 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViP: Video Platform for PyTorch
Oct 07, 2019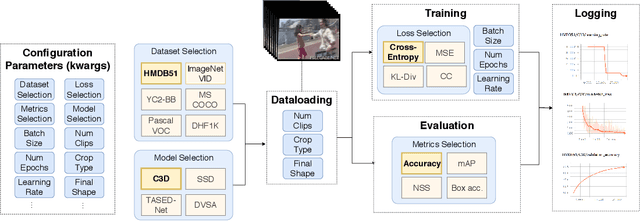

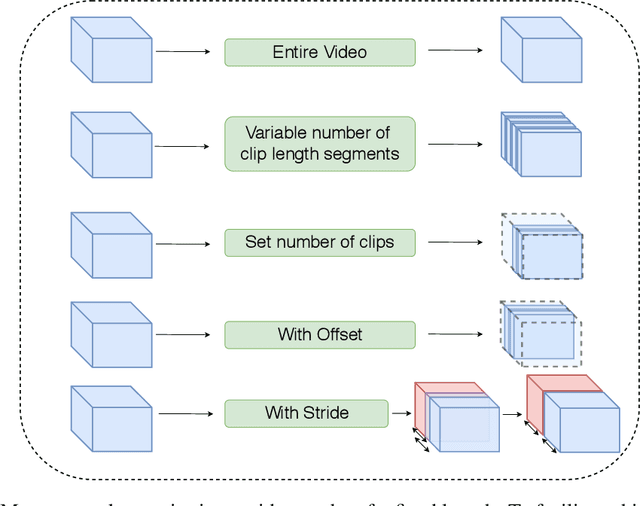
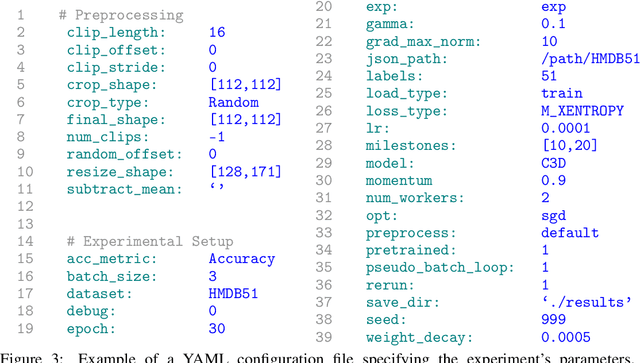
This work presents the Video Platform for PyTorch (ViP), a deep learning-based framework designed to handle and extend to any problem domain based on videos. ViP supports (1) a single unified interface applicable to all video problem domains, (2) quick prototyping of video models, (3) executing large-batch operations with reduced memory consumption, and (4) easy and reproducible experimental setups. ViP's core functionality is built with flexibility and modularity in mind to allow for smooth data flow between different parts of the platform and benchmarking against existing methods. In providing a software platform that supports multiple video-based problem domains, we allow for more cross-pollination of models, ideas and stronger generalization in the video understanding research community.
M-PACT: An Open Source Platform for Repeatable Activity Classification Research
Oct 05, 2018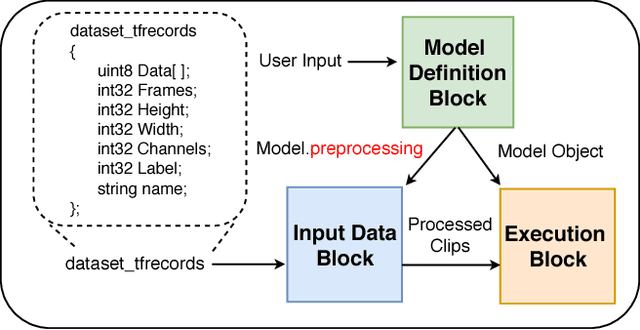
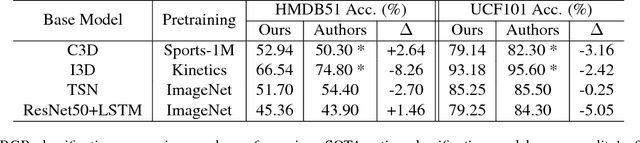

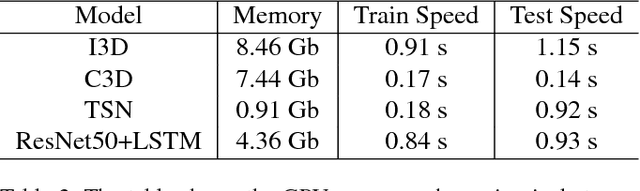
There are many hurdles that prevent the replication of existing work which hinders the development of new activity classification models. These hurdles include switching between multiple deep learning libraries and the development of boilerplate experimental pipelines. We present M-PACT to overcome existing issues by removing the need to develop boilerplate code which allows users to quickly prototype action classification models while leveraging existing state-of-the-art (SOTA) models available in the platform. M-PACT is the first to offer four SOTA activity classification models, I3D, C3D, ResNet50+LSTM, and TSN, under a single platform with reproducible competitive results. This platform allows for the generation of models and results over activity recognition datasets through the use of modular code, various preprocessing and neural network layers, and seamless data flow. In this paper, we present the system architecture, detail the functions of various modules, and describe the basic tools to develop a new model in M-PACT.
