 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeVOS: Flow-Guided Deformable Transformer for Video Object Segmentation
May 11, 2024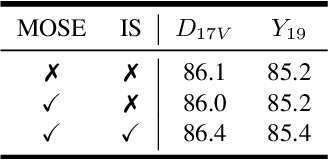
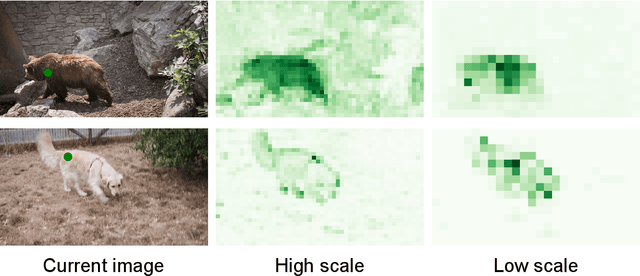
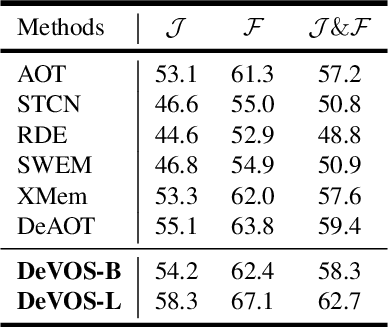

The recent works on Video Object Segmentation achieved remarkable results by matching dense semantic and instance-level features between the current and previous frames for long-time propagation. Nevertheless, global feature matching ignores scene motion context, failing to satisfy temporal consistency. Even though some methods introduce local matching branch to achieve smooth propagation, they fail to model complex appearance changes due to the constraints of the local window. In this paper, we present DeVOS (Deformable VOS), an architecture for Video Object Segmentation that combines memory-based matching with motion-guided propagation resulting in stable long-term modeling and strong temporal consistency. For short-term local propagation, we propose a novel attention mechanism ADVA (Adaptive Deformable Video Attention), allowing the adaption of similarity search region to query-specific semantic features, which ensures robust tracking of complex shape and scale changes. DeVOS employs an optical flow to obtain scene motion features which are further injected to deformable attention as strong priors to learnable offsets. Our method achieves top-rank performance on DAVIS 2017 val and test-dev (88.1%, 83.0%), YouTube-VOS 2019 val (86.6%) while featuring consistent run-time speed and stable memory consumption
Global Motion Understanding in Large-Scale Video Object Segmentation
May 11, 2024



In this paper, we show that transferring knowledge from other domains of video understanding combined with large-scale learning can improve robustness of Video Object Segmentation (VOS) under complex circumstances. Namely, we focus on integrating scene global motion knowledge to improve large-scale semi-supervised Video Object Segmentation. Prior works on VOS mostly rely on direct comparison of semantic and contextual features to perform dense matching between current and past frames, passing over actual motion structure. On the other hand, Optical Flow Estimation task aims to approximate the scene motion field, exposing global motion patterns which are typically undiscoverable during all pairs similarity search. We present WarpFormer, an architecture for semi-supervised Video Object Segmentation that exploits existing knowledge in motion understanding to conduct smoother propagation and more accurate matching. Our framework employs a generic pretrained Optical Flow Estimation network whose prediction is used to warp both past frames and instance segmentation masks to the current frame domain. Consequently, warped segmentation masks are refined and fused together aiming to inpaint occluded regions and eliminate artifacts caused by flow field imperfects. Additionally, we employ novel large-scale MOSE 2023 dataset to train model on various complex scenarios. Our method demonstrates strong performance on DAVIS 2016/2017 validation (93.0% and 85.9%), DAVIS 2017 test-dev (80.6%) and YouTube-VOS 2019 validation (83.8%) that is competitive with alternative state-of-the-art methods while using much simpler memory mechanism and instance understanding logic.
Is Mapping Necessary for Realistic PointGoal Navigation?
