 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritic-Guided Reinforcement Unlearning in Text-to-Image Diffusion
Jan 06, 2026Machine unlearning in text-to-image diffusion models aims to remove targeted concepts while preserving overall utility. Prior diffusion unlearning methods typically rely on supervised weight edits or global penalties; reinforcement-learning (RL) approaches, while flexible, often optimize sparse end-of-trajectory rewards, yielding high-variance updates and weak credit assignment. We present a general RL framework for diffusion unlearning that treats denoising as a sequential decision process and introduces a timestep-aware critic with noisy-step rewards. Concretely, we train a CLIP-based reward predictor on noisy latents and use its per-step signal to compute advantage estimates for policy-gradient updates of the reverse diffusion kernel. Our algorithm is simple to implement, supports off-policy reuse, and plugs into standard text-to-image backbones. Across multiple concepts, the method achieves better or comparable forgetting to strong baselines while maintaining image quality and benign prompt fidelity; ablations show that (i) per-step critics and (ii) noisy-conditioned rewards are key to stability and effectiveness. We release code and evaluation scripts to facilitate reproducibility and future research on RL-based diffusion unlearning.
Towards realistic symmetry-based completion of previously unseen point clouds
Jan 05, 2022
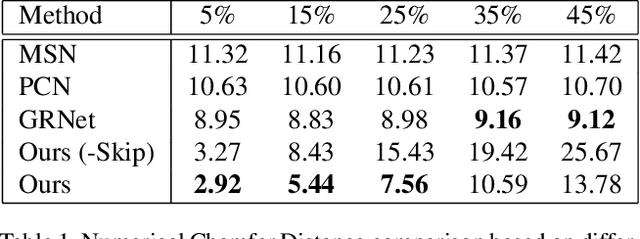
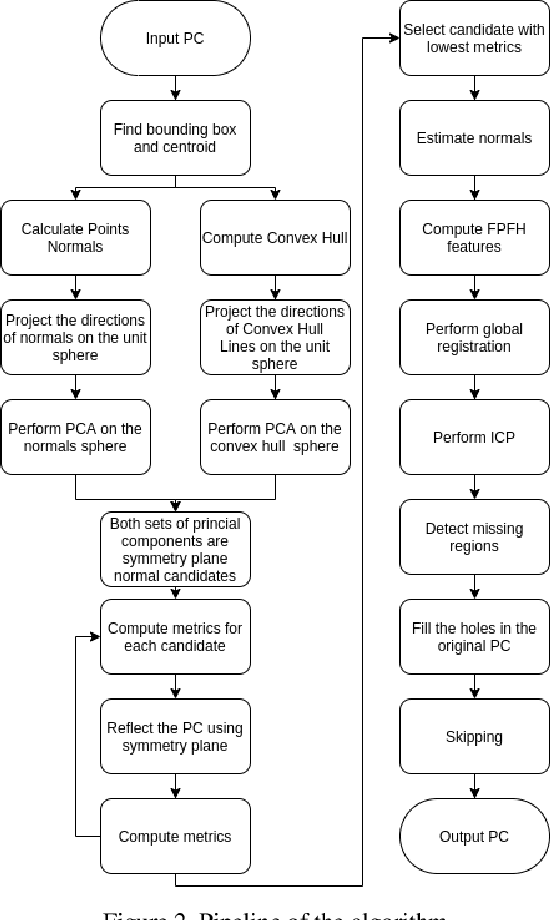

3D scanning is a complex multistage process that generates a point cloud of an object typically containing damaged parts due to occlusions, reflections, shadows, scanner motion, specific properties of the object surface, imperfect reconstruction algorithms, etc. Point cloud completion is specifically designed to fill in the missing parts of the object and obtain its high-quality 3D representation. The existing completion approaches perform well on the academic datasets with a predefined set of object classes and very specific types of defects; however, their performance drops significantly in the real-world settings and degrades even further on previously unseen object classes. We propose a novel framework that performs well on symmetric objects, which are ubiquitous in man-made environments. Unlike learning-based approaches, the proposed framework does not require training data and is capable of completing non-critical damages occurring in customer 3D scanning process using e.g. Kinect, time-of-flight, or structured light scanners. With thorough experiments, we demonstrate that the proposed framework achieves state-of-the-art efficiency in point cloud completion of real-world customer scans. We benchmark the framework performance on two types of datasets: properly augmented existing academic dataset and the actual 3D scans of various objects.