 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Vision-and-Language Navigation
Oct 06, 2022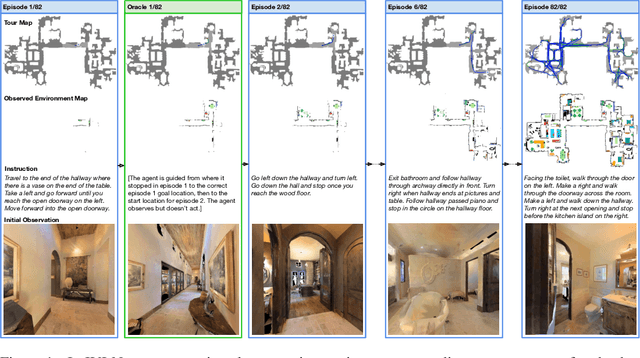
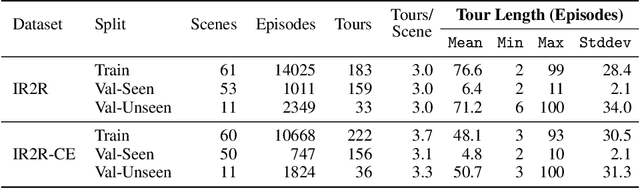
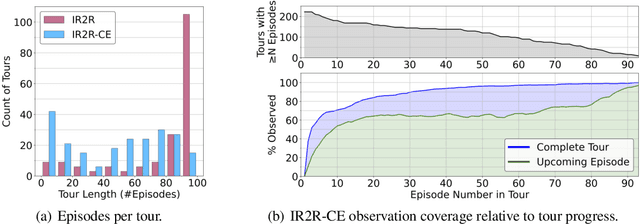

We present Iterative Vision-and-Language Navigation (IVLN), a paradigm for evaluating language-guided agents navigating in a persistent environment over time. Existing Vision-and-Language Navigation (VLN) benchmarks erase the agent's memory at the beginning of every episode, testing the ability to perform cold-start navigation with no prior information. However, deployed robots occupy the same environment for long periods of time. The IVLN paradigm addresses this disparity by training and evaluating VLN agents that maintain memory across tours of scenes that consist of up to 100 ordered instruction-following Room-to-Room (R2R) episodes, each defined by an individual language instruction and a target path. We present discrete and continuous Iterative Room-to-Room (IR2R) benchmarks comprising about 400 tours each in 80 indoor scenes. We find that extending the implicit memory of high-performing transformer VLN agents is not sufficient for IVLN, but agents that build maps can benefit from environment persistence, motivating a renewed focus on map-building agents in VLN.
The RobotSlang Benchmark: Dialog-guided Robot Localization and Navigation
Oct 23, 2020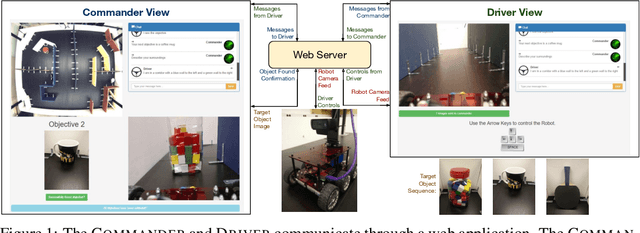
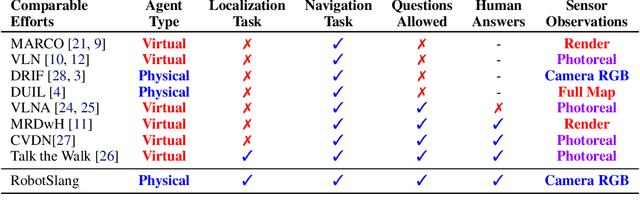

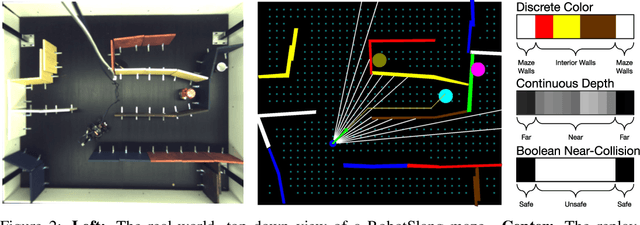
Autonomous robot systems for applications from search and rescue to assistive guidance should be able to engage in natural language dialog with people. To study such cooperative communication, we introduce Robot Simultaneous Localization and Mapping with Natural Language (RobotSlang), a benchmark of 169 natural language dialogs between a human Driver controlling a robot and a human Commander providing guidance towards navigation goals. In each trial, the pair first cooperates to localize the robot on a global map visible to the Commander, then the Driver follows Commander instructions to move the robot to a sequence of target objects. We introduce a Localization from Dialog History (LDH) and a Navigation from Dialog History (NDH) task where a learned agent is given dialog and visual observations from the robot platform as input and must localize in the global map or navigate towards the next target object, respectively. RobotSlang is comprised of nearly 5k utterances and over 1k minutes of robot camera and control streams. We present an initial model for the NDH task, and show that an agent trained in simulation can follow the RobotSlang dialog-based navigation instructions for controlling a physical robot platform. Code and data are available at https://umrobotslang.github.io/.
