 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Impact of Weight Sharing Decisions on Knowledge Transfer in Continual Learning
Nov 28, 2023Continual Learning (CL) has generated attention as a method of avoiding Catastrophic Forgetting (CF) in the sequential training of neural networks, improving network efficiency and adaptability to different tasks. Additionally, CL serves as an ideal setting for studying network behavior and Forward Knowledge Transfer (FKT) between tasks. Pruning methods for CL train subnetworks to handle the sequential tasks which allows us to take a structured approach to investigating FKT. Sharing prior subnetworks' weights leverages past knowledge for the current task through FKT. Understanding which weights to share is important as sharing all weights can yield sub-optimal accuracy. This paper investigates how different sharing decisions affect the FKT between tasks. Through this lens we demonstrate how task complexity and similarity influence the optimal weight sharing decisions, giving insights into the relationships between tasks and helping inform decision making in similar CL methods. We implement three sequential datasets designed to emphasize variation in task complexity and similarity, reporting results for both ResNet-18 and VGG-16. By sharing in accordance with the decisions supported by our findings, we show that we can improve task accuracy compared to other sharing decisions.
A Theoretical Perspective on Subnetwork Contributions to Adversarial Robustness
Jul 07, 2023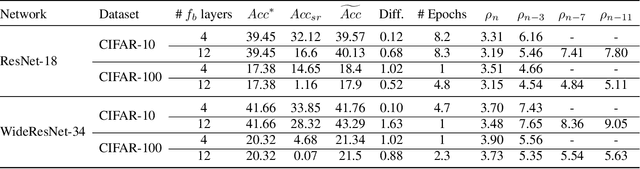
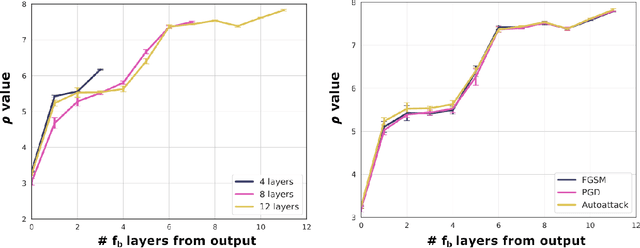
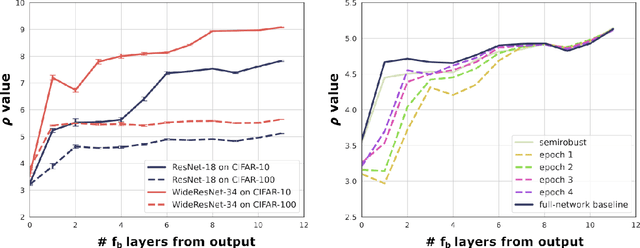
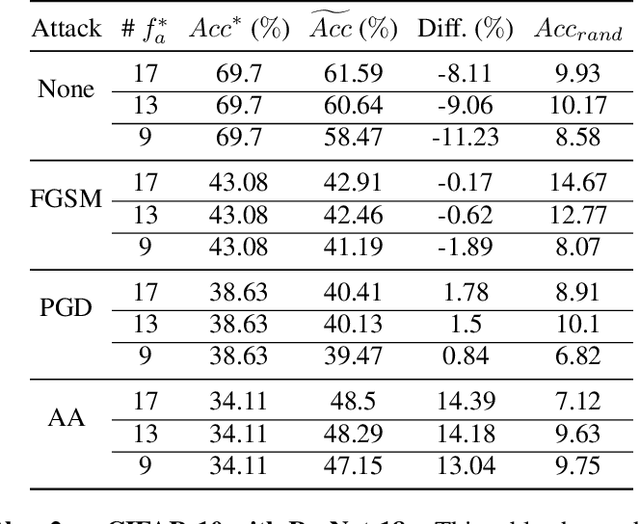
The robustness of deep neural networks (DNNs) against adversarial attacks has been studied extensively in hopes of both better understanding how deep learning models converge and in order to ensure the security of these models in safety-critical applications. Adversarial training is one approach to strengthening DNNs against adversarial attacks, and has been shown to offer a means for doing so at the cost of applying computationally expensive training methods to the entire model. To better understand these attacks and facilitate more efficient adversarial training, in this paper we develop a novel theoretical framework that investigates how the adversarial robustness of a subnetwork contributes to the robustness of the entire network. To do so we first introduce the concept of semirobustness, which is a measure of the adversarial robustness of a subnetwork. Building on this concept, we then provide a theoretical analysis to show that if a subnetwork is semirobust and there is a sufficient dependency between it and each subsequent layer in the network, then the remaining layers are also guaranteed to be robust. We validate these findings empirically across multiple DNN architectures, datasets, and adversarial attacks. Experiments show the ability of a robust subnetwork to promote full-network robustness, and investigate the layer-wise dependencies required for this full-network robustness to be achieved.
