 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Consistent Pruning: How to Efficiently Search for Sparse Networks?
Jan 26, 2025Iterative magnitude pruning methods (IMPs), proven to be successful in reducing the number of insignificant nodes in over-parameterized deep neural networks (DNNs), have been getting an enormous amount of attention with the rapid deployment of DNNs into cutting-edge technologies with computation and memory constraints. Despite IMPs popularity in pruning networks, a fundamental limitation of existing IMP algorithms is the significant training time required for each pruning iteration. Our paper introduces a novel \textit{stopping criterion} for IMPs that monitors information and gradient flows between networks layers and minimizes the training time. Information Consistent Pruning (\ourmethod{}) eliminates the need to retrain the network to its original performance during intermediate steps while maintaining overall performance at the end of the pruning process. Through our experiments, we demonstrate that our algorithm is more efficient than current IMPs across multiple dataset-DNN combinations. We also provide theoretical insights into the core idea of our algorithm alongside mathematical explanations of flow-based IMP. Our code is available at \url{https://github.com/Sekeh-Lab/InfCoP}.
Ghost-Connect Net: A Generalization-Enhanced Guidance For Sparse Deep Networks Under Distribution Shifts
Nov 14, 2024



Sparse deep neural networks (DNNs) excel in real-world applications like robotics and computer vision, by reducing computational demands that hinder usability. However, recent studies aim to boost DNN efficiency by trimming redundant neurons or filters based on task relevance, but neglect their adaptability to distribution shifts. We aim to enhance these existing techniques by introducing a companion network, Ghost Connect-Net (GC-Net), to monitor the connections in the original network with distribution generalization advantage. GC-Net's weights represent connectivity measurements between consecutive layers of the original network. After pruning GC-Net, the pruned locations are mapped back to the original network as pruned connections, allowing for the combination of magnitude and connectivity-based pruning methods. Experimental results using common DNN benchmarks, such as CIFAR-10, Fashion MNIST, and Tiny ImageNet show promising results for hybridizing the method, and using GC-Net guidance for later layers of a network and direct pruning on earlier layers. We provide theoretical foundations for GC-Net's approach to improving generalization under distribution shifts.
Robust Subgraph Learning by Monitoring Early Training Representations
Mar 14, 2024


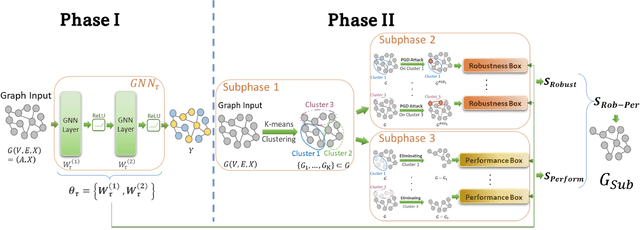
Graph neural networks (GNNs) have attracted significant attention for their outstanding performance in graph learning and node classification tasks. However, their vulnerability to adversarial attacks, particularly through susceptible nodes, poses a challenge in decision-making. The need for robust graph summarization is evident in adversarial challenges resulting from the propagation of attacks throughout the entire graph. In this paper, we address both performance and adversarial robustness in graph input by introducing the novel technique SHERD (Subgraph Learning Hale through Early Training Representation Distances). SHERD leverages information from layers of a partially trained graph convolutional network (GCN) to detect susceptible nodes during adversarial attacks using standard distance metrics. The method identifies "vulnerable (bad)" nodes and removes such nodes to form a robust subgraph while maintaining node classification performance. Through our experiments, we demonstrate the increased performance of SHERD in enhancing robustness by comparing the network's performance on original and subgraph inputs against various baselines alongside existing adversarial attacks. Our experiments across multiple datasets, including citation datasets such as Cora, Citeseer, and Pubmed, as well as microanatomical tissue structures of cell graphs in the placenta, highlight that SHERD not only achieves substantial improvement in robust performance but also outperforms several baselines in terms of node classification accuracy and computational complexity.
