 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinematically-Informed Interactive Perception: Robot-Generated 3D Models for Classification
Jan 17, 2019
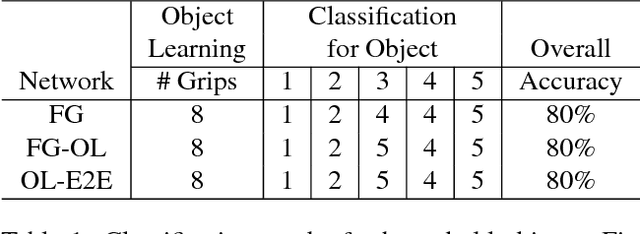

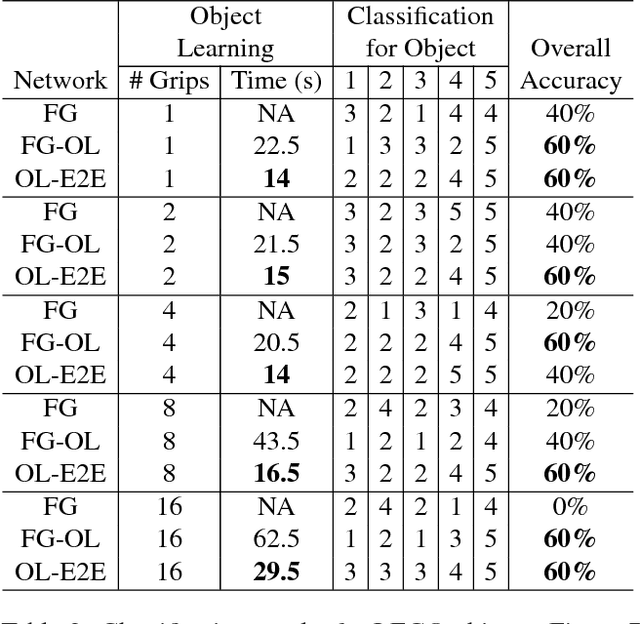
To be useful in everyday environments, robots must be able to observe and learn about objects. Recent datasets enable progress for classifying data into known object categories; however, it is unclear how to collect reliable object data when operating in cluttered, partially-observable environments. In this paper, we address the problem of building complete 3D models for real-world objects using a robot platform, which can remove objects from clutter for better classification. Furthermore, we are able to learn entirely new object categories as they are encountered, enabling the robot to classify previously unidentifiable objects during future interactions. We build models of grasped objects using simultaneous manipulation and observation, and we guide the processing of visual data using a kinematic description of the robot to combine observations from different view-points and remove background noise. To test our framework, we use a mobile manipulation robot equipped with an RGBD camera to build voxelized representations of unknown objects and then classify them into new categories. We then have the robot remove objects from clutter to manipulate, observe, and classify them in real-time.
Learning Kinematic Descriptions using SPARE: Simulated and Physical ARticulated Extendable dataset
Mar 29, 2018
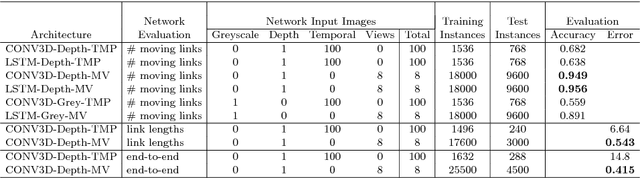
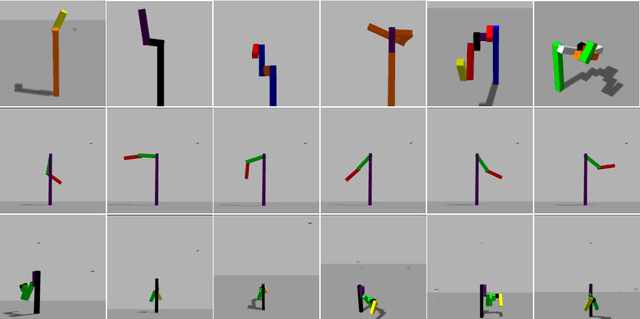
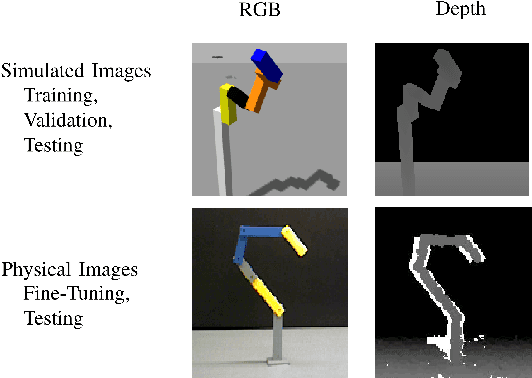
Next generation robots will need to understand intricate and articulated objects as they cooperate in human environments. To do so, these robots will need to move beyond their current abilities--- working with relatively simple objects in a task-indifferent manner--- toward more sophisticated abilities that dynamically estimate the properties of complex, articulated objects. To that end, we make two compelling contributions toward general articulated (physical) object understanding in this paper. First, we introduce a new dataset, SPARE: Simulated and Physical ARticulated Extendable dataset. SPARE is an extendable open-source dataset providing equivalent simulated and physical instances of articulated objects (kinematic chains), providing the greater research community with a training and evaluation tool for methods generating kinematic descriptions of articulated objects. To the best of our knowledge, this is the first joint visual and physical (3D-printable) dataset for the Vision community. Second, we present a deep neural network that can predit the number of links and the length of the links of an articulated object. These new ideas outperform classical approaches to understanding kinematic chains, such tracking-based methods, which fail in the case of occlusion and do not leverage multiple views when available.