Jun 07, 2022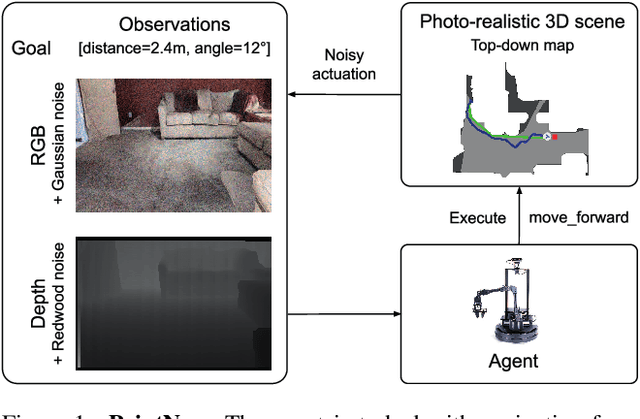
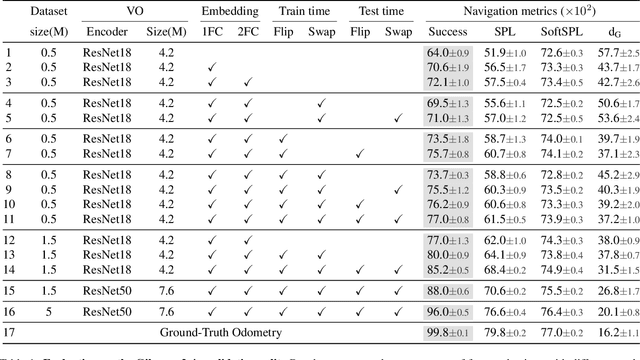
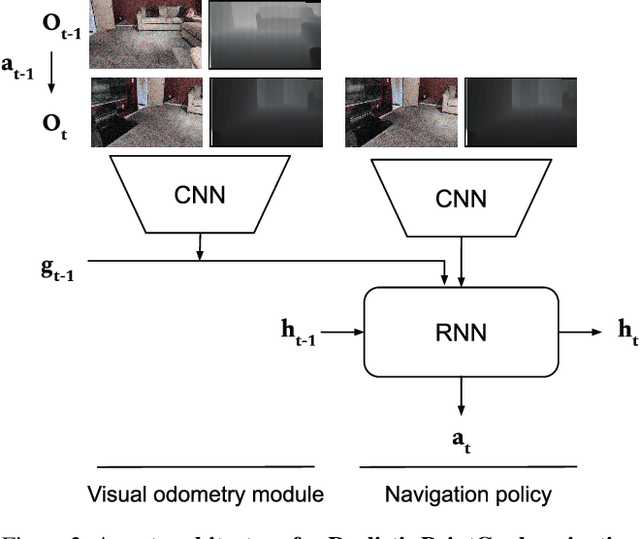
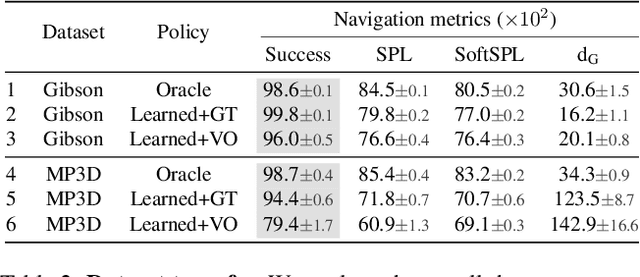
Can an autonomous agent navigate in a new environment without building an explicit map? For the task of PointGoal navigation ('Go to $\Delta x$, $\Delta y$') under idealized settings (no RGB-D and actuation noise, perfect GPS+Compass), the answer is a clear 'yes' - map-less neural models composed of task-agnostic components (CNNs and RNNs) trained with large-scale reinforcement learning achieve 100% Success on a standard dataset (Gibson). However, for PointNav in a realistic setting (RGB-D and actuation noise, no GPS+Compass), this is an open question; one we tackle in this paper. The strongest published result for this task is 71.7% Success. First, we identify the main (perhaps, only) cause of the drop in performance: the absence of GPS+Compass. An agent with perfect GPS+Compass faced with RGB-D sensing and actuation noise achieves 99.8% Success (Gibson-v2 val). This suggests that (to paraphrase a meme) robust visual odometry is all we need for realistic PointNav; if we can achieve that, we can ignore the sensing and actuation noise. With that as our operating hypothesis, we scale the dataset and model size, and develop human-annotation-free data-augmentation techniques to train models for visual odometry. We advance the state of art on the Habitat Realistic PointNav Challenge from 71% to 94% Success (+23, 31% relative) and 53% to 74% SPL (+21, 40% relative). While our approach does not saturate or 'solve' this dataset, this strong improvement combined with promising zero-shot sim2real transfer (to a LoCoBot) provides evidence consistent with the hypothesis that explicit mapping may not be necessary for navigation, even in a realistic setting.