FogGuard: guarding YOLO against fog using perceptual loss
Mar 13, 2024



In this paper, we present a novel fog-aware object detection network called FogGuard, designed to address the challenges posed by foggy weather conditions. Autonomous driving systems heavily rely on accurate object detection algorithms, but adverse weather conditions can significantly impact the reliability of deep neural networks (DNNs). Existing approaches fall into two main categories, 1) image enhancement such as IA-YOLO 2) domain adaptation based approaches. Image enhancement based techniques attempt to generate fog-free image. However, retrieving a fogless image from a foggy image is a much harder problem than detecting objects in a foggy image. Domain-adaptation based approaches, on the other hand, do not make use of labelled datasets in the target domain. Both categories of approaches are attempting to solve a harder version of the problem. Our approach builds over fine-tuning on the Our framework is specifically designed to compensate for foggy conditions present in the scene, ensuring robust performance even. We adopt YOLOv3 as the baseline object detection algorithm and introduce a novel Teacher-Student Perceptual loss, to high accuracy object detection in foggy images. Through extensive evaluations on common datasets such as PASCAL VOC and RTTS, we demonstrate the improvement in performance achieved by our network. We demonstrate that FogGuard achieves 69.43\% mAP, as compared to 57.78\% for YOLOv3 on the RTTS dataset. Furthermore, we show that while our training method increases time complexity, it does not introduce any additional overhead during inference compared to the regular YOLO network.
Towards Explaining Deep Neural Network Compression Through a Probabilistic Latent Space
Feb 29, 2024



Despite the impressive performance of deep neural networks (DNNs), their computational complexity and storage space consumption have led to the concept of network compression. While DNN compression techniques such as pruning and low-rank decomposition have been extensively studied, there has been insufficient attention paid to their theoretical explanation. In this paper, we propose a novel theoretical framework that leverages a probabilistic latent space of DNN weights and explains the optimal network sparsity by using the information-theoretic divergence measures. We introduce new analogous projected patterns (AP2) and analogous-in-probability projected patterns (AP3) notions for DNNs and prove that there exists a relationship between AP3/AP2 property of layers in the network and its performance. Further, we provide a theoretical analysis that explains the training process of the compressed network. The theoretical results are empirically validated through experiments conducted on standard pre-trained benchmarks, including AlexNet, ResNet50, and VGG16, using CIFAR10 and CIFAR100 datasets. Through our experiments, we highlight the relationship of AP3 and AP2 properties with fine-tuning pruned DNNs and sparsity levels.
A Theoretical Perspective on Subnetwork Contributions to Adversarial Robustness
Jul 07, 2023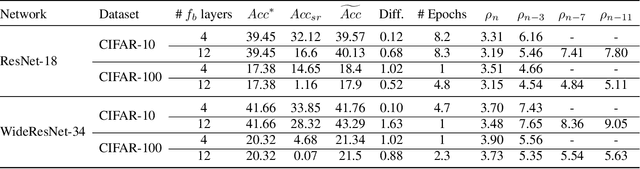
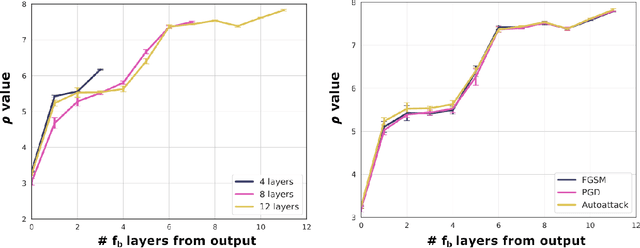
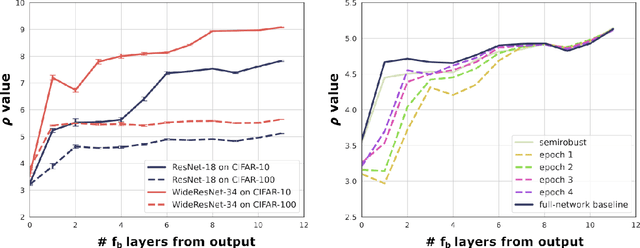
