 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Question Answering with A Hybrid RAG Approach
Jan 19, 2026Retrieval-Augmented Generation (RAG) has emerged as a powerful technique for enhancing the quality of responses in Question-Answering (QA) tasks. However, existing approaches often struggle with retrieving contextually relevant information, leading to incomplete or suboptimal answers. In this paper, we introduce Structured-Semantic RAG (SSRAG), a hybrid architecture that enhances QA quality by integrating query augmentation, agentic routing, and a structured retrieval mechanism combining vector and graph based techniques with context unification. By refining retrieval processes and improving contextual grounding, our approach improves both answer accuracy and informativeness. We conduct extensive evaluations on three popular QA datasets, TruthfulQA, SQuAD and WikiQA, across five Large Language Models (LLMs), demonstrating that our proposed approach consistently improves response quality over standard RAG implementations.
Federated XGBoost on Sample-Wise Non-IID Data
Sep 03, 2022



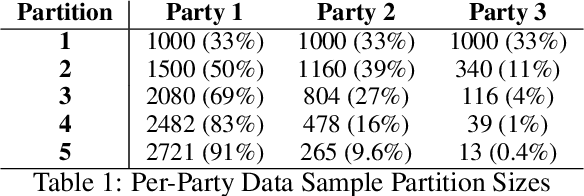
Federated Learning (FL) is a paradigm for jointly training machine learning algorithms in a decentralized manner which allows for parties to communicate with an aggregator to create and train a model, without exposing the underlying raw data distribution of the local parties involved in the training process. Most research in FL has been focused on Neural Network-based approaches, however Tree-Based methods, such as XGBoost, have been underexplored in Federated Learning due to the challenges in overcoming the iterative and additive characteristics of the algorithm. Decision tree-based models, in particular XGBoost, can handle non-IID data, which is significant for algorithms used in Federated Learning frameworks since the underlying characteristics of the data are decentralized and have risks of being non-IID by nature. In this paper, we focus on investigating the effects of how Federated XGBoost is impacted by non-IID distributions by performing experiments on various sample size-based data skew scenarios and how these models perform under various non-IID scenarios. We conduct a set of extensive experiments across multiple different datasets and different data skew partitions. Our experimental results demonstrate that despite the various partition ratios, the performance of the models stayed consistent and performed close to or equally well against models that were trained in a centralized manner.
SimPO: Simultaneous Prediction and Optimization
Mar 31, 2022

Many machine learning (ML) models are integrated within the context of a larger system as part of a key component for decision making processes. Concretely, predictive models are often employed in estimating the parameters for the input values that are utilized for optimization models as isolated processes. Traditionally, the predictive models are built first, then the model outputs are used to generate decision values separately. However, it is often the case that the prediction values that are trained independently of the optimization process produce sub-optimal solutions. In this paper, we propose a formulation for the Simultaneous Prediction and Optimization (SimPO) framework. This framework introduces the use of a joint weighted loss of a decision-driven predictive ML model and an optimization objective function, which is optimized end-to-end directly through gradient-based methods.
Predicting Loss Risks for B2B Tendering Processes
Sep 14, 2021



Sellers and executives who maintain a bidding pipeline of sales engagements with multiple clients for many opportunities significantly benefit from data-driven insight into the health of each of their bids. There are many predictive models that offer likelihood insights and win prediction modeling for these opportunities. Currently, these win prediction models are in the form of binary classification and only make a prediction for the likelihood of a win or loss. The binary formulation is unable to offer any insight as to why a particular deal might be predicted as a loss. This paper offers a multi-class classification model to predict win probability, with the three loss classes offering specific reasons as to why a loss is predicted, including no bid, customer did not pursue, and lost to competition. These classes offer an indicator of how that opportunity might be handled given the nature of the prediction. Besides offering baseline results on the multi-class classification, this paper also offers results on the model after class imbalance handling, with the results achieving a high accuracy of 85% and an average AUC score of 0.94.
Adaptive Histogram-Based Gradient Boosted Trees for Federated Learning
Dec 11, 2020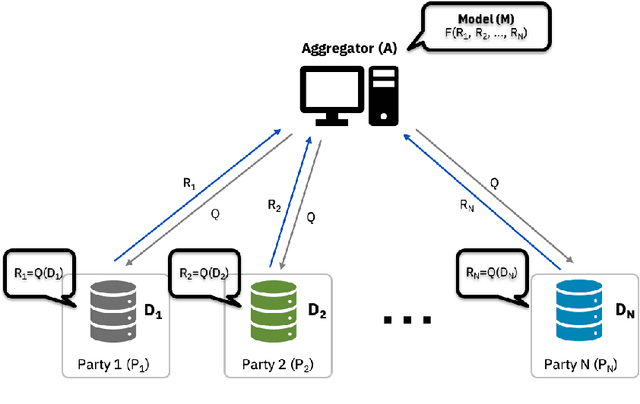