OpenGlue: Open Source Graph Neural Net Based Pipeline for Image Matching
Apr 19, 2022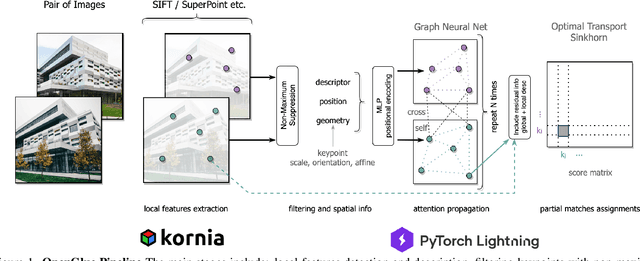
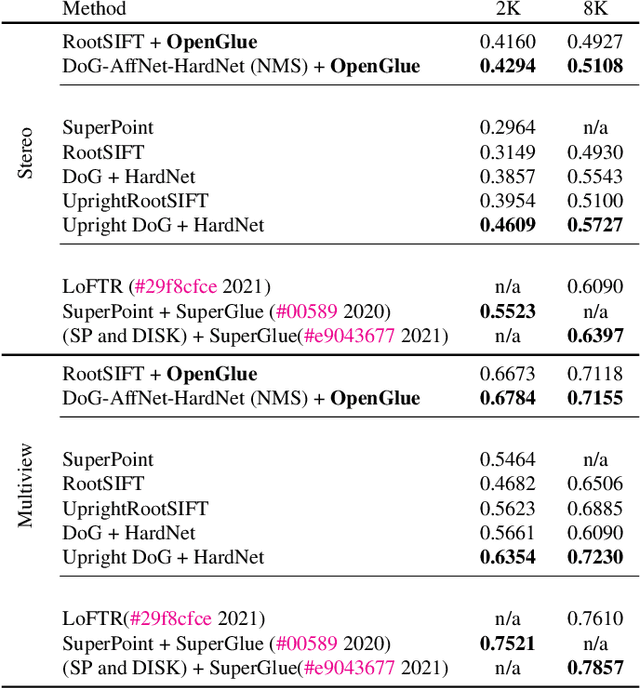
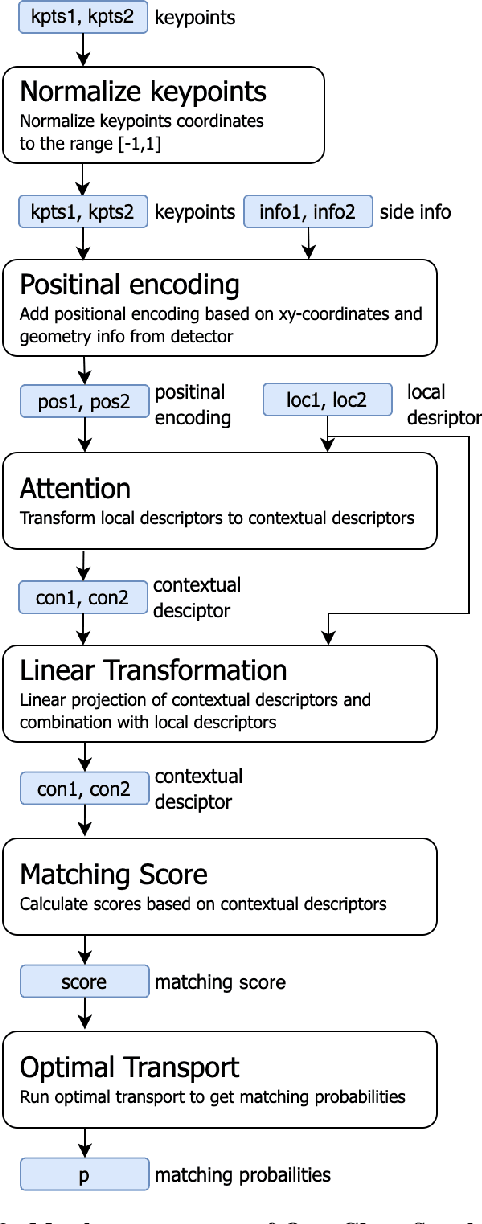
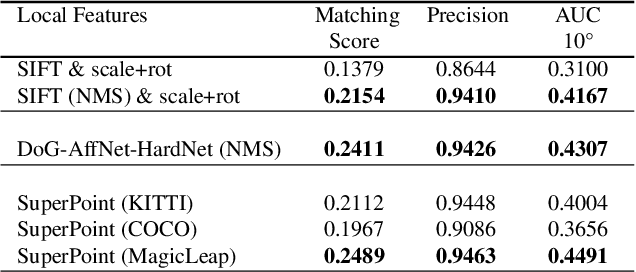
We present OpenGlue: a free open-source framework for image matching, that uses a Graph Neural Network-based matcher inspired by SuperGlue \cite{sarlin20superglue}. We show that including additional geometrical information, such as local feature scale, orientation, and affine geometry, when available (e.g. for SIFT features), significantly improves the performance of the OpenGlue matcher. We study the influence of the various attention mechanisms on accuracy and speed. We also present a simple architectural improvement by combining local descriptors with context-aware descriptors. The code and pretrained OpenGlue models for the different local features are publicly available.