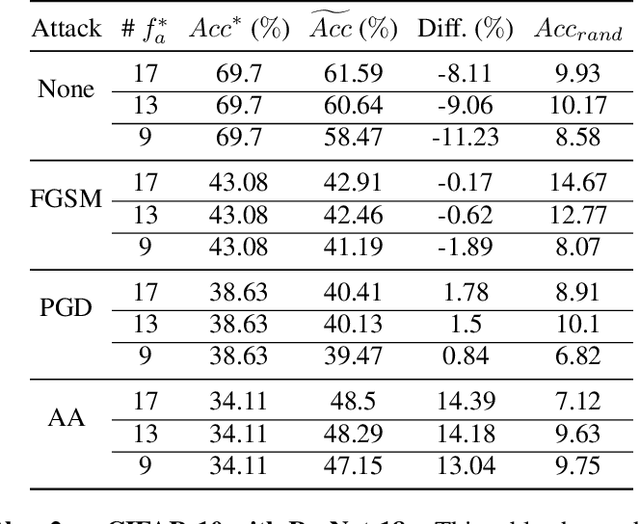
The robustness of deep neural networks (DNNs) against adversarial attacks has been studied extensively in hopes of both better understanding how deep learning models converge and in order to ensure the security of these models in safety-critical applications. Adversarial training is one approach to strengthening DNNs against adversarial attacks, and has been shown to offer a means for doing so at the cost of applying computationally expensive training methods to the entire model. To better understand these attacks and facilitate more efficient adversarial training, in this paper we develop a novel theoretical framework that investigates how the adversarial robustness of a subnetwork contributes to the robustness of the entire network. To do so we first introduce the concept of semirobustness, which is a measure of the adversarial robustness of a subnetwork. Building on this concept, we then provide a theoretical analysis to show that if a subnetwork is semirobust and there is a sufficient dependency between it and each subsequent layer in the network, then the remaining layers are also guaranteed to be robust. We validate these findings empirically across multiple DNN architectures, datasets, and adversarial attacks. Experiments show the ability of a robust subnetwork to promote full-network robustness, and investigate the layer-wise dependencies required for this full-network robustness to be achieved.
Promise and Limitations of Supervised Optimal Transport-Based Graph Summarization via Information Theoretic Measures
May 11, 2023Graph summarization is the problem of producing smaller graph representations of an input graph dataset, in such a way that the smaller compressed graphs capture relevant structural information for downstream tasks. There is a recent graph summarization method that formulates an optimal transport-based framework that allows prior information about node, edge, and attribute importance (never defined in that work) to be incorporated into the graph summarization process. However, very little is known about the statistical properties of this framework. To elucidate this question, we consider the problem of supervised graph summarization, wherein by using information theoretic measures we seek to preserve relevant information about a class label. To gain a theoretical perspective on the supervised summarization problem itself, we first formulate it in terms of maximizing the Shannon mutual information between the summarized graph and the class label. We show an NP-hardness of approximation result for this problem, thereby constraining what one should expect from proposed solutions. We then propose a summarization method that incorporates mutual information estimates between random variables associated with sample graphs and class labels into the optimal transport compression framework. We empirically show performance improvements over previous works in terms of classification accuracy and time on synthetic and certain real datasets. We also theoretically explore the limitations of the optimal transport approach for the supervised summarization problem and we show that it fails to satisfy a certain desirable information monotonicity property.
