 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-View Exocentric to Egocentric Video Synthesis
Paper and Code
Jul 07, 2021

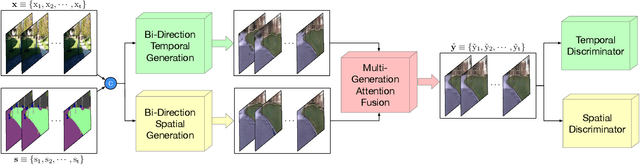

Cross-view video synthesis task seeks to generate video sequences of one view from another dramatically different view. In this paper, we investigate the exocentric (third-person) view to egocentric (first-person) view video generation task. This is challenging because egocentric view sometimes is remarkably different from the exocentric view. Thus, transforming the appearances across the two different views is a non-trivial task. Particularly, we propose a novel Bi-directional Spatial Temporal Attention Fusion Generative Adversarial Network (STA-GAN) to learn both spatial and temporal information to generate egocentric video sequences from the exocentric view. The proposed STA-GAN consists of three parts: temporal branch, spatial branch, and attention fusion. First, the temporal and spatial branches generate a sequence of fake frames and their corresponding features. The fake frames are generated in both downstream and upstream directions for both temporal and spatial branches. Next, the generated four different fake frames and their corresponding features (spatial and temporal branches in two directions) are fed into a novel multi-generation attention fusion module to produce the final video sequence. Meanwhile, we also propose a novel temporal and spatial dual-discriminator for more robust network optimization. Extensive experiments on the Side2Ego and Top2Ego datasets show that the proposed STA-GAN significantly outperforms the existing methods.