 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBBSEA: An Exploration of Brain-Body Synchronization for Embodied Agents
Feb 13, 2024



Embodied agents capable of complex physical skills can improve productivity, elevate life quality, and reshape human-machine collaboration. We aim at autonomous training of embodied agents for various tasks involving mainly large foundation models. It is believed that these models could act as a brain for embodied agents; however, existing methods heavily rely on humans for task proposal and scene customization, limiting the learning autonomy, training efficiency, and generalization of the learned policies. In contrast, we introduce a brain-body synchronization ({\it BBSEA}) scheme to promote embodied learning in unknown environments without human involvement. The proposed combines the wisdom of foundation models (``brain'') with the physical capabilities of embodied agents (``body''). Specifically, it leverages the ``brain'' to propose learnable physical tasks and success metrics, enabling the ``body'' to automatically acquire various skills by continuously interacting with the scene. We carry out an exploration of the proposed autonomous learning scheme in a table-top setting, and we demonstrate that the proposed synchronization can generate diverse tasks and develop multi-task policies with promising adaptability to new tasks and configurations. We will release our data, code, and trained models to facilitate future studies in building autonomously learning agents with large foundation models in more complex scenarios. More visualizations are available at \href{https://bbsea-embodied-ai.github.io}{https://bbsea-embodied-ai.github.io}
Text2Reward: Automated Dense Reward Function Generation for Reinforcement Learning
Sep 21, 2023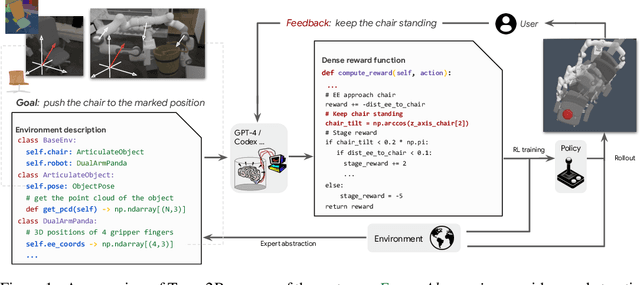
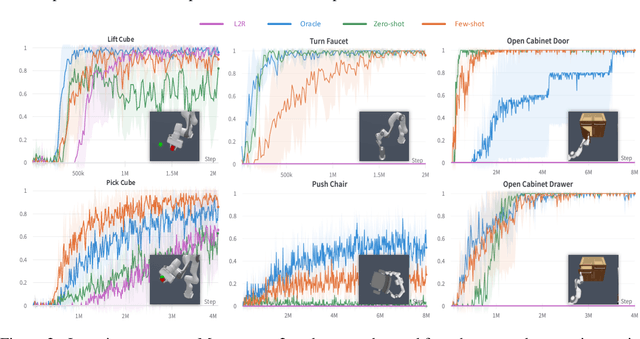
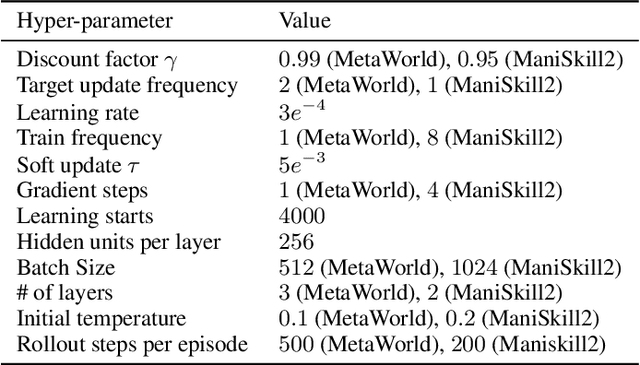
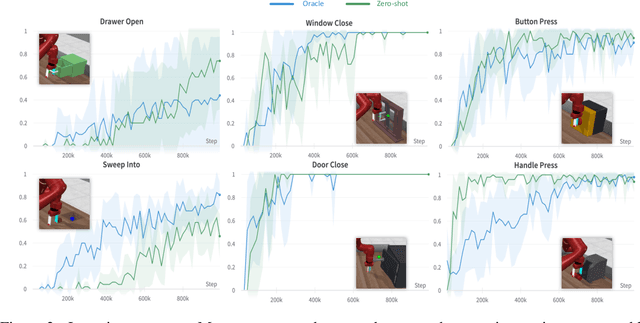
Designing reward functions is a longstanding challenge in reinforcement learning (RL); it requires specialized knowledge or domain data, leading to high costs for development. To address this, we introduce Text2Reward, a data-free framework that automates the generation of dense reward functions based on large language models (LLMs). Given a goal described in natural language, Text2Reward generates dense reward functions as an executable program grounded in a compact representation of the environment. Unlike inverse RL and recent work that uses LLMs to write sparse reward codes, Text2Reward produces interpretable, free-form dense reward codes that cover a wide range of tasks, utilize existing packages, and allow iterative refinement with human feedback. We evaluate Text2Reward on two robotic manipulation benchmarks (ManiSkill2, MetaWorld) and two locomotion environments of MuJoCo. On 13 of the 17 manipulation tasks, policies trained with generated reward codes achieve similar or better task success rates and convergence speed than expert-written reward codes. For locomotion tasks, our method learns six novel locomotion behaviors with a success rate exceeding 94%. Furthermore, we show that the policies trained in the simulator with our method can be deployed in the real world. Finally, Text2Reward further improves the policies by refining their reward functions with human feedback. Video results are available at https://text-to-reward.github.io
Grounding Object Relations in Language-Conditioned Robotic Manipulation with Semantic-Spatial Reasoning
Mar 31, 2023


Grounded understanding of natural language in physical scenes can greatly benefit robots that follow human instructions. In object manipulation scenarios, existing end-to-end models are proficient at understanding semantic concepts, but typically cannot handle complex instructions involving spatial relations among multiple objects. which require both reasoning object-level spatial relations and learning precise pixel-level manipulation affordances. We take an initial step to this challenge with a decoupled two-stage solution. In the first stage, we propose an object-centric semantic-spatial reasoner to select which objects are relevant for the language instructed task. The segmentation of selected objects are then fused as additional input to the affordance learning stage. Simply incorporating the inductive bias of relevant objects to a vision-language affordance learning agent can effectively boost its performance in a custom testbed designed for object manipulation with spatial-related language instructions.
