 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloyd-Warshall Reinforcement Learning: Learning from Past Experiences to Reach New Goals
Paper and Code
Oct 04, 2018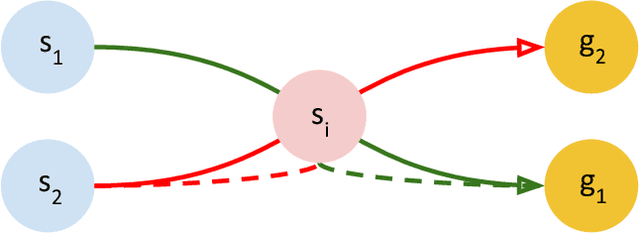
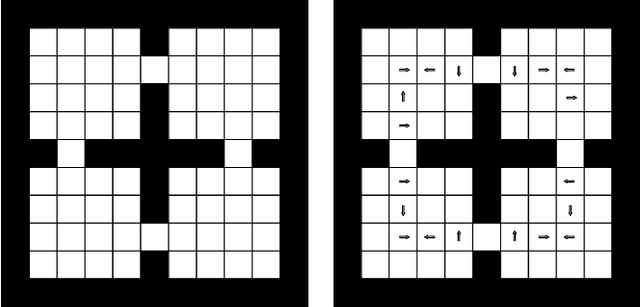
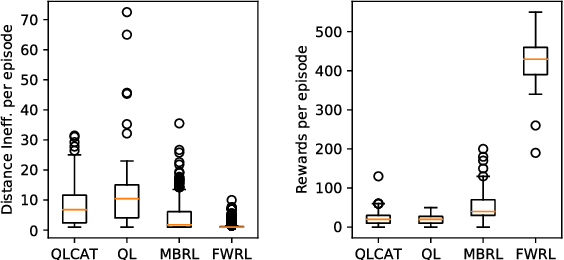
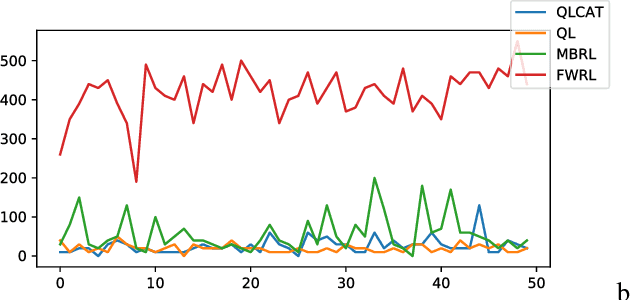
Consider mutli-goal tasks that involve static environments and dynamic goals. Examples of such tasks, such as goal-directed navigation and pick-and-place in robotics, abound. Two types of Reinforcement Learning (RL) algorithms are used for such tasks: model-free or model-based. Each of these approaches has limitations. Model-free RL struggles to transfer learned information when the goal location changes, but achieves high asymptotic accuracy in single goal tasks. Model-based RL can transfer learned information to new goal locations by retaining the explicitly learned state-dynamics, but is limited by the fact that small errors in modelling these dynamics accumulate over long-term planning. In this work, we improve upon the limitations of model-free RL in multi-goal domains. We do this by adapting the Floyd-Warshall algorithm for RL and call the adaptation Floyd-Warshall RL (FWRL). The proposed algorithm learns a goal-conditioned action-value function by constraining the value of the optimal path between any two states to be greater than or equal to the value of paths via intermediary states. Experimentally, we show that FWRL is more sample-efficient and learns higher reward strategies in multi-goal tasks as compared to Q-learning, model-based RL and other relevant baselines in a tabular domain.