Geometric Online Adaptation: Graph-Based OSFS for Streaming Samples
Oct 02, 2019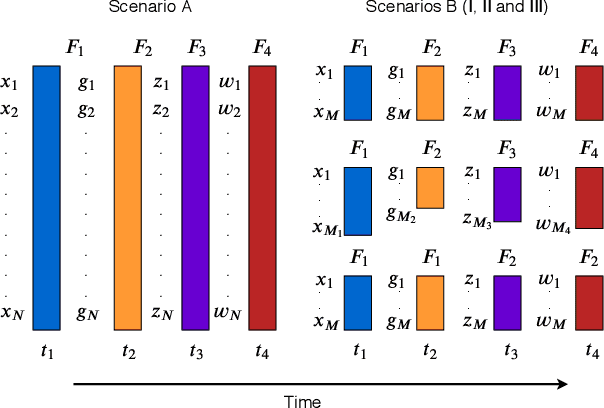
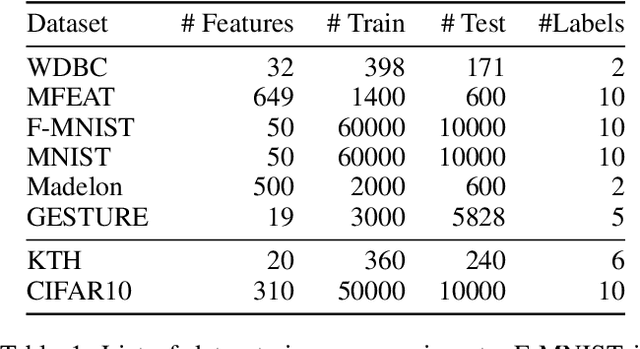
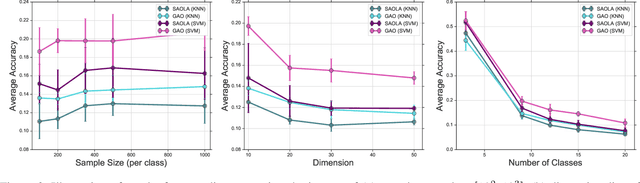
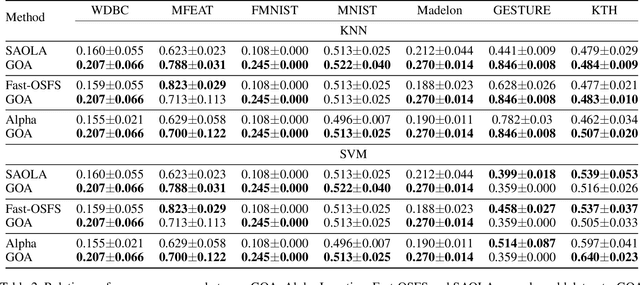
Feature selection seeks a curated subset of available features such that they contain sufficient discriminative information for a given learning task. Online streaming feature selection (OSFS) further extends this to the streaming scenario where the model gets only a single pass at features, one at a time. While this problem setting allows for training high performance models with low computational and storage requirements, this setting also makes the assumption that there is a fixed number of samples, which is often invalidated in many real-world problems. In this paper, we consider a new setting called Online Streaming Feature Selection with Streaming Samples (OSFS-SS) with a fixed class label space, where both the features and the samples are simultaneously streamed. We extend the state-of-the-art OSFS method to work in this setting. Furthermore, we introduce a novel algorithm, that has applications in both the OSFS and OSFS-SS settings, called Geometric Online Adaptation (GOA) which uses a graph-based class conditional geometric dependency (CGD) criterion to measure feature relevance and maintain a minimal feature subset with relatively high classification performance. We evaluate the proposed GOA algorithm on both simulation and real world datasets highlighting how in both the OSFS and OSFS-SS settings it achieves higher performance while maintaining smaller feature subsets than relevant baselines.