T-RECS: Training for Rate-Invariant Embeddings by Controlling Speed for Action Recognition
Mar 23, 2018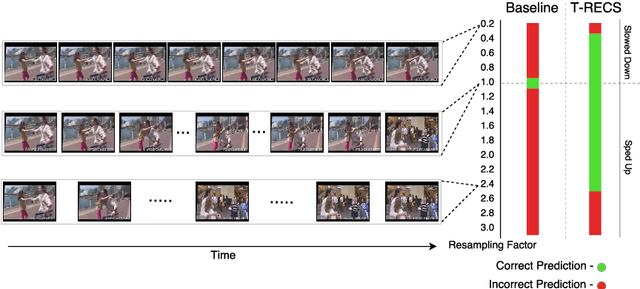
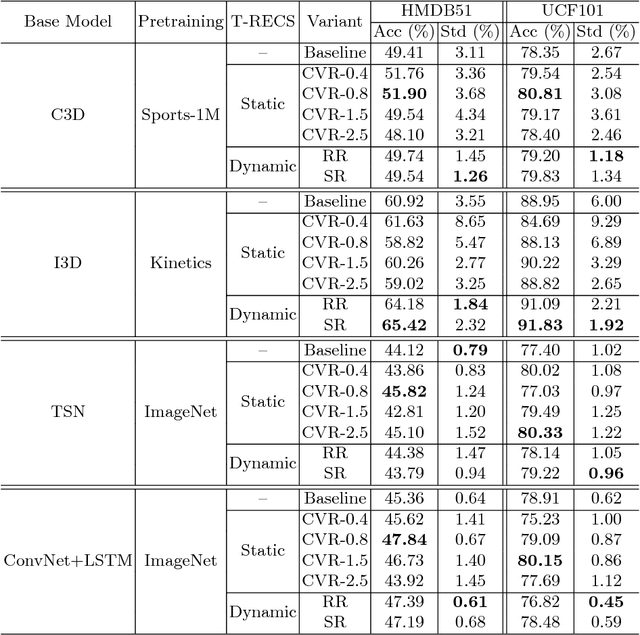
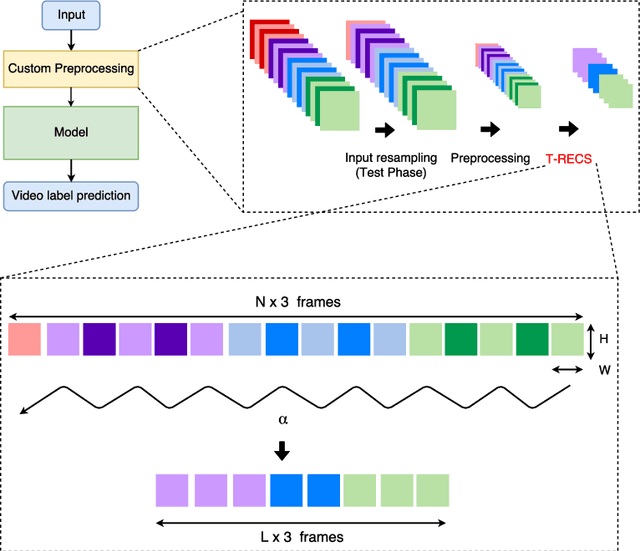
An action should remain identifiable when modifying its speed: consider the contrast between an expert chef and a novice chef each chopping an onion. Here, we expect the novice chef to have a relatively measured and slow approach to chopping when compared to the expert. In general, the speed at which actions are performed, whether slower or faster than average, should not dictate how they are recognized. We explore the erratic behavior caused by this phenomena on state-of-the-art deep network-based methods for action recognition in terms of maximum performance and stability in recognition accuracy across a range of input video speeds. By observing the trends in these metrics and summarizing them based on expected temporal behaviour w.r.t. variations in input video speeds, we find two distinct types of network architectures. In this paper, we propose a preprocessing method named T-RECS, as a way to extend deep-network-based methods for action recognition to explicitly account for speed variability in the data. We do so by adaptively resampling the inputs to a given model. T-RECS is agnostic to the specific deep-network model; we apply it to four state-of-the-art action recognition architectures, C3D, I3D, TSN, and ConvNet+LSTM. On HMDB51 and UCF101, T-RECS-based I3D models show a peak improvement of at least 2.9% in performance over the baseline while T-RECS-based C3D models achieve a maximum improvement in stability by 59% over the baseline, on the HMDB51 dataset.