Learning Robust Agents for Visual Navigation in Dynamic Environments: The Winning Entry of iGibson Challenge 2021
Sep 22, 2021
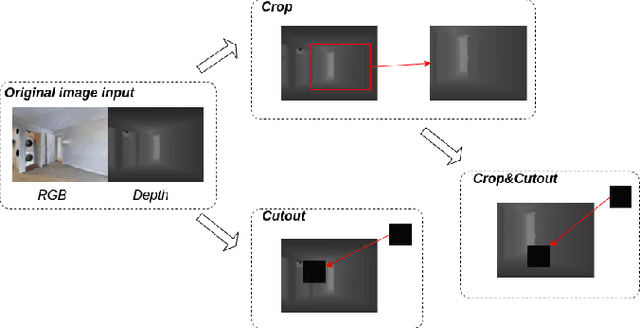
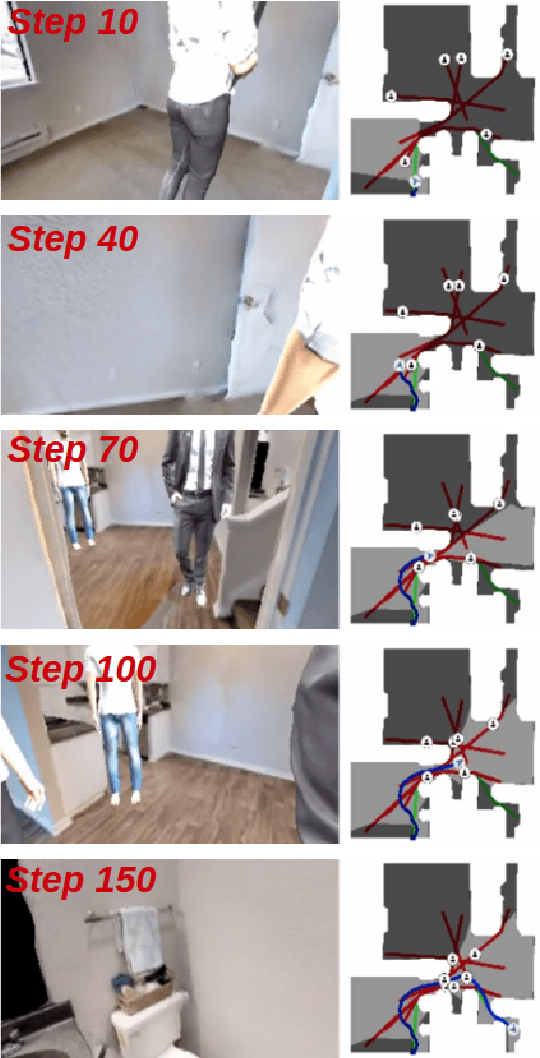
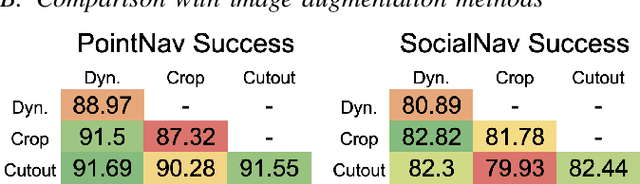
This paper presents an approach for improving navigation in dynamic and interactive environments, which won the 1st place in the iGibson Interactive Navigation Challenge 2021. While the last few years have produced impressive progress on PointGoal Navigation in static environments, relatively little effort has been made on more realistic dynamic environments. The iGibson Challenge proposed two new navigation tasks, Interactive Navigation and Social Navigation, which add displaceable obstacles and moving pedestrians into the simulator environment. Our approach to study these problems uses two key ideas. First, we employ large-scale reinforcement learning by leveraging the Habitat simulator, which supports high performance parallel computing for both simulation and synchronized learning. Second, we employ a new data augmentation technique that adds more dynamic objects into the environment, which can also be combined with traditional image-based augmentation techniques to boost the performance further. Lastly, we achieve sim-to-sim transfer from Habitat to the iGibson simulator, and demonstrate that our proposed methods allow us to train robust agents in dynamic environments with interactive objects or moving humans. Video link: https://www.youtube.com/watch?v=HxUX2HeOSE4
Causal Discovery of Flight Service Process Based on Event Sequence
Apr 28, 2021



The development of the civil aviation industry has continuously increased the requirements for the efficiency of airport ground support services. In the existing ground support research, there has not yet been a process model that directly obtains support from the ground support log to study the causal relationship between service nodes and flight delays. Most ground support studies mainly use machine learning methods to predict flight delays, and the flight support model they are based on is an ideal model. The study did not conduct an in-depth study of the causal mechanism behind the ground support link and did not reveal the true cause of flight delays. Therefore, there is a certain deviation in the prediction of flight delays by machine learning, and there is a certain deviation between the ideal model based on the research and the actual service process. Therefore, it is of practical significance to obtain the process model from the guarantee log and analyze its causality. However, the existing process causal factor discovery methods only do certain research when the assumption of causal sufficiency is established and does not consider the existence of latent variables. Therefore, this article proposes a framework to realize the discovery