Towards realistic symmetry-based completion of previously unseen point clouds
Jan 05, 2022
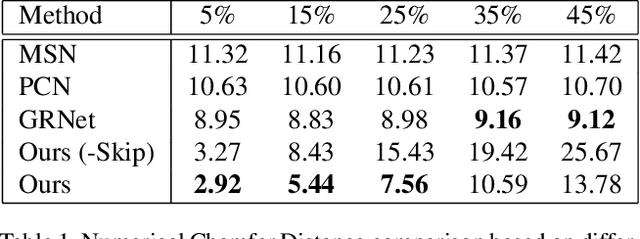
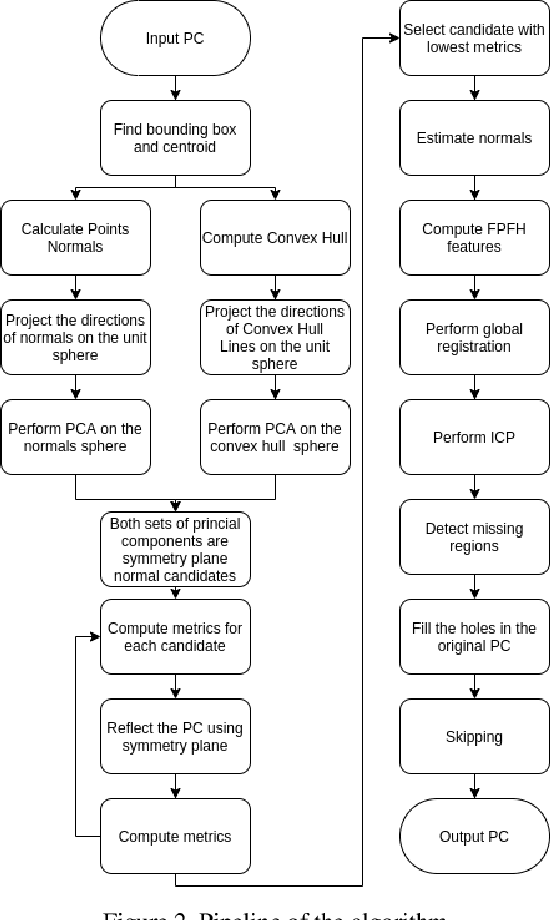

3D scanning is a complex multistage process that generates a point cloud of an object typically containing damaged parts due to occlusions, reflections, shadows, scanner motion, specific properties of the object surface, imperfect reconstruction algorithms, etc. Point cloud completion is specifically designed to fill in the missing parts of the object and obtain its high-quality 3D representation. The existing completion approaches perform well on the academic datasets with a predefined set of object classes and very specific types of defects; however, their performance drops significantly in the real-world settings and degrades even further on previously unseen object classes. We propose a novel framework that performs well on symmetric objects, which are ubiquitous in man-made environments. Unlike learning-based approaches, the proposed framework does not require training data and is capable of completing non-critical damages occurring in customer 3D scanning process using e.g. Kinect, time-of-flight, or structured light scanners. With thorough experiments, we demonstrate that the proposed framework achieves state-of-the-art efficiency in point cloud completion of real-world customer scans. We benchmark the framework performance on two types of datasets: properly augmented existing academic dataset and the actual 3D scans of various objects.
