 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Focused Few-Shot Object Detection for Robot Manipulation
Jan 28, 2022
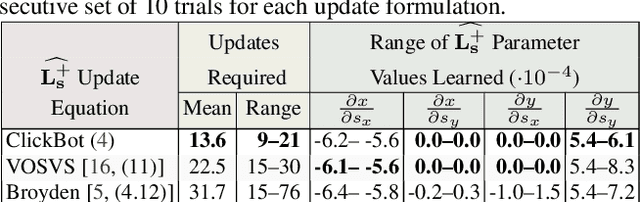
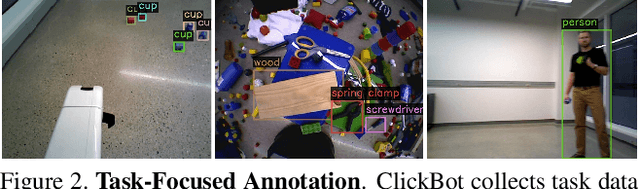
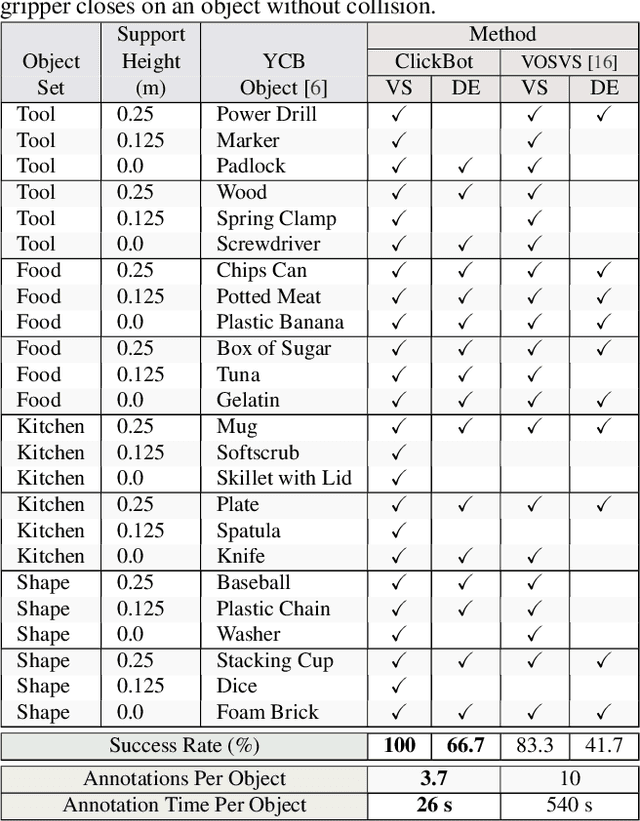
This paper addresses the problem of mobile robot manipulation of novel objects via detection. Our approach uses vision and control as complementary functions that learn from real-world tasks. We develop a manipulation method based solely on detection then introduce task-focused few-shot object detection to learn new objects and settings. The current paradigm for few-shot object detection uses existing annotated examples. In contrast, we extend this paradigm by using active data collection and annotation selection that improves performance for specific downstream tasks (e.g., depth estimation and grasping). In experiments for our interactive approach to few-shot learning, we train a robot to manipulate objects directly from detection (ClickBot). ClickBot learns visual servo control from a single click of annotation, grasps novel objects in clutter and other settings, and achieves state-of-the-art results on an existing visual servo control and depth estimation benchmark. Finally, we establish a task-focused few-shot object detection benchmark to support future research: https://github.com/griffbr/TFOD.
Self-Supervised Robot In-hand Object Learning
Apr 02, 2019

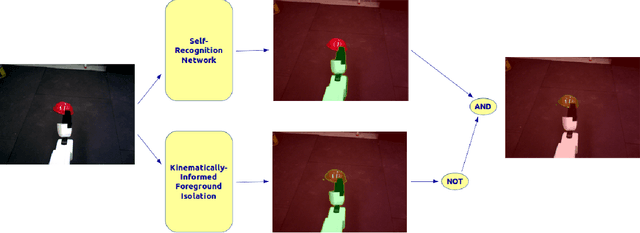

In order to complete tasks in a new environment, robots must be able to recognize unseen, unique objects. Fully supervised methods have made great strides on the object segmentation task, but require many examples of each object class and don't scale to unseen environments. In this work, we present a method that acquires pixelwise object labels for manipulable in-hand objects with no human supervision. Our two-step approach does a foreground-background segmentation informed by robot kinematics then uses a self-recognition network to segment the robot from the object in the foreground. We are able to achieve 49.4% mIoU performance on a difficult and varied assortment of items.