of process causal factors without assuming causal sufficiency. The optimized fuzzy mining process model is used as the service benchmark model, and the local causal discovery algorithm is used to discover the causal factors. Under this framework, this paper proposes a new Markov blanket discovery algorithm that does not assume causal sufficiency to discover causal factors and uses benchmark data sets for testing. Finally, the actual flight service data is used.
A Generalized Robotic Handwriting Learning System based on Dynamic Movement Primitives (DMPs)
Dec 07, 2020



Learning from demonstration (LfD) is a powerful learning method to enable a robot to infer how to perform a task given one or more human demonstrations of the desired task. By learning from end-user demonstration rather than requiring that a domain expert manually programming each skill, robots can more readily be applied to a wider range of real-world applications. Writing robots, as one application of LfD, has become a challenging research topic due to the complexity of human handwriting trajectories. In this paper, we introduce a generalized handwriting-learning system for a physical robot to learn from examples of humans' handwriting to draw alphanumeric characters. Our robotic system is able to rewrite letters imitating the way human demonstrators write and create new letters in a similar writing style. For this system, we develop an augmented dynamic movement primitive (DMP) algorithm, DMP*, which strengthens the robustness and generalization ability of our robotic system.
A Few Shot Adaptation of Visual Navigation Skills to New Observations using Meta-Learning
Nov 06, 2020
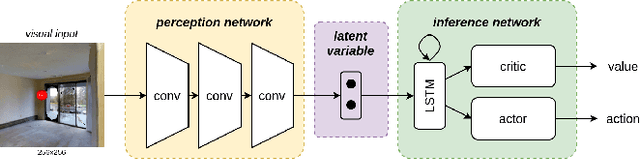
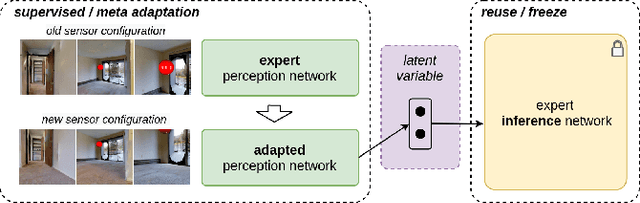
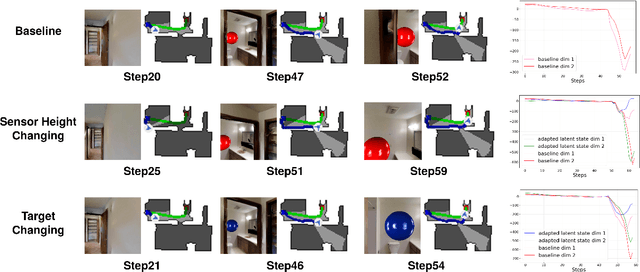
Target-driven visual navigation is a challenging problem that requires a robot to find the goal using only visual inputs. Many researchers have demonstrated promising results using deep reinforcement learning (deep RL) on various robotic platforms, but typical end-to-end learning is known for its poor extrapolation capability to new scenarios. Therefore, learning a navigation policy for a new robot with a new sensor configuration or a new target still remains a challenging problem. In this paper, we introduce a learning algorithm that enables rapid adaptation to new sensor configurations or target objects with a few shots. We design a policy architecture with latent features between perception and inference networks and quickly adapt the perception network via meta-learning while freezing the inference network. Our experiments show that our algorithm adapts the learned navigation policy with only three shots for unseen situations with different sensor configurations or different target colors. We also analyze the proposed algorithm by investigating various hyperparameters.