 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards realistic symmetry-based completion of previously unseen point clouds
Jan 05, 2022
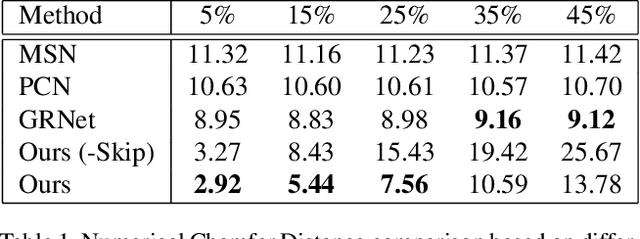
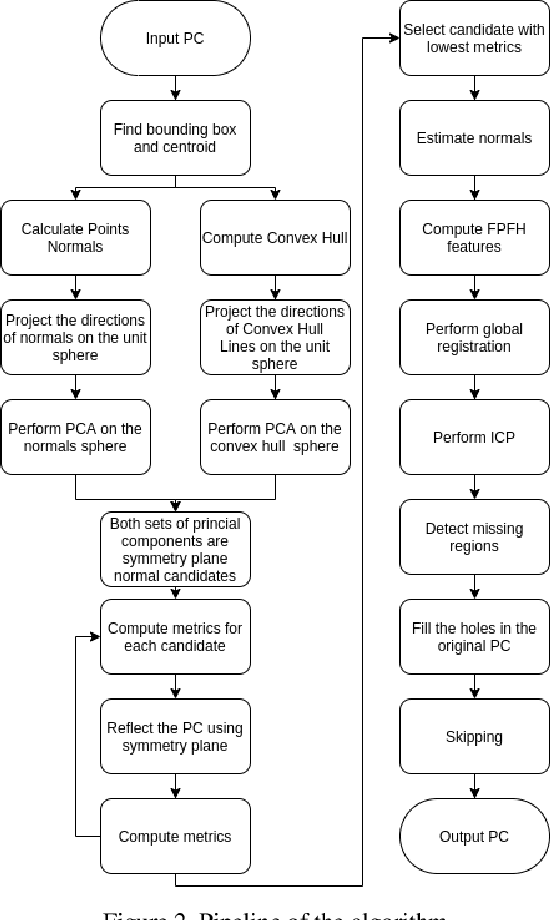

3D scanning is a complex multistage process that generates a point cloud of an object typically containing damaged parts due to occlusions, reflections, shadows, scanner motion, specific properties of the object surface, imperfect reconstruction algorithms, etc. Point cloud completion is specifically designed to fill in the missing parts of the object and obtain its high-quality 3D representation. The existing completion approaches perform well on the academic datasets with a predefined set of object classes and very specific types of defects; however, their performance drops significantly in the real-world settings and degrades even further on previously unseen object classes. We propose a novel framework that performs well on symmetric objects, which are ubiquitous in man-made environments. Unlike learning-based approaches, the proposed framework does not require training data and is capable of completing non-critical damages occurring in customer 3D scanning process using e.g. Kinect, time-of-flight, or structured light scanners. With thorough experiments, we demonstrate that the proposed framework achieves state-of-the-art efficiency in point cloud completion of real-world customer scans. We benchmark the framework performance on two types of datasets: properly augmented existing academic dataset and the actual 3D scans of various objects.
ActGAN: Flexible and Efficient One-shot Face Reenactment
Mar 30, 2020
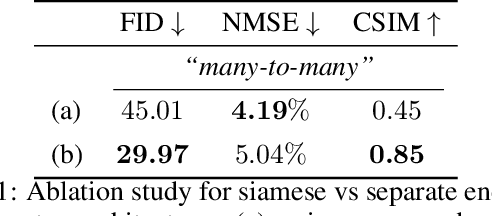
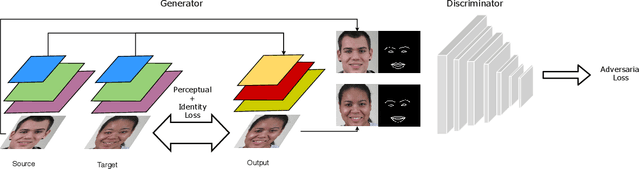

This paper introduces ActGAN - a novel end-to-end generative adversarial network (GAN) for one-shot face reenactment. Given two images, the goal is to transfer the facial expression of the source actor onto a target person in a photo-realistic fashion. While existing methods require target identity to be predefined, we address this problem by introducing a "many-to-many" approach, which allows arbitrary persons both for source and target without additional retraining. To this end, we employ the Feature Pyramid Network (FPN) as a core generator building block - the first application of FPN in face reenactment, producing finer results. We also introduce a solution to preserve a person's identity between synthesized and target person by adopting the state-of-the-art approach in deep face recognition domain. The architecture readily supports reenactment in different scenarios: "many-to-many", "one-to-one", "one-to-another" in terms of expression accuracy, identity preservation, and overall image quality. We demonstrate that ActGAN achieves competitive performance against recent works concerning visual quality.
