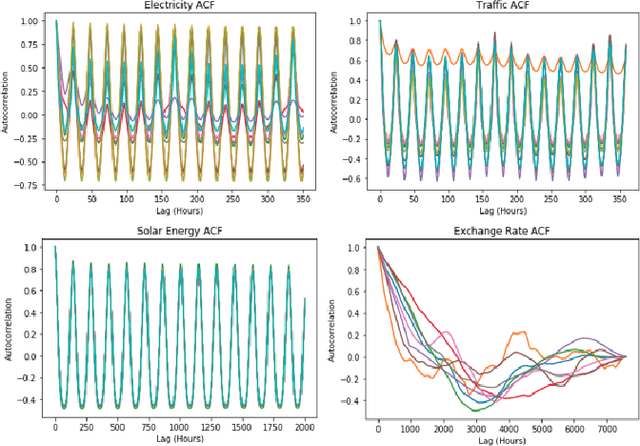
Multivariate time series prediction has applications in a wide variety of domains and is considered to be a very challenging task, especially when the variables have correlations and exhibit complex temporal patterns, such as seasonality and trend. Many existing methods suffer from strong statistical assumptions, numerical issues with high dimensionality, manual feature engineering efforts, and scalability. In this work, we present a novel deep learning architecture, known as Temporal Tensor Transformation Network, which transforms the original multivariate time series into a higher order of tensor through the proposed Temporal-Slicing Stack Transformation. This yields a new representation of the original multivariate time series, which enables the convolution kernel to extract complex and non-linear features as well as variable interactional signals from a relatively large temporal region. Experimental results show that Temporal Tensor Transformation Network outperforms several state-of-the-art methods on window-based predictions across various tasks. The proposed architecture also demonstrates robust prediction performance through an extensive sensitivity analysis.
StackInsights: Cognitive Learning for Hybrid Cloud Readiness
Dec 16, 2017
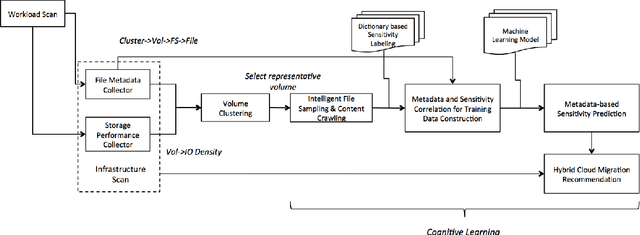
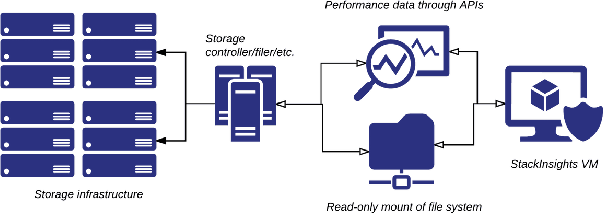
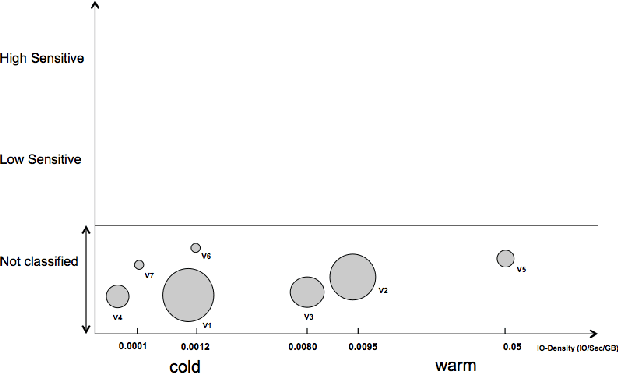
Hybrid cloud is an integrated cloud computing environment utilizing a mix of public cloud, private cloud, and on-premise traditional IT infrastructures. Workload awareness, defined as a detailed full range understanding of each individual workload, is essential in implementing the hybrid cloud. While it is critical to perform an accurate analysis to determine which workloads are appropriate for on-premise deployment versus which workloads can be migrated to a cloud off-premise, the assessment is mainly performed by rule or policy based approaches. In this paper, we introduce StackInsights, a novel cognitive system to automatically analyze and predict the cloud readiness of workloads for an enterprise. Our system harnesses the critical metrics across the entire stack: 1) infrastructure metrics, 2) data relevance metrics, and 3) application taxonomy, to identify workloads that have characteristics of a) low sensitivity with respect to business security, criticality and compliance, and b) low response time requirements and access patterns. Since the capture of the data relevance metrics involves an intrusive and in-depth scanning of the content of storage objects, a machine learning model is applied to perform the business relevance classification by learning from the meta level metrics harnessed across stack. In contrast to traditional methods, StackInsights significantly reduces the total time for hybrid cloud readiness assessment by orders of magnitude.