Minimal Solvers for Single-View Lens-Distorted Camera Auto-Calibration
Nov 17, 2020
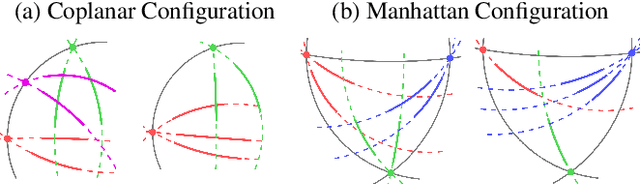

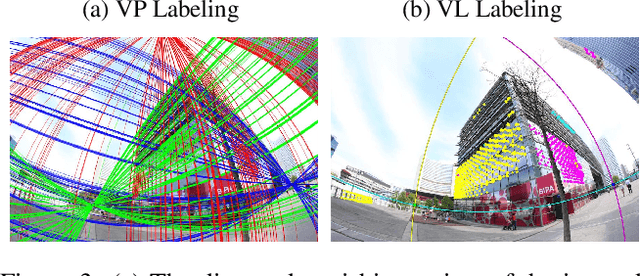
This paper proposes minimal solvers that use combinations of imaged translational symmetries and parallel scene lines to jointly estimate lens undistortion with either affine rectification or focal length and absolute orientation. We use constraints provided by orthogonal scene planes to recover the focal length. We show that solvers using feature combinations can recover more accurate calibrations than solvers using only one feature type on scenes that have a balance of lines and texture. We also show that the proposed solvers are complementary and can be used together in a RANSAC-based estimator to improve auto-calibration accuracy. State-of-the-art performance is demonstrated on a standard dataset of lens-distorted urban images. The code is available at https://github.com/ylochman/single-view-autocalib.
LID 2020: The Learning from Imperfect Data Challenge Results
Oct 17, 2020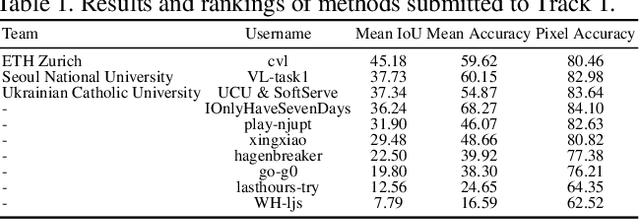
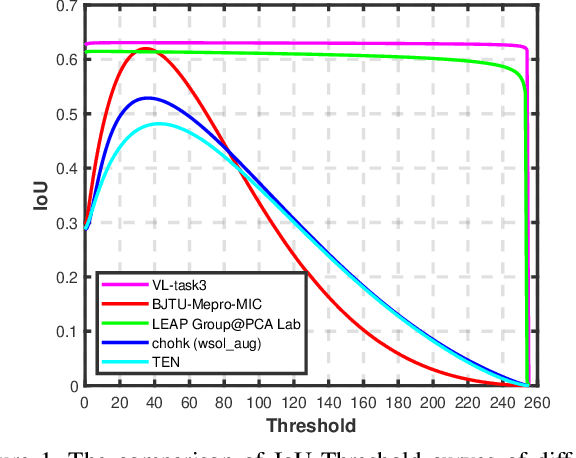

Learning from imperfect data becomes an issue in many industrial applications after the research community has made profound progress in supervised learning from perfectly annotated datasets. The purpose of the Learning from Imperfect Data (LID) workshop is to inspire and facilitate the research in developing novel approaches that would harness the imperfect data and improve the data-efficiency during training. A massive amount of user-generated data nowadays available on multiple internet services. How to leverage those and improve the machine learning models is a high impact problem. We organize the challenges in conjunction with the workshop. The goal of these challenges is to find the state-of-the-art approaches in the weakly supervised learning setting for object detection, semantic segmentation, and scene parsing. There are three tracks in the challenge, i.e., weakly supervised semantic segmentation (Track 1), weakly supervised scene parsing (Track 2), and weakly supervised object localization (Track 3). In Track 1, based on ILSVRC DET, we provide pixel-level annotations of 15K images from 200 categories for evaluation. In Track 2, we provide point-based annotations for the training set of ADE20K. In Track 