Video Object Segmentation-based Visual Servo Control and Object Depth Estimation on a Mobile Robot Platform
Mar 20, 2019


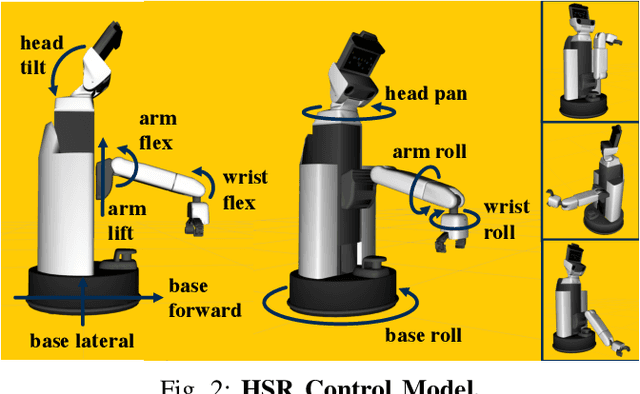
To be useful in everyday environments, robots must be able to identify and locate unstructured, real-world objects. In recent years, video object segmentation has made significant progress on densely separating such objects from background in real and challenging videos. This paper addresses the problem of identifying generic objects and locating them in 3D from a mobile robot platform equipped with an RGB camera. We achieve this by introducing a video object segmentation-based approach to visual servo control and active perception. We validate our approach in experiments using an HSR platform, which subsequently identifies, locates, and grasps objects from the YCB object dataset. We also develop a new Hadamard-Broyden update formulation, which enables HSR to automatically learn the relationship between actuators and visual features without any camera calibration. Using a variety of learned actuator-camera configurations, HSR also tracks people and other dynamic articulated objects.
Kinematically-Informed Interactive Perception: Robot-Generated 3D Models for Classification
Jan 17, 2019
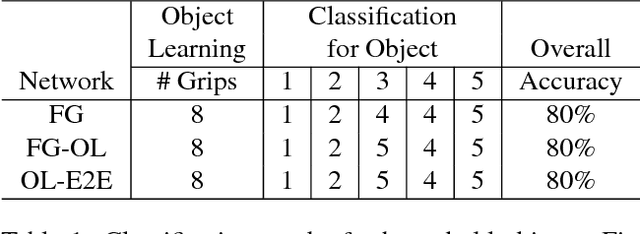

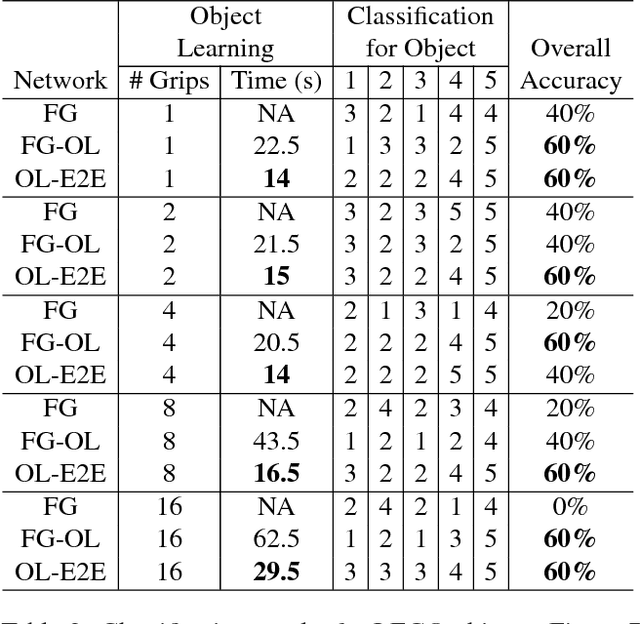
To be useful in everyday environments, robots must be able to observe and learn about objects. Recent datasets enable progress for classifying data into known object categories; however, it is unclear how to collect reliable object data when operating in cluttered, partially-observable environments. In this paper, we address the problem of building complete 3D models for real-world objects using a robot platform, which can remove objects from clutter for better classification. Furthermore, we are able to learn entirely new object categories as they are encountered, enabling the robot to classify previously unidentifiable objects during future interactions. We build models of grasped objects using simultaneous manipulation and observation, and we guide the processing of visual data using a kinematic description of the robot to combine observations from different view-points and remove background noise. To test our framework, we use a mobile manipulation robot equipped with an RGBD camera to build voxelized representations of unknown objects and then classify them into new categories. We then have the robot remove objects from clutter to manipulate, observe, and classify them in real-time.