A Critical Investigation of Deep Reinforcement Learning for Navigation
Jan 04, 2019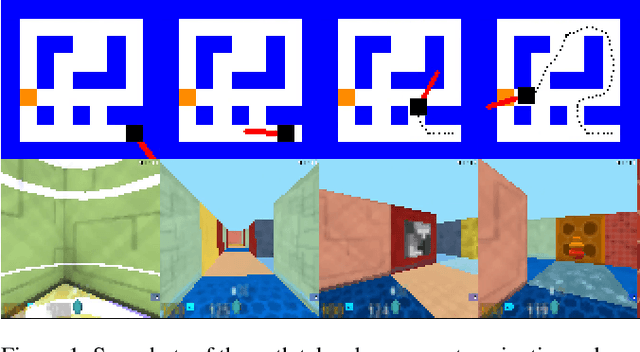


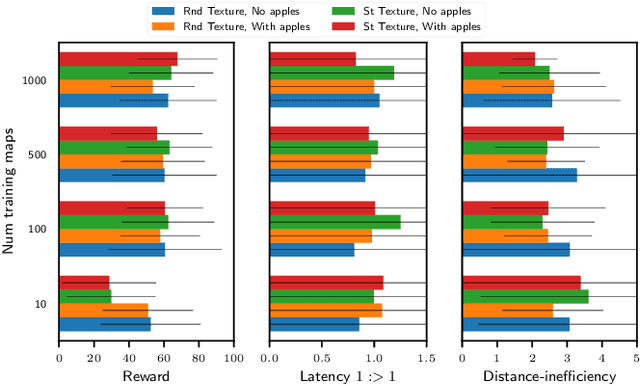
The navigation problem is classically approached in two steps: an exploration step, where map-information about the environment is gathered; and an exploitation step, where this information is used to navigate efficiently. Deep reinforcement learning (DRL) algorithms, alternatively, approach the problem of navigation in an end-to-end fashion. Inspired by the classical approach, we ask whether DRL algorithms are able to inherently explore, gather and exploit map-information over the course of navigation. We build upon Mirowski et al. [2017] work and introduce a systematic suite of experiments that vary three parameters: the agent's starting location, the agent's target location, and the maze structure. We choose evaluation metrics that explicitly measure the algorithm's ability to gather and exploit map-information. Our experiments show that when trained and tested on the same maps, the algorithm successfully gathers and exploits map-information. However, when trained and tested on different sets of maps, the algorithm fails to transfer the ability to gather and exploit map-information to unseen maps. Furthermore, we find that when the goal location is randomized and the map is kept static, the algorithm is able to gather and exploit map-information but the exploitation is far from optimal. We open-source our experimental suite in the hopes that it serves as a framework for the comparison of future algorithms and leads to the discovery of robust alternatives to classical navigation methods.
Floyd-Warshall Reinforcement Learning: Learning from Past Experiences to Reach New Goals
Oct 04, 2018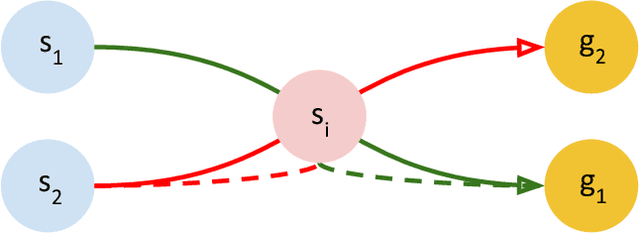
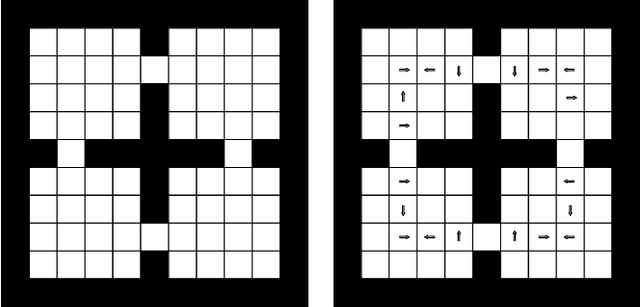
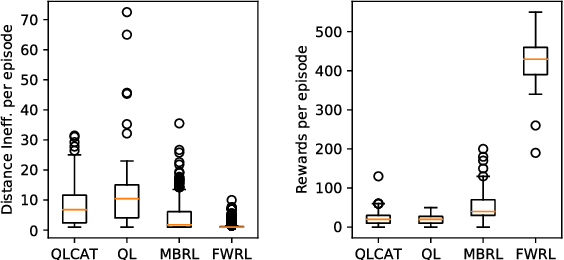
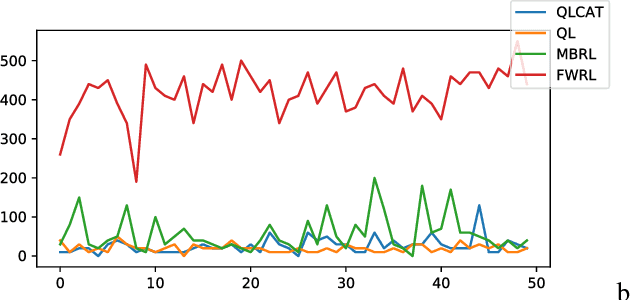
Consider mutli-goal tasks that involve static environments and dynamic goals. Examples of such tasks, such as goal-directed navigation and pick-and-place in robotics, abound. Two types of Reinforcement Learning (RL) algorithms are used for such tasks: model-free or model-based. Each of these approaches has limitations. Model-free RL struggles to transfer learned information when the goal location changes, but achieves high asymptotic accuracy in single goal tasks. Model-based RL can transfer learned information to new goal locations by retaining the explicitly learned state-dynamics, but is limited by the fact that small errors in modelling these dynamics accumulate over long-term planning. In this work, we improve upon the limitations of model-free RL in multi-goal domains. We do this by adapting the Floyd-Warshall algorithm for RL and call the adaptation Floyd-Warshall RL (FWRL). The proposed algorithm learns a goal-conditioned action-value function by constraining the value of the optimal path between any two states to be greater than or equal to the value of paths via intermediary states. Experimentally, we show that FWRL is more sample-efficient and learns higher reward strategies in multi-goal tasks as compared to Q-learning, model-based RL and other relevant baselines in a tabular domain.