Theoretical Understanding of the Information Flow on Continual Learning Performance
May 02, 2022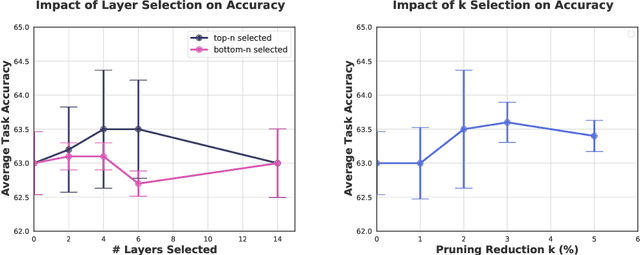
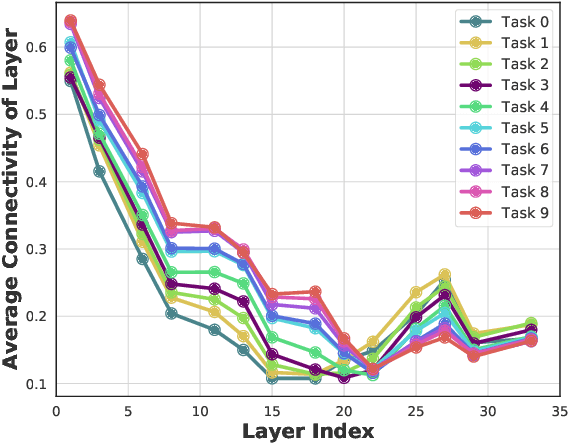
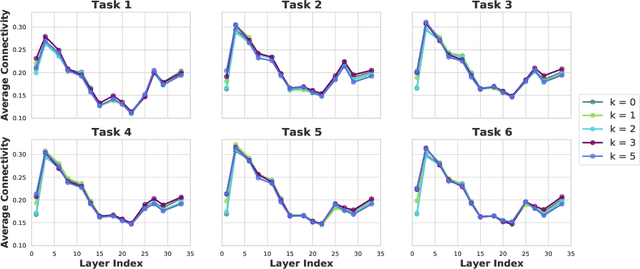
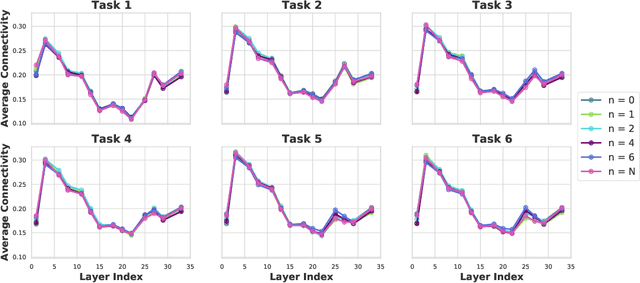
Continual learning (CL) is a setting in which an agent has to learn from an incoming stream of data sequentially. CL performance evaluates the model's ability to continually learn and solve new problems with incremental available information over time while retaining previous knowledge. Despite the numerous previous solutions to bypass the catastrophic forgetting (CF) of previously seen tasks during the learning process, most of them still suffer significant forgetting, expensive memory cost, or lack of theoretical understanding of neural networks' conduct while learning new tasks. While the issue that CL performance degrades under different training regimes has been extensively studied empirically, insufficient attention has been paid from a theoretical angle. In this paper, we establish a probabilistic framework to analyze information flow through layers in networks for task sequences and its impact on learning performance. Our objective is to optimize the information preservation between layers while learning new tasks to manage task-specific knowledge passing throughout the layers while maintaining model performance on previous tasks. In particular, we study CL performance's relationship with information flow in the network to answer the question "How can knowledge of information flow between layers be used to alleviate CF?". Our analysis provides novel insights of information adaptation within the layers during the incremental task learning process. Through our experiments, we provide empirical evidence and practically highlight the performance improvement across multiple tasks.