A Critical Investigation of Deep Reinforcement Learning for Navigation
Jan 04, 2019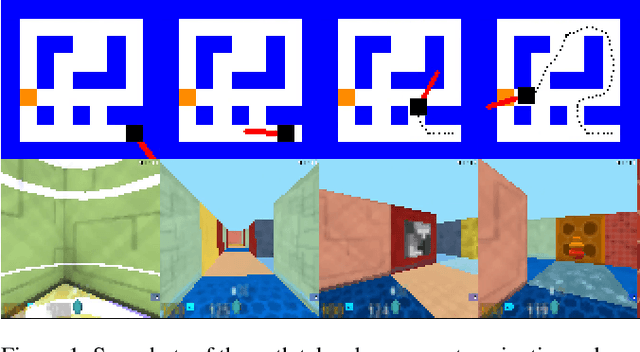


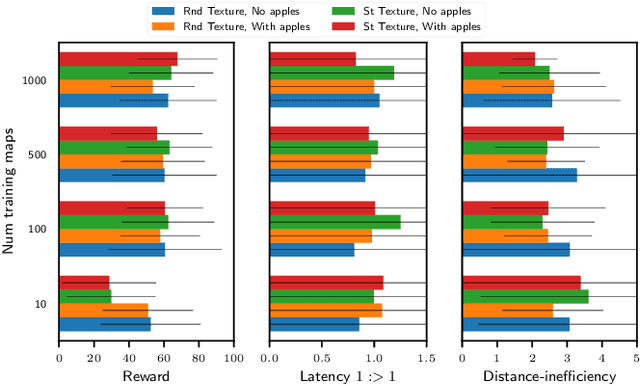
The navigation problem is classically approached in two steps: an exploration step, where map-information about the environment is gathered; and an exploitation step, where this information is used to navigate efficiently. Deep reinforcement learning (DRL) algorithms, alternatively, approach the problem of navigation in an end-to-end fashion. Inspired by the classical approach, we ask whether DRL algorithms are able to inherently explore, gather and exploit map-information over the course of navigation. We build upon Mirowski et al. [2017] work and introduce a systematic suite of experiments that vary three parameters: the agent's starting location, the agent's target location, and the maze structure. We choose evaluation metrics that explicitly measure the algorithm's ability to gather and exploit map-information. Our experiments show that when trained and tested on the same maps, the algorithm successfully gathers and exploits map-information. However, when trained and tested on different sets of maps, the algorithm fails to transfer the ability to gather and exploit map-information to unseen maps. Furthermore, we find that when the goal location is randomized and the map is kept static, the algorithm is able to gather and exploit map-information but the exploitation is far from optimal. We open-source our experimental suite in the hopes that it serves as a framework for the comparison of future algorithms and leads to the discovery of robust alternatives to classical navigation methods.
Learning Kinematic Descriptions using SPARE: Simulated and Physical ARticulated Extendable dataset
Mar 29, 2018
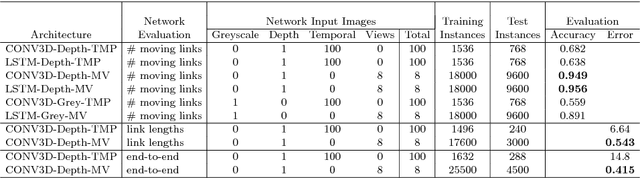
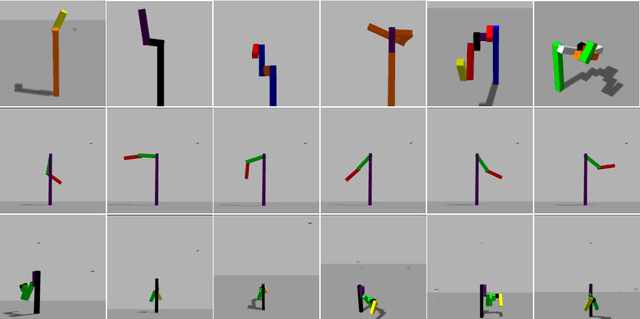
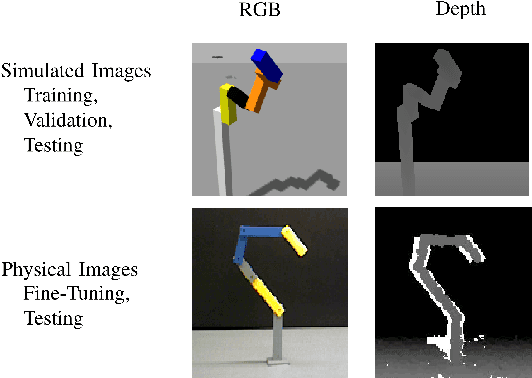
Next generation robots will need to understand intricate and articulated objects as they cooperate in human environments. To do so, these robots will need to move beyond their current abilities--- working with relatively simple objects in a task-indifferent manner--- toward more sophisticated abilities that dynamically estimate the properties of complex, articulated objects. To that end, we make two compelling contributions toward general articulated (physical) object understanding in this paper. First, we introduce a new dataset, SPARE: Simulated and Physical ARticulated Extendable dataset. SPARE is an extendable open-source dataset providing equivalent simulated and physical instances of articulated objects (kinematic chains), providing the greater research community with a training and evaluation tool for methods generating kinematic descriptions of articulated objects. To the best of our knowledge, this is the first joint visual and physical (3D-printable) dataset for the Vision community. Second, we present a deep neural network that can predit the number of links and the length of the links of an articulated object. These new ideas outperform classical approaches to understanding kinematic chains, such tracking-based methods, which fail in the case of occlusion and do not leverage multiple views when available.