Improving Hyperspectral Adversarial Robustness using Ensemble Networks in the Presences of Multiple Attacks
Nov 01, 2022Semantic segmentation of hyperspectral images (HSI) has seen great strides in recent years by incorporating knowledge from deep learning RGB classification models. Similar to their classification counterparts, semantic segmentation models are vulnerable to adversarial examples and need adversarial training to counteract them. Traditional approaches to adversarial robustness focus on training or retraining a single network on attacked data, however, in the presence of multiple attacks these approaches decrease the performance compared to networks trained individually on each attack. To combat this issue we propose an Adversarial Discriminator Ensemble Network (ADE-Net) which focuses on attack type detection and adversarial robustness under a unified model to preserve per data-type weight optimally while robustifiying the overall network. In the proposed method, a discriminator network is used to separate data by attack type into their specific attack-expert ensemble network. Our approach allows for the presence of multiple attacks mixed together while also labeling attack types during testing. We experimentally show that ADE-Net outperforms the baseline, which is a single network adversarially trained under a mix of multiple attacks, for HSI Indian Pines, Kennedy Space, and Houston datasets.
Theoretical Understanding of the Information Flow on Continual Learning Performance
May 02, 2022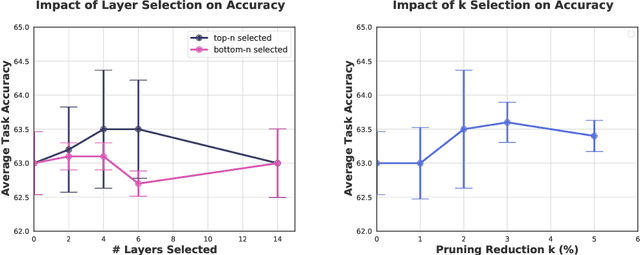
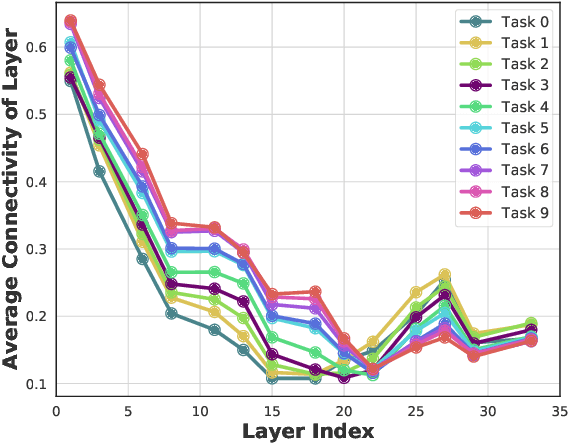
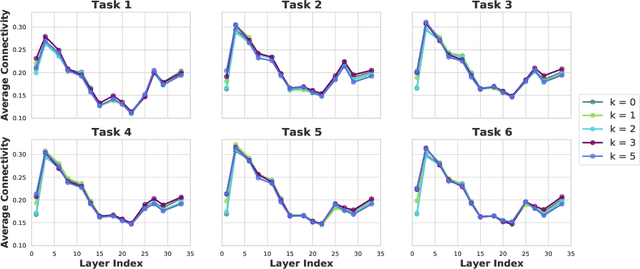
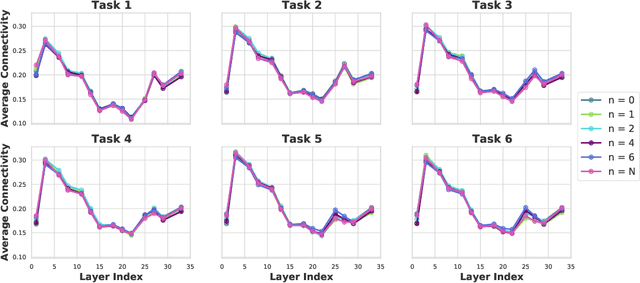
Continual learning (CL) is a setting in which an agent has to learn from an incoming stream of data sequentially. CL performance evaluates the model's ability to continually learn and solve new problems with incremental available information over time while retaining previous knowledge. Despite the numerous previous solutions to bypass the catastrophic forgetting (CF) of previously seen tasks during the learning process, most of them still suffer significant forgetting, expensive memory cost, or lack of theoretical understanding of neural networks' conduct while learning new tasks. While the issue that CL performance degrades under different training regimes has been extensively studied empirically, insufficient attention has been paid from a theoretical angle. In this paper, we establish a probabilistic framework to analyze information flow through layers in networks for task sequences and its impact on learning performance. Our objective is to optimize the information preservation between layers while learning new tasks to manage task-specific knowledge passing throughout the layers while maintaining model performance on previous tasks. In particular, we study CL performance's relationship with information flow in the network to answer the question "How can knowledge of information flow between layers be used to alleviate CF?". Our analysis provides novel insights of information adaptation within the layers during the incremental task learning process. Through our experiments, we provide empirical evidence and practically highlight the performance improvement across multiple tasks.