Federated Learning (FL) is an approach to collaboratively train a model across multiple parties without sharing data between parties or an aggregator. It is used both in the consumer domain to protect personal data as well as in enterprise settings, where dealing with data domicile regulation and the pragmatics of data silos are the main drivers. While gradient boosted tree implementations such as XGBoost have been very successful for many use cases, its federated learning adaptations tend to be very slow due to using cryptographic and privacy methods and have not experienced widespread use. We propose the Party-Adaptive XGBoost (PAX) for federated learning, a novel implementation of gradient boosting which utilizes a party adaptive histogram aggregation method, without the need for data encryption. It constructs a surrogate representation of the data distribution for finding splits of the decision tree. Our experimental results demonstrate strong model performance, especially on non-IID distributions, and significantly faster training run-time across different data sets than existing federated implementations. This approach makes the use of gradient boosted trees practical in enterprise federated learning.
Temporal Tensor Transformation Network for Multivariate Time Series Prediction
Jan 04, 2020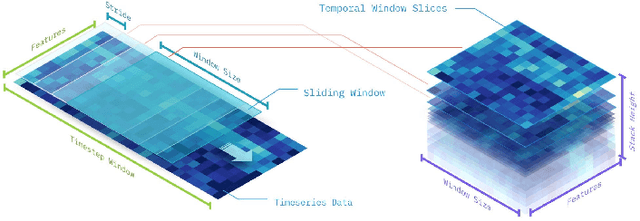
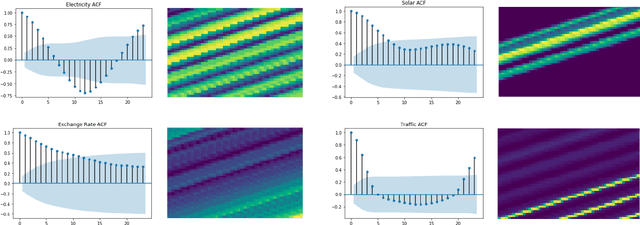

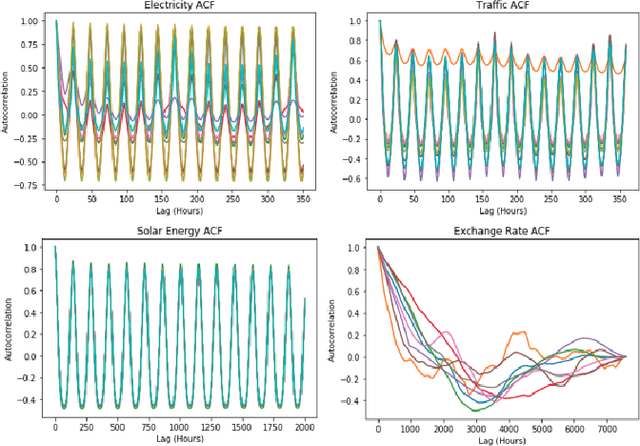
Multivariate time series prediction has applications in a wide variety of domains and is considered to be a very challenging task, especially when the variables have correlations and exhibit complex temporal patterns, such as seasonality and trend. Many existing methods suffer from strong statistical assumptions, numerical issues with high dimensionality, manual feature engineering efforts, and scalability. In this work, we present a novel deep learning architecture, known as Temporal Tensor Transformation Network, which transforms the original multivariate time series into a higher order of tensor through the proposed Temporal-Slicing Stack Transformation. This yields a new representation of the original multivariate time series, which enables the convolution kernel to extract complex and non-linear features as well as variable interactional signals from a relatively large temporal region. Experimental results show that Temporal Tensor Transformation Network outperforms several state-of-the-art methods on window-based predictions across various tasks. The proposed architecture also demonstrates robust prediction performance through an extensive sensitivity analysis.