Training Deep Neural Networks by optimizing over nonlocal paths in hyperparameter space
Sep 09, 2019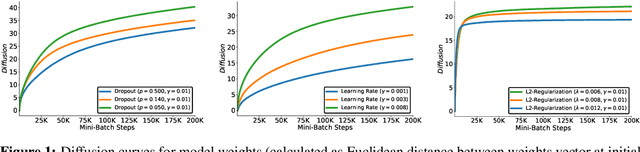
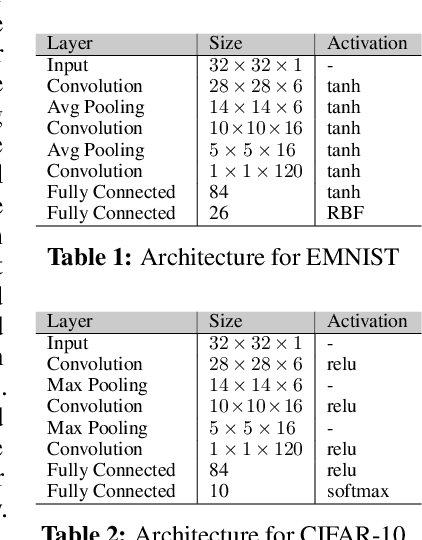
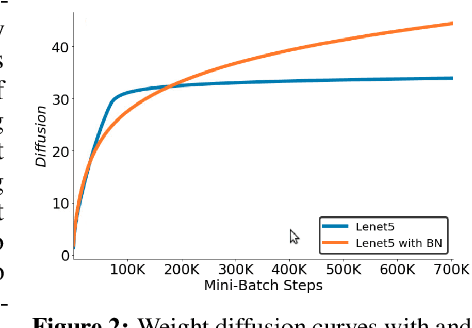
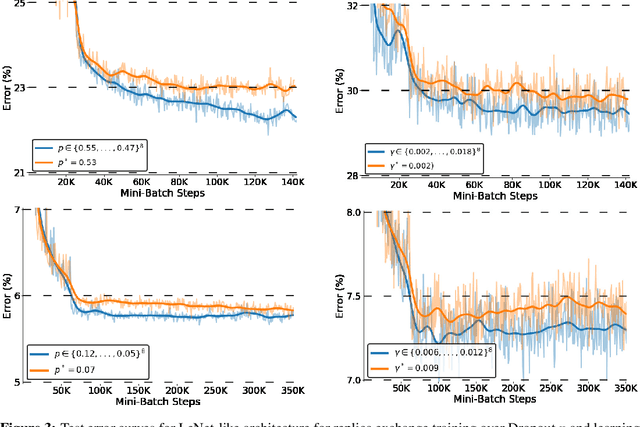
Hyperparameter optimization is both a practical issue and an interesting theoretical problem in training of deep architectures. Despite many recent advances the most commonly used methods almost universally involve training multiple and decoupled copies of the model, in effect sampling the hyperparameter space. We show that at a negligible additional computational cost, results can be improved by sampling nonlocal paths instead of points in hyperparameter space. To this end we interpret hyperparameters as controlling the level of correlated noise in training, which can be mapped to an effective temperature. The usually independent instances of the model are coupled and allowed to exchange their hyperparameters throughout the training using the well established parallel tempering technique of statistical physics. Each simulation corresponds then to a unique path, or history, in the joint hyperparameter/model-parameter space. We provide empirical tests of our method, in particular for dropout and learning rate optimization. We observed faster training and improved resistance to overfitting and showed a systematic decrease in the absolute validation error, improving over benchmark results.