Q-TART: Quickly Training for Adversarial Robustness and in-Transferability
Apr 14, 2022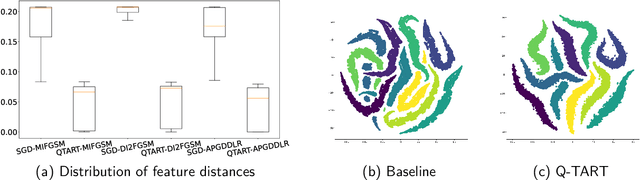
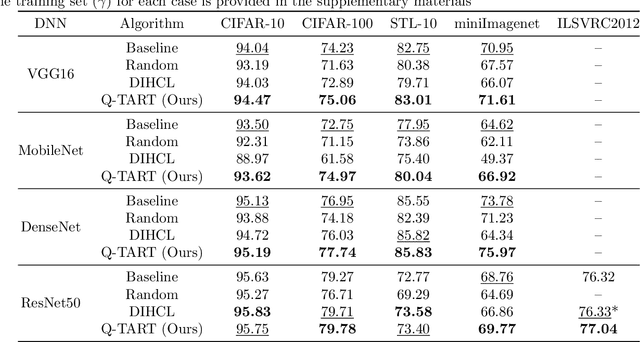
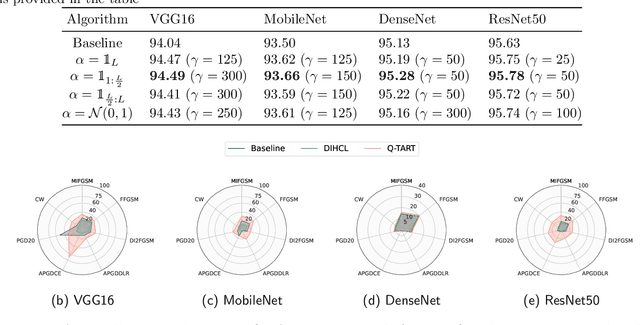
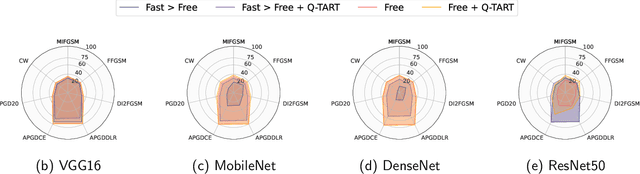
Raw deep neural network (DNN) performance is not enough; in real-world settings, computational load, training efficiency and adversarial security are just as or even more important. We propose to simultaneously tackle Performance, Efficiency, and Robustness, using our proposed algorithm Q-TART, Quickly Train for Adversarial Robustness and in-Transferability. Q-TART follows the intuition that samples highly susceptible to noise strongly affect the decision boundaries learned by DNNs, which in turn degrades their performance and adversarial susceptibility. By identifying and removing such samples, we demonstrate improved performance and adversarial robustness while using only a subset of the training data. Through our experiments we highlight Q-TART's high performance across multiple Dataset-DNN combinations, including ImageNet, and provide insights into the complementary behavior of Q-TART alongside existing adversarial training approaches to increase robustness by over 1.3% while using up to 17.9% less training time.