3, based on ILSVRC CLS-LOC, we provide pixel-level annotations of 44,271 images for evaluation. Besides, we further introduce a new evaluation metric proposed by \cite{zhang2020rethinking}, i.e., IoU curve, to measure the quality of the generated object localization maps. This technical report summarizes the highlights from the challenge. The challenge submission server and the leaderboard will continue to open for the researchers who are interested in it. More details regarding the challenge and the benchmarks are available at https://lidchallenge.github.io
Weakly-Supervised Segmentation for Disease Localization in Chest X-Ray Images
Jul 01, 2020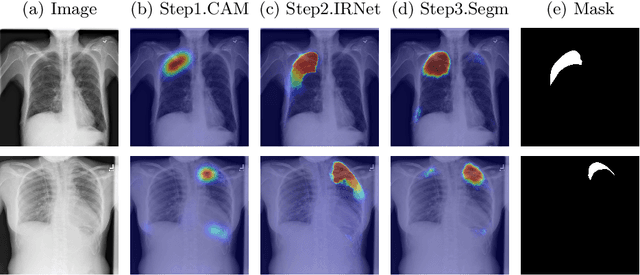

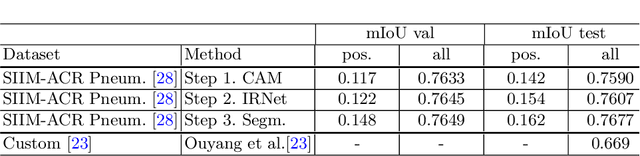
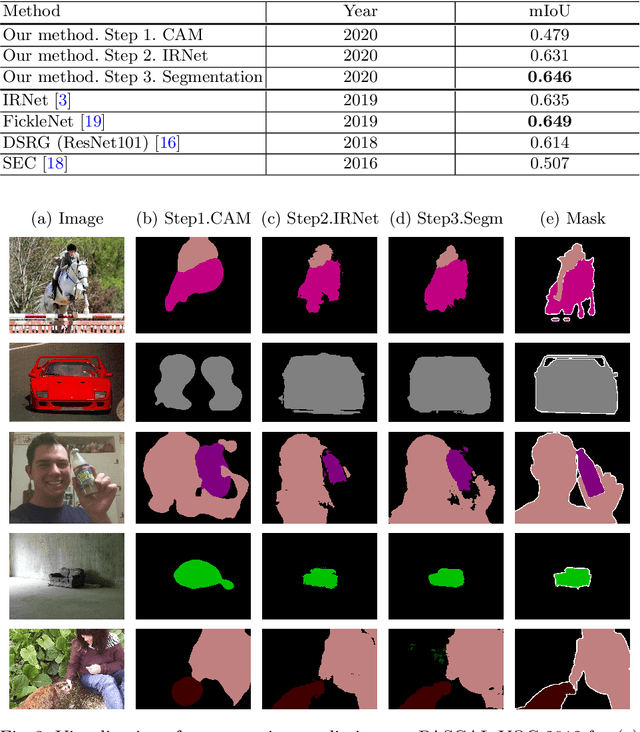
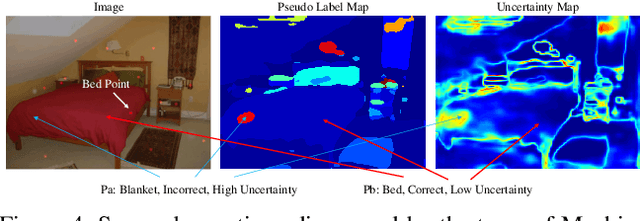
Deep Convolutional Neural Networks have proven effective in solving the task of semantic segmentation. However, their efficiency heavily relies on the pixel-level annotations that are expensive to get and often require domain expertise, especially in medical imaging. Weakly supervised semantic segmentation helps to overcome these issues and also provides explainable deep learning models. In this paper, we propose a novel approach to the semantic segmentation of medical chest X-ray images with only image-level class labels as supervision. We improve the disease localization accuracy by combining three approaches as consecutive steps. First, we generate pseudo segmentation labels of abnormal regions in the training images through a supervised classification model enhanced with a regularization procedure. The obtained activation maps are then post-processed and propagated into a second classification model-Inter-pixel Relation Network, which improves the boundaries between different object classes. Finally, the resulting pseudo-labels are used to train a proposed fully supervised segmentation model. We analyze the robustness of the presented method and test its performance on two distinct datasets: PASCAL VOC 2012 and SIIM-ACR Pneumothorax. We achieve significant results in the segmentation on both datasets using only image-level annotations. We show that this approach is applicable to chest X-rays for detecting an anomalous volume of air in the pleural space between the lung and the chest wall. Our code has been made publicly available.
