 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Subgraph Learning by Monitoring Early Training Representations
Mar 14, 2024


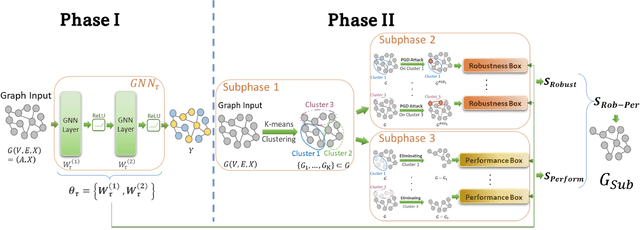
Graph neural networks (GNNs) have attracted significant attention for their outstanding performance in graph learning and node classification tasks. However, their vulnerability to adversarial attacks, particularly through susceptible nodes, poses a challenge in decision-making. The need for robust graph summarization is evident in adversarial challenges resulting from the propagation of attacks throughout the entire graph. In this paper, we address both performance and adversarial robustness in graph input by introducing the novel technique SHERD (Subgraph Learning Hale through Early Training Representation Distances). SHERD leverages information from layers of a partially trained graph convolutional network (GCN) to detect susceptible nodes during adversarial attacks using standard distance metrics. The method identifies "vulnerable (bad)" nodes and removes such nodes to form a robust subgraph while maintaining node classification performance. Through our experiments, we demonstrate the increased performance of SHERD in enhancing robustness by comparing the network's performance on original and subgraph inputs against various baselines alongside existing adversarial attacks. Our experiments across multiple datasets, including citation datasets such as Cora, Citeseer, and Pubmed, as well as microanatomical tissue structures of cell graphs in the placenta, highlight that SHERD not only achieves substantial improvement in robust performance but also outperforms several baselines in terms of node classification accuracy and computational complexity.
FogGuard: guarding YOLO against fog using perceptual loss
Mar 13, 2024



In this paper, we present a novel fog-aware object detection network called FogGuard, designed to address the challenges posed by foggy weather conditions. Autonomous driving systems heavily rely on accurate object detection algorithms, but adverse weather conditions can significantly impact the reliability of deep neural networks (DNNs). Existing approaches fall into two main categories, 1) image enhancement such as IA-YOLO 2) domain adaptation based approaches. Image enhancement based techniques attempt to generate fog-free image. However, retrieving a fogless image from a foggy image is a much harder problem than detecting objects in a foggy image. Domain-adaptation based approaches, on the other hand, do not make use of labelled datasets in the target domain. Both categories of approaches are attempting to solve a harder version of the problem. Our approach builds over fine-tuning on the Our framework is specifically designed to compensate for foggy conditions present in the scene, ensuring robust performance even. We adopt YOLOv3 as the baseline object detection algorithm and introduce a novel Teacher-Student Perceptual loss, to high accuracy object detection in foggy images. Through extensive evaluations on common datasets such as PASCAL VOC and RTTS, we demonstrate the improvement in performance achieved by our network. We demonstrate that FogGuard achieves 69.43\% mAP, as compared to 57.78\% for YOLOv3 on the RTTS dataset. Furthermore, we show that while our training method increases time complexity, it does not introduce any additional overhead during inference compared to the regular YOLO network.
Promise and Limitations of Supervised Optimal Transport-Based Graph Summarization via Information Theoretic Measures
May 11, 2023Graph summarization is the problem of producing smaller graph representations of an input graph dataset, in such a way that the smaller compressed graphs capture relevant structural information for downstream tasks. There is a recent graph summarization method that formulates an optimal transport-based framework that allows prior information about node, edge, and attribute importance (never defined in that work) to be incorporated into the graph summarization process. However, very little is known about the statistical properties of this framework. To elucidate this question, we consider the problem of supervised graph summarization, wherein by using information theoretic measures we seek to preserve relevant information about a class label. To gain a theoretical perspective on the supervised summarization problem itself, we first formulate it in terms of maximizing the Shannon mutual information between the summarized graph and the class label. We show an NP-hardness of approximation result for this problem, thereby constraining what one should expect from proposed solutions. We then propose a summarization method that incorporates mutual information estimates between random variables associated with sample graphs and class labels into the optimal transport compression framework. We empirically show performance improvements over previous works in terms of classification accuracy and time on synthetic and certain real datasets. We also theoretically explore the limitations of the optimal transport approach for the supervised summarization problem and we show that it fails to satisfy a certain desirable information monotonicity property.