 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActGAN: Flexible and Efficient One-shot Face Reenactment
Mar 30, 2020
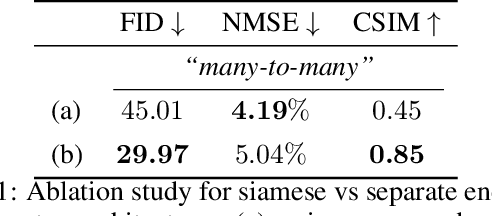
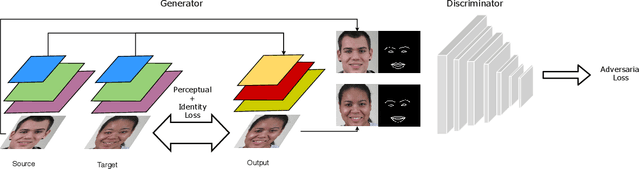

This paper introduces ActGAN - a novel end-to-end generative adversarial network (GAN) for one-shot face reenactment. Given two images, the goal is to transfer the facial expression of the source actor onto a target person in a photo-realistic fashion. While existing methods require target identity to be predefined, we address this problem by introducing a "many-to-many" approach, which allows arbitrary persons both for source and target without additional retraining. To this end, we employ the Feature Pyramid Network (FPN) as a core generator building block - the first application of FPN in face reenactment, producing finer results. We also introduce a solution to preserve a person's identity between synthesized and target person by adopting the state-of-the-art approach in deep face recognition domain. The architecture readily supports reenactment in different scenarios: "many-to-many", "one-to-one", "one-to-another" in terms of expression accuracy, identity preservation, and overall image quality. We demonstrate that ActGAN achieves competitive performance against recent works concerning visual quality.
DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks
Apr 03, 2018



We present DeblurGAN, an end-to-end learned method for motion deblurring. The learning is based on a conditional GAN and the content loss . DeblurGAN achieves state-of-the art performance both in the structural similarity measure and visual appearance. The quality of the deblurring model is also evaluated in a novel way on a real-world problem -- object detection on (de-)blurred images. The method is 5 times faster than the closest competitor -- DeepDeblur. We also introduce a novel method for generating synthetic motion blurred images from sharp ones, allowing realistic dataset augmentation. The model, code and the dataset are available at https://github.com/KupynOrest/DeblurGAN