NoPeopleAllowed: The Three-Step Approach to Weakly Supervised Semantic Segmentation
Jun 13, 2020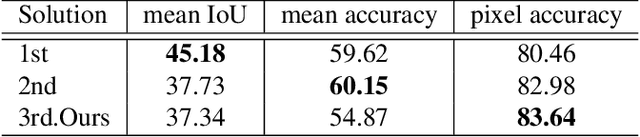


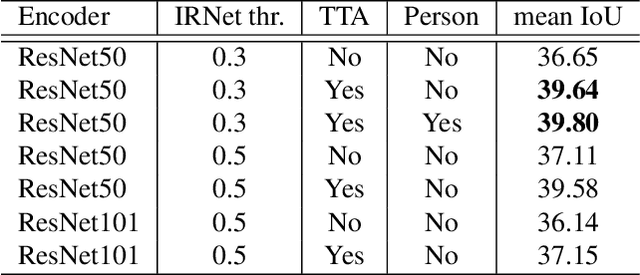
We propose a novel approach to weakly supervised semantic segmentation, which consists of three consecutive steps. The first two steps extract high-quality pseudo masks from image-level annotated data, which are then used to train a segmentation model on the third step. The presented approach also addresses two problems in the data: class imbalance and missing labels. Using only image-level annotations as supervision, our method is capable of segmenting various classes and complex objects. It achieves 37.34 mean IoU on the test set, placing 3rd at the LID Challenge in the task of weakly supervised semantic segmentation.
CNN-CASS: CNN for Classification of Coronary Artery Stenosis Score in MPR Images
Jan 23, 2020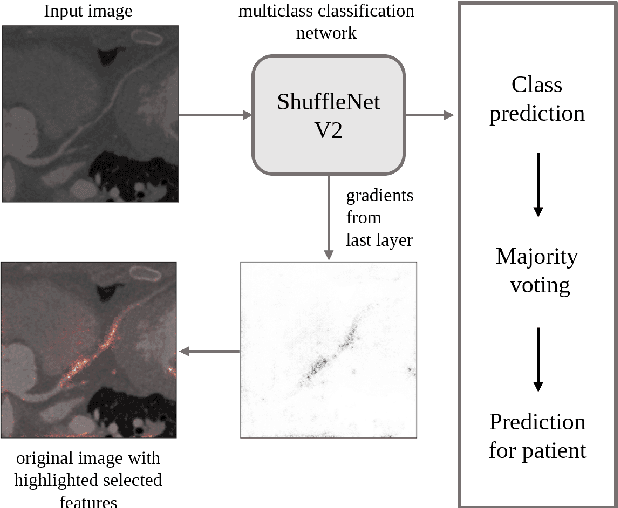
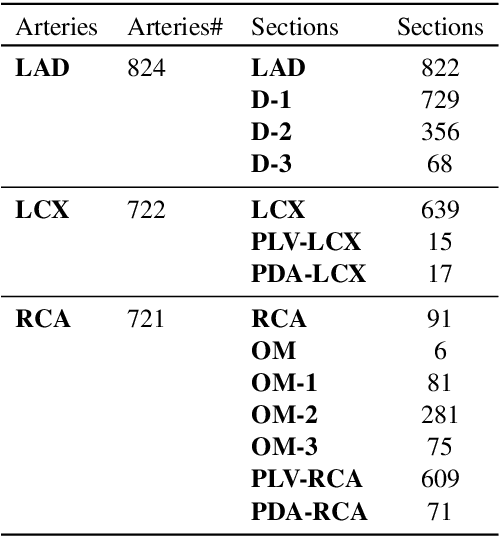


To decrease patient waiting time for diagnosis of the Coronary Artery Disease, automatic methods are applied to identify its severity using Coronary Computed Tomography Angiography scans or extracted Multiplanar Reconstruction (MPR) images, giving doctors a second-opinion on the priority of each case. The main disadvantage of previous studies is the lack of large set of data that could guarantee their reliability. Another limitation is the usage of handcrafted features requiring manual preprocessing, such as centerline extraction. We overcome both limitations by applying a different automated approach based on ShuffleNet V2 network architecture and testing it on the proposed collected dataset of MPR images, which is bigger than any other used in this field before. We also omit centerline extraction step and train and test our model using whole curved MPR images of 708 and 105 patients, respectively. The model predicts one of three classes: 'no stenosis' for normal, 'non-significant' - 1-50% of stenosis detected, 'significant' - more than 50% of stenosis. We demonstrate model's interpretability through visualization of the most important features selected by the network. For stenosis score classification, the method shows improved performance comparing to previous works, achieving 80% accuracy on the patient level. Our code is publicly available.