Predicting Future Lane Changes of Other Highway Vehicles using RNN-based Deep Models
Mar 14, 2018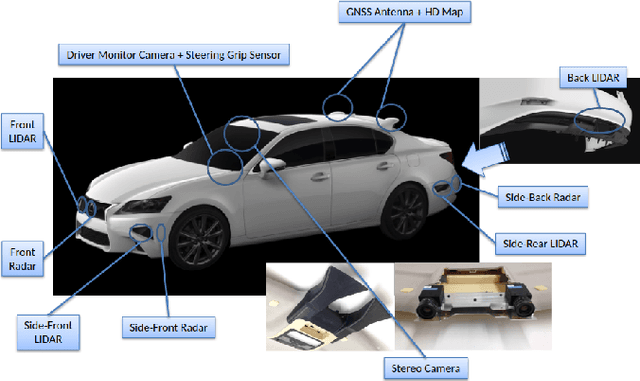

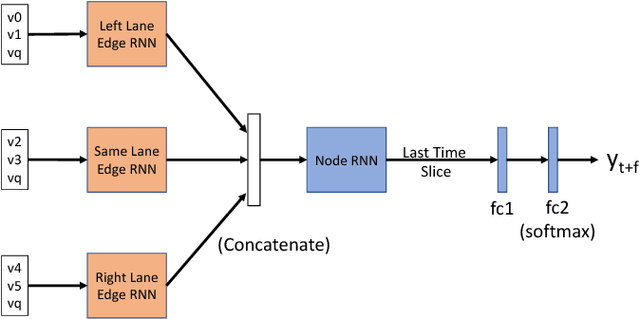
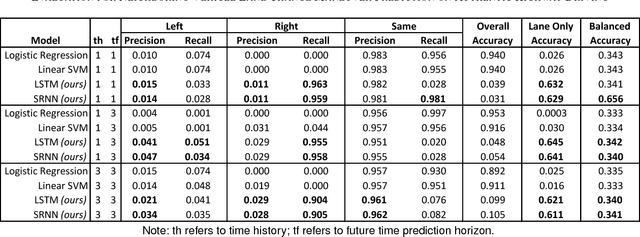
In the event of sensor failure, autonomous vehicles need to safely execute emergency maneuvers while avoiding other vehicles on the road. To accomplish this, the sensor-failed vehicle must predict the future semantic behaviors of other drivers, such as lane changes, as well as their future trajectories given a recent window of past sensor observations. We address the first issue of semantic behavior prediction in this paper, which is a precursor to trajectory prediction, by introducing a framework that leverages the power of recurrent neural networks (RNNs) and graphical models. Our goal is to predict the future categorical driving intent, for lane changes, of neighboring vehicles up to three seconds into the future given as little as a one-second window of past LIDAR, GPS, inertial, and map data. We collect real-world data containing over 20 hours of highway driving using an autonomous Toyota vehicle. We propose a composite RNN model by adopting the methodology of Structural Recurrent Neural Networks (RNNs) to learn factor functions and take advantage of both the high-level structure of graphical models and the sequence modeling power of RNNs, which we expect to afford more transparent modeling and activity than opaque, single RNN models. To demonstrate our approach, we validate our model using authentic interstate highway driving to predict the future lane change maneuvers of other vehicles neighboring our autonomous vehicle. We find that our composite Structural RNN outperforms baselines by as much as 12